「クエリのパフォーマンスを向上させるにはインデックスの作成が効果的である」という対策は、パフォーマンスチューニングを行う段階で必ず候補となる対策手段の一つです。これまでに公開した、「インデックスの作成でSELECT文の返答時間はどれくらい早くなるのか」「続・パーティションの効果を検証する」でも、インデックスの効果を裏打ちする結果が得られました。
では、ただインデックスを必要なクエリ向けに全て作成すればよいのか、という話になると簡単には頷けないのが現状です。「SELECTには目を見張る効果が得られるけど、UPDATEは遅くなるよね。INSERTも遅くなるかもしれないよね。そのあたりの変異が見られないか。」そんな疑問が弊社メンバーから挙がっていましたので、今回はここに焦点を当てていきます。

![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890646.png)
検証内容
10万件のレコードを持つテーブルを用意します。このテーブルに、下記の作業実施していった際の速度を取得し、その変異を検証します。
・インデックスを追加で作成する
・INSERTを5回行う(100件/1000件/10000件/20000件/50000件の5回)
・INDEXである列のUPDATEを5回行う(100件/1000件/10000件/20000件/50000件の5回)
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890818.png)
検証詳細
速度を計測するため、可能なかぎり公平な条件にします。
このため、検証の詳細な手順は、下記のような形としました。
1. 10万件のレコードを持つテーブルを新規に用意する。
2. インデックスを追加で作成する
3. INSERTを5回行う(100件/1000件/10000件/20000件/50000件の5回)
4. INDEXである列のUPDATEを5回行う(100件/1000件/10000件/20000件/50000件の5回)
・このルーティンを、インデックスの数を最大5個まで増やしながら実施します。
・INSERTとUPDATEの速度計測は、5回実施します。
・SQL実行後は、都度、キャッシュクリアを行います。
・テーブルは毎回作り直します。
・UPDATEでは、INDEXである列を更新します。このとき、WHERE句には、INDEXである列を含めないものとします。
・速度情報は、SI Object Browser(以下 OB)のSQL実行画面に表示される実行時間、データ生成画面に表示される実行時間を使用します。
検証環境
今回の検証環境は以下の通りです。
マシン情報
検証テーブル情報
| 列名 | 型 | 長さ | 精度 | PK |
|---|---|---|---|---|
| KEY_NUM | NUMBER | 10 | 0 | Y |
| KEY_SUB_NUM | NUMBER | 10 | 0 | Y |
| KEY_NAME | NVARCHAR2 | 10 | Y | |
| NUM_CLM_1 | NUMBER | 10 | 0 | |
| NUM_CLM_2 | NUMBER | 10 | 0 | |
| NUM_CLM_3 | NUMBER | 10 | 0 | |
| NUM_CLM_4 | NUMBER | 10 | 0 | |
| NUM_CLM_5 | NUMBER | 10 | 0 | |
| CHAR_CLM_1 | NVARCHAR2 | 20 | ||
| CHAR_CLM_2 | NVARCHAR2 | 20 | ||
| CHAR_CLM_3 | NVARCHAR2 | 20 | ||
| CHAR_CLM_4 | NVARCHAR2 | 20 | ||
| CHAR_CLM_5 | NVARCHAR2 | 20 |
検証準備
OBを使用して、前述の検証テーブルを作成します。OBのデータ生成機能を使用し、データを10万件投入します。
| 列名 | データ生成方法 |
|---|---|
| KEY_NUM | 固定値 100000 |
| KEY_SUB_NUM | 連番。1から開始し1ずつカウントアップ |
| KEY_NAME | 固定値 ‘INIT’ |
| NUM_CLM_1 | 固定値 100000 |
| NUM_CLM_2 | 乱数値(数値) |
| NUM_CLM_3 | 乱数値(数値) |
| NUM_CLM_4 | 乱数値(数値) |
| NUM_CLM_5 | 乱数値(数値) |
| CHAR_CLM_1 | 固定値 ‘INIT’ |
| CHAR_CLM_2 | 乱数値(文字) 全桁埋める ON |
| CHAR_CLM_3 | 乱数値(文字) 全桁埋める ON |
| CHAR_CLM_4 | 乱数値(文字) 全桁埋める ON |
| CHAR_CLM_5 | 乱数値(文字) 全桁埋める ON |
OBのテーブルコピー機能を使用して、上記データを保持したテーブルを複製します。これにより、初期条件を同じ状態に保ちます。
