SQL*Loaderを使えるようになると、高速に大量のデータをテーブルに格納できるようになります。ここではSQL*Loaderの使い方といくつかのオプション・コマンドをご紹介します。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890646.png)
SQL*Loaderとは?
SQL*Loaderは大量のデータを高速にテーブルへ格納するためのOracle Database付属ツールです。
CSVファイルを元にまとめてデータを取り込むことができます。ダイレクト・パス・インサート方式(通常のINSERTの場合に通るデータベースバッファを経由せず、直接テーブルにレコードを書き込む登録方法です)を採用していることから、1行1行INSERT文を発行せずに済み、高速に処理できることが特長です。データを格納するので、数百万件単位のデータでも数分しかかかりません。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890818.png)
SQL*Loaderの使い方
ではSQL*Loaderの使い方を見ていきましょう。今回は次のテーブルにデータを作成します。
CREATE TABLE DEPARTMENT (
ID NUMBER PRIMARY KEY,
NAME VARCHAR2(50) NOT NULL
);
部署コードと部署名を対で保持するための単純なテーブルです。
SQL*Loaderではデータの核となるCSVファイルと、それをどうテーブルに落とし込むのかを決定する制御ファイルを作成します。
制御ファイルの作成
まず制御ファイルから作成していきましょう。制御ファイルの役割は投入元のCSVファイルと投入先のテーブルのマッピングです。また、どういったルールで投入するのかも制御ファイル内に記載します。
LOAD DATA
INFILE 'department.csv'
BADFILE 'department.bad'
APPEND
INTO TABLE DEPARTMENT
FIELDS TERMINATED BY ","
TRAILING NULLCOLS
(
ID,
NAME
)
制御ファイルの拡張子は通常はctlが使われますが、txt等の拡張子でも問題ありません。一番下の丸カッコの中にテーブルのカラム名を指定します。
また、いろいろなオプションが用意されています。各オプションの意味はこちらです。
| オプション | 説明 |
| LOAD DATA | 新規のロードが開始される位置を表します |
| INFILE | 取り込むデータファイルのパスを指定します(主にCSV) |
| BADFILE | エラーが発生し、取り込めなかったデータを格納するファイルです |
| APPEND | 行の追加を表すオプションで、テーブルに既存の行がある場合、新しい行としてデータを取り込みます。 |
| INTO TABLE | データの取り込み先テーブルを指定します。 |
| FIELDS TERMINATED BY | データの区切り文字を指定します(CSVの場合は”,”) |
| TRAILING NULLCOLS | データの不足が合った場合はNULLで補完します。 |
CSVファイルの作成
次に、CSVファイルを作成します。CSVファイルとはカンマ(,)で区切られたデータのことです。今回はサンプルとして以下のデータを持つ「department.csv」というファイルを作成します。
0,企画部
1,営業部
2,開発部
実行
ではSQL*Loaderでデータを取り込んでみましょう。
SQL*Loaderはユーティリティツールなので、コンソールやコマンドプロンプトから実行可能です。制御ファイルがあるところまでcdで移動し、次のコマンドを実行します。
sqlldr system/[パスワード]@XE control=department.ctl
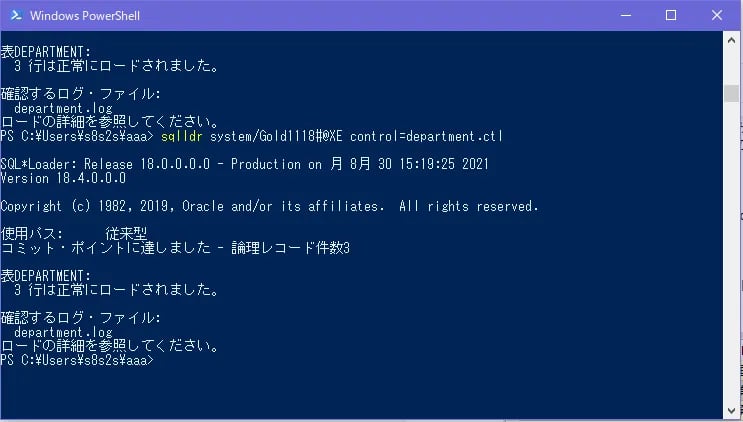
終わったら結果を見てみましょう。部署テーブルを開きます。

SQL*Loaderを使ってデータを格納できました。
SQL*Loaderを起動させるとログファイルを出力します。忘れずに確認しましょう。
ログファイルには取り込み先のテーブル名やカラム名、正常にロードされた件数、エラーが発生した件数などが表示されます。
今回は3件のデータを取り込んだのがログからも確認できました。
CSVにヘッダを付けたい場合
CSVにヘッダを付けたい場合、1行目の読み込み処理をスキップする必要があります。
この場合はOPTIONSのSKIPに1を指定することでスキップできます。
OPTIONS(SKIP=1)
LOAD DATA
以下略
department.csv:
ID,NAME
0,企画部
1,営業部
2,開発部
このファイルでSQL*Loaderを実行した結果が以下です。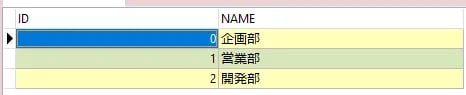

