![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890646.png)
Oracle パーティション検証完結編
今回で3回目となるパーティションの検証です。
前回の「Oracle RANGE PARTITIONの効果を検証する」では、ユーザーリクエストによるインデックスとのパフォーマンス比較を実施し、インデックスの前に敗北を喫したパーティションですが、今回は果たして勝利することができるのでしょうか?
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890818.png)
Oracleのパーティションとは?
前回の検証から一年と少し経過しておりますので、ここでOracleのパーティションについておさらいしておきましょう。おおまかな特徴は以下の通りです。
・データをある種別ごとにパーティション化(分類わけ)できる
・テーブルデータ全体から検索するより、パーティション化した一部のデータを参照できるので検索速度が速い
・パーティション機能が実行されるには、SELEC時にパーティションキーカラムをWhere句に指定する必要がある
いくつかの種類があり、用途によって使い分けます。
|
種類 |
概要 |
使用例 |
|
レンジ・パーティション |
パーティションキーの値の範囲で分割。日付ごとに区切ることが多い。 |
年間売り上げデータを月ごとにパーティション化する。 |
|
リスト・パーティション |
関連性のない不連続なデータを指定。任意に区切る場合に使用。 |
年間売り上げデータを各地方ごとに集計する場合など。関東ならパーティションに東京・神奈川・埼玉・千葉・群馬・茨城・栃木を指定 |
|
ハッシュ・パーティション |
上記のように明示的にパーティション化できない場合に指定。 |
|
|
コンポジット・パーティション |
上記を組み合わせた指定方法。 |
より細やかなパーティション化を実行したいとき。 |
リスト・パーティションで検証
前回、前々回(Oracle PARTITIONの効果を検証する)はレンジ・パーティションを採用しましたが、今回はリスト・パーティションを用いてパーティション化します。同様のデータを持つテーブルをもう一つ作り、こちらはインデックスを設定してパフォーマンスを比較していきます。
詳細は以下の通り。
・関東地方一都六県を設定したカラムを持ったサンプルテーブルに1000万件のデータを作成
・公正を保つため、データごとテーブルをコピーする
・県名を格納したカラムでリスト・パーティションを構成し、パーティション化する。
・片方は県名を格納したカラムにインデックスを付加する。
・SQLを実行し、指定した県名の件数を集計。そのレスポンスを測定。
・SQL実行前にキャッシュをクリアし、その後各テーブルで5回処理を行う。
※5回実行する間、キャッシュクリアは行わない。中間値を採用する。
<検証環境>
今回の検証環境は以下の通りです。前回から一年ほど経過しておりますので、少しだけ環境もパワーアップしております。
|
マシン情報 |
OS |
Windows10 |
|
CPU |
Intel Core i7-6500U 2.50GHz |
|
|
メモリ |
16GB |
|
|
その他 |
特に無し |
|
|
DB |
対象RDBMS |
Oracle12.2.0.1.0 |
サンプルテーブル(TEST_PART,TEST_INDEX)
|
項目名 |
データ型 |
備考 |
|
CODE |
NUMBER(10) |
主キー |
|
NAME |
VARCHAR2(40) |
|
|
ADD1 |
VARCHAR2(50) |
パーティション、またはインデックスを設定 |
|
TEL |
VARCHAR2(20) |
|
|
UPDATE |
DATE |
|
<検証準備>
毎度おなじみのデータ生成機能を使用し、データを1000万件投入します。
|
カラム名 |
データ生成方法 |
|
CODE |
連番。1から開始し1ずつカウントアップ |
|
NAME |
テンプレート 苗字 + 名前 |
|
ADD1 |
選択値「東京、神奈川、埼玉、千葉、茨城、群馬、栃木」 |
|
TEL |
乱数値 電話番号 |
|
UPDDATE |
乱数値 日時(時間はセットしない) 2017/01/01から2017/12/31の間で ランダムに生成 |
ADD1には、「選択値」を設定しました。これは、あらかじめ記述した文字リストの中から均等に値を選択していく設定となります。
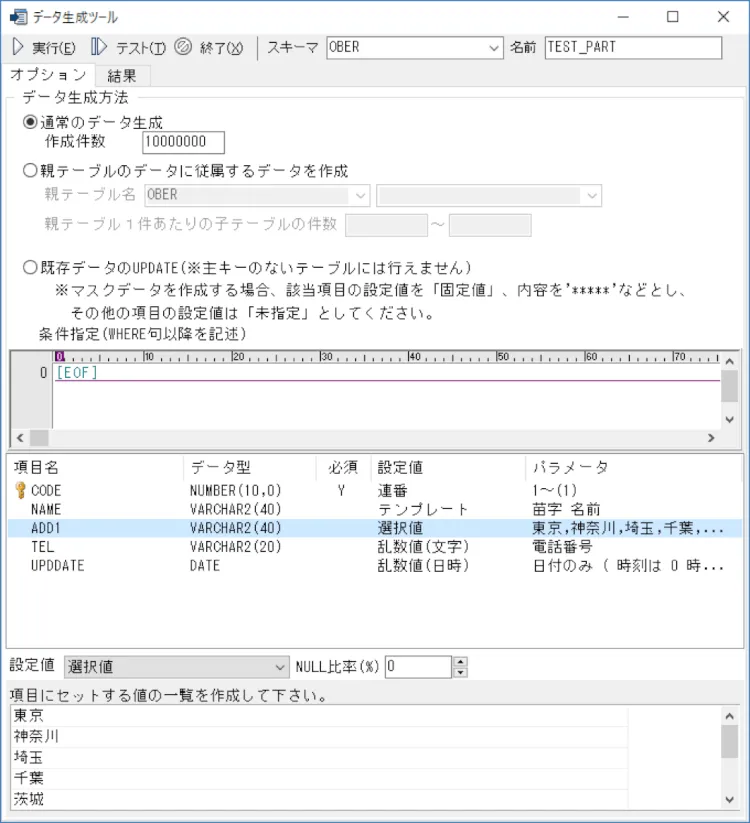
TEST_PARTはパーティション化の処理を行います。ObjectBrowserで下記のように設定します。
今回は「pt_kita」「pt_minami」として、北関東、南関東で分割してみました。
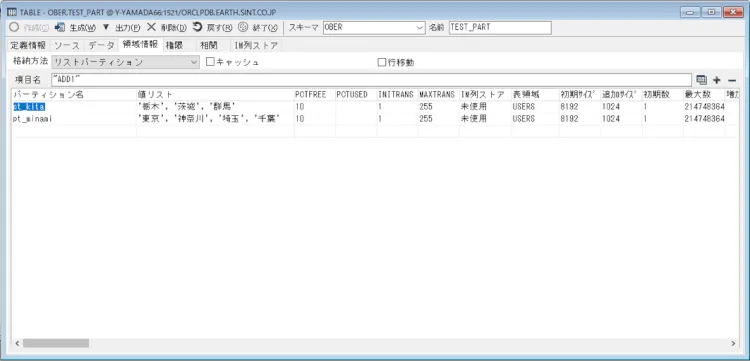
ソースは以下の通りです。
|
CREATE TABLE "OBER"."TEST_PART" ( "CODE" NUMBER(10,0) NOT NULL, "NAME" VARCHAR2(40), "ADD1" VARCHAR2(40), "TEL" VARCHAR2(20), "UPDDATE " DATE, CONSTRAINT "PK_TEST_PART" PRIMARY KEY ("CODE") USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 64K NEXT 1M MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT) LOGGING ENABLE ) NOCACHE PARTITION BY LIST("ADD1") ( PARTITION "pt_kita" VALUES ('栃木', '茨城', '群馬') NO INMEMORY PCTFREE 10 INITRANS 1 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 8192K NEXT 1024K MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT), PARTITION "pt_minami" VALUES ('東京', '神奈川', '埼玉', '千葉') NO INMEMORY PCTFREE 10 INITRANS 1 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 8192K NEXT 1024K MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT) ) |
TEST_INDEXのほうには、ADD1にインデックスを付加します。
|
CREATE INDEX "OBER"."IDX_TEST" ON "OBER"."TEST_INDEX" ("ADD1") PCTFREE 10 INITRANS 2 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 64K NEXT 1M MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT) LOGGING VISIBLE / |
これで準備完了です。 [RELATED_POSTS]
パーティション勝利なるか? 検証結果
各テーブルから、「埼玉」のデータ件数を下記SQLで抽出します。
|
SELECT COUNT(ADD1) FROM <テーブル名> WHERE ADD1 = ‘埼玉’ |
では早速検証に入りましょう。比較のため、パーティション化もインデックス付加もしていないものも用意しましたので、あわせてどうぞ。
|
付加状況 |
1回目 |
2回目 |
3回目 |
4回目 |
5回目 |
|
パーティション |
1.748 |
0.267 |
0.266 |
0.387 |
0.264 |
|
インデックス |
1.128 |
0.102 |
0.106 |
0.104 |
0.107 |
|
なし |
1.832 |
1.233 |
1.220 |
1.234 |
1.230 |
※単位:秒 対象件数は 1,429,585
結果はまたもインデックスの勝利です。パーティションはキャッシュ未発生だと通常テーブルとあまり変わりませんね。
パーティションが勝つまでやる! 追加検証
ここまできたら勝つまでやりたくなってきました。次は、さらにパーティションを細かく設定します。
南関東(pt_minami)、北関東(pt_kita)として作成したリストパーティションをいったん削除し、県名単位でリストパーティションを再設定します。
|
NOCACHE PARTITION BY LIST("ADD1") ( PARTITION "pt_tokyo" VALUES ('東京') NO INMEMORY PCTFREE 10 INITRANS 1 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 8192K NEXT 1024K MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT), PARTITION "pt_saitama" VALUES ('埼玉') NO INMEMORY PCTFREE 10 INITRANS 1 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 8192K NEXT 1024K MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT), PARTITION "pt_kanagawa" VALUES ('神奈川') NO INMEMORY PCTFREE 10 INITRANS 1 