BADFILEについて
SQL*Loaderでは正常に読み込めなかったデータはBADFILEで指定したファイルに出力されます。
BADFILEを参照することで何行目のデータに不備があるのかを判断できるので、実際にSQL*Loaderを使う場合はBADFILEが出力されていないかも確認しましょう。
BADFILEを出力してみましょう。営業部のレコードのみ部署テーブルに残した状態で実行すると結果は以下のようになります。

企画部と開発部のレコードが作成され、営業部のレコードは1件のみ格納されます。

ログを見てみましょう。
「1 行はデータ・エラーのためロードされませんでした」とあります。こうなった場合にBADFILEを確認しましょう。
制御ファイルと同じ階層にあるdepartment.badをメモ帳等で開きます。
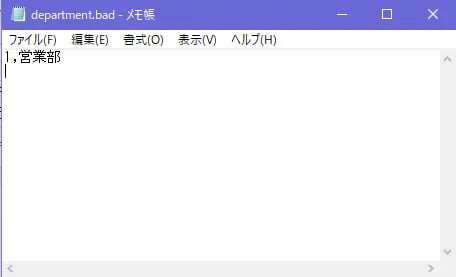 営業部の行の情報が出力されているのが分かります。
営業部の行の情報が出力されているのが分かります。
SQL*Loaderのコマンドライン・パラメータ
ここからはいくつか主要なコマンドライン・パラメータについてご紹介します。
LOG
実行時ログを出力するログファイル名を指定できます。
コマンド:
sqlldr system/[パスワード]@XE control=department.ctl log=dept.log
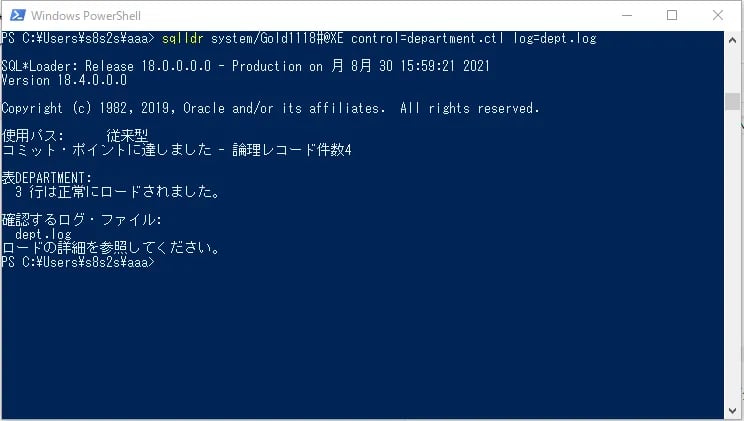
確認するログ・ファイルが「dept.log」になっています。
ERRORS
許容される最大エラー行数を指定するパラメータです。
これ以上エラーが発生すると、それ以降のデータのデータ取り込みが全て拒否されます。
試しにerrors=2を指定し、3行以上のエラーが発生するCSVファイルで実行してみましょう。
ID,NAME
0,企画部
0,企画部
1,営業部
1,営業部
2,開発部
2,開発部
3,人事部
4,経理部
IDは主キーなので、2つ目の開発部の時点で3行目のエラーになります。
コマンド:
sqlldr system/Gold1118#@XE control=department.ctl errors=2
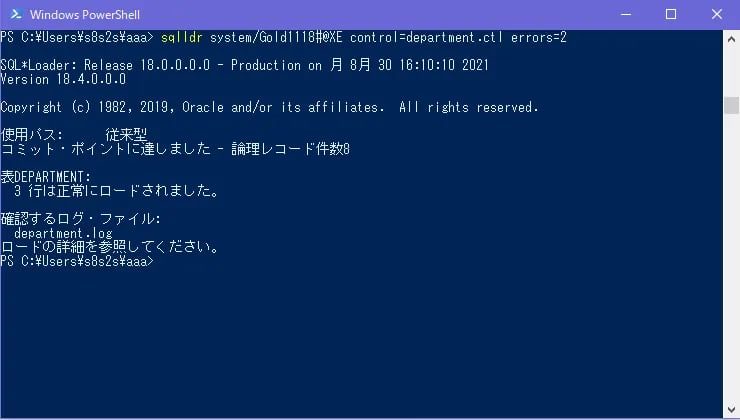
3行は正常にロードされました。3つ目のエラー行までの正常に取り込めるデータは取り込まれます。一方でそれ以降のデータ(人事部、経理部)は取り込まれていないのが分かります。
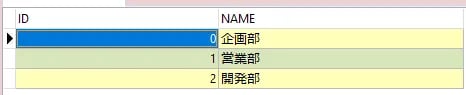
ログファイルを見てみましょう。

「最大エラー件数を超えました - 上の統計が不完全な実行に影響しています」と出力されているのが分かります。
ROWS
何行目でコミットするかのコミットタイミングを決めるパラメータです。ROWSを大きくすればするほど大量のデータを高速に取り込めます。
反面バッファを大きく消費するので、ROWSの数を大きくする場合はREADSIZEとBINDSIZEの値も大きくする必要があります。
ROWSの値を小さくするとデータ取り込みに時間が掛かるようになりますが、バッファも小さくできるので少ないメモリ容量で取り込み処理が可能です。
まとめ
以上でSQL*Loaderの基本的な使い方をご紹介しました。特に大量のデータを素早く取り込みたいときは通常のSQLでデータを作成するよりも高速に取り込めるため、データベース移行のシーンで活用できます。ぜひ活用いただけたらと思います。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890651.png)








![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890654.png)