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 8192K NEXT 1024K MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT), PARTITION "pt_chiba" VALUES ('千葉') NO INMEMORY PCTFREE 10 INITRANS 1 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 8192K NEXT 1024K MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT), PARTITION "pt_ibaraki" VALUES ('茨城') NO INMEMORY PCTFREE 10 INITRANS 1 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 8192K NEXT 1024K MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT), PARTITION "pt_tochigi" VALUES ('栃木') NO INMEMORY PCTFREE 10 INITRANS 1 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 8192K NEXT 1024K MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT), PARTITION "pt_gunma" VALUES ('群馬') NO INMEMORY PCTFREE 10 INITRANS 1 MAXTRANS 255 TABLESPACE "USERS" STORAGE(INITIAL 8192K NEXT 1024K MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT) ) |
|
付加状況 |
1回目 |
2回目 |
3回目 |
4回目 |
5回目 |
|
パーティション |
0.373 |
0.047 |
0.044 |
0.040 |
0.050 |
|
インデックス(前回) |
1.128 |
0.102 |
0.106 |
0.104 |
0.107 |
|
なし(前回) |
1.832 |
1.233 |
1.220 |
1.234 |
1.230 |
※単位:秒 対象件数は 1,429,585
・・・ついにインデックスを上回りました!しかも今回最速の数値です。
パーティションの性質上、細かくパーティション化すれば参照するデータ量が少なくて済むので、当然といえば当然の結果といえるかもしれません。
では、Where句を下記のように変更し、すべてのデータが対象になるようにして比較します。
|
where add1 in('埼玉','東京','神奈川','千葉','茨城','栃木','群馬') |
|
付加状況 |
1回目 |
2回目 |
3回目 |
4回目 |
5回目 |
|
パーティション |
2.188 |
0.291 |
0.294 |
0.297 |
0.295 |
|
インデックス |
1.446 |
0.843 |
0.838 |
0.880 |
0.835 |
|
なし |
1.933 |
1.268 |
1.295 |
1.272 |
1.264 |
※単位:秒 対象件数は 10,000,000
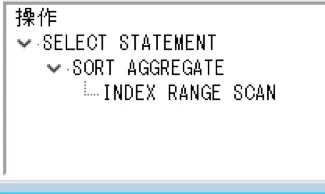
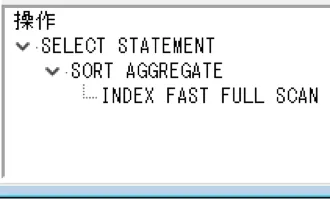
このケースもパーティションが最速となりました。パーティションが約7倍の時間がかかったのに対して、インデックスは約8倍の時間が必要となってしまいました。(データ量は約7倍増)インデックスを付加したテーブルの実行計画を確認してみると、RANGE SCAN から FAST FULL SCANに変化していることがわかります。
・Where add1 = ‘埼玉’
・where add1 in('埼玉','東京','神奈川','千葉','茨城','栃木','群馬')
Oracleパーティション検証完結編 結論
今回の検証では、やっとパーティションがインデックスのパフォーマンスを上回るケースを紹介することができました。前々回の検証で推測していましたが、細かいパーティショニングは効果が高いようです。ただ、一つのパーティション内のデータ量が多いケースではインデックスのほうが速かったように、データ量やデータ種類の偏り等も考慮しなければなりません。
該当テーブルのデータがどのような方法で検索されるのか、またどんな割合でデータが投入されるかを予測し、適切なテーブル設計を行う必要がありそうです。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890651.png)