こののちに、INDEXを追加で設定します。前述しましたとおり、1回目のルーティンは、CHAR_CLM1をインデックスで指定します。INSERTとUPDATEの計測を5回終了したら、最初のルーティンは終了とします。2回目のルーティンからは、CHAR_CLM1のインデックスとCHAR_CLM2のインデックスの2つを作成していきます。
それでは検証開始です。
検証結果
INSERTは、OBのデータ生成機能で行います。
初期データと同じイメージで、100件、1000件、10000件、20000件、50000件と生成します。
| 列名 | データ生成方法 |
|---|---|
| KEY_NUM | 固定値 100 (件数に合わせて変える) |
| KEY_SUB_NUM | 連番。1から開始し1ずつカウントアップ |
| KEY_NAME | 固定値 ‘INS_100’ (件数に合わせて変える) |
| NUM_CLM_1 | 固定値 100 (件数に合わせて変える) |
| NUM_CLM_2 | 乱数値(数値) |
| NUM_CLM_3 | 乱数値(数値) |
| NUM_CLM_4 | 乱数値(数値) |
| NUM_CLM_5 | 乱数値(数値) |
| CHAR_CLM_1 | 固定値 ‘INS_100’ (件数に合わせて変える) |
| CHAR_CLM_2 | 乱数値(文字) 全桁埋める ON |
| CHAR_CLM_3 | 乱数値(文字) 全桁埋める ON |
| CHAR_CLM_4 | 乱数値(文字) 全桁埋める ON |
| CHAR_CLM_5 | 乱数値(文字) 全桁埋める ON |
UPDATEは、インデックスに指定されたカラムを更新します。インデックスをWHERE句に指定しないこととします。
クエリイメージを以下に示します。
|
1
2
3
4
5
6
7
|
UPDATE DBLAB_TEST_COPY
SET CHAR_CLM_1 = 'UPD_100'
,CHAR_CLM_2 = 'UPD_100'
,CHAR_CLM_3 = 'UPD_100'
,CHAR_CLM_4 = 'UPD_100'
,CHAR_CLM_5 = 'UPD_100'
WHERE KEY_NAME = 'INS_100';
|
インデックスの生成個数に応じたINSERTの結果は、以下のとおりとなりました。
| INSERT件数 | 1個 | 2個 | 3個 | 4個 | 5個 |
|---|---|---|---|---|---|
| 100件 | 0.252 | 0.665 | 1.371 | 2.101 | 2.573 |
| 1000件 | 0.264 | 2.153 | 4.300 | 5.544 | 6.780 |
| 10000件 | 1.351 | 3.953 | 6.097 | 7.359 | 9.643 |
| 20000件 | 3.244 | 5.890 | 9.620 | 12.530 | 14.916 |
| 50000件 | 6.745 | 11.999 | 18.953 | 27.174 | 34.556 |
※単位:秒 数値は、5回測定の平均
インデックスの生成個数に応じたUPDATEの結果は、以下のとおりとなりました。
| UPDATE件数 | 1個 | 2個 | 3個 | 4個 | 5個 |
|---|---|---|---|---|---|
| 100件 | 1.736 | 2.720 | 3.517 | 5.165 | 6.162 |
| 1000件 | 1.455 | 5.430 | 7.403 | 11.421 | 17.030 |
| 10000件 | 2.590 | 6.613 | 9.642 | 14.916 | 19.534 |
| 20000件 | 3.580 | 11.023 | 17.598 | 23.227 | 33.985 |
| 50000件 | 7.816 | 18.799 | 30.039 | 52.558 | 74.279 |
※単位:秒 数値は、5回測定の平均
これをグラフにすると、下記のとおりとなります。縦軸の実行時間スケールをそろえて、速度の違いを視覚的に見せてみます。
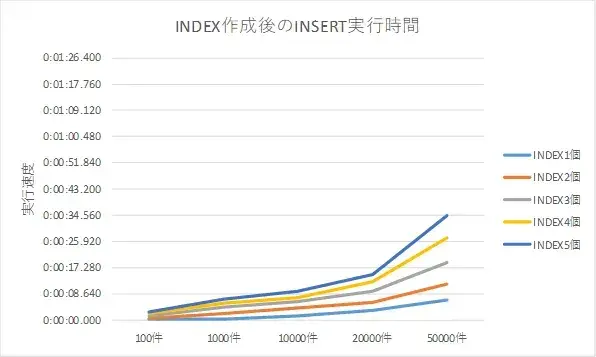
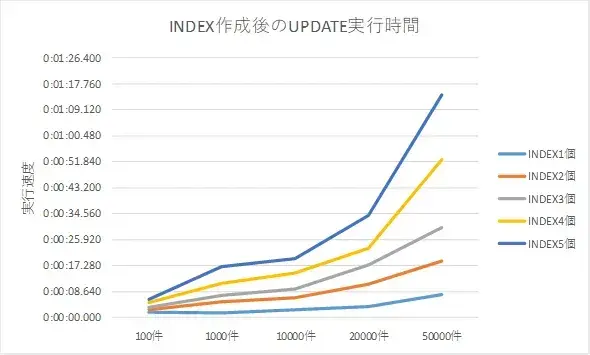
「件数に応じて、INSERT、UPDATEの実行時間が増していく。」みなさんが予想されているとおりの結果となりました。横スケールの幅が特殊なのですが、INDEXの増加に伴い、曲線の傾きが大きくなるのは読み取れる結果となりました。また、増えていく幅が少しずつ大きなっていっているように見えますが、今回のUPDATEではINDEXを指定しないため条件にしましたので、このあたりが影響しているかなと思われます。
追加検証
「INDEXの列を更新しているのだから、時間がかかるのは当然。」という観点もあります。そこで、INDEXではない列をUPDATEしたら?という部分を測定してみます。条件は同じで、UPDATEのSQLだけ。列を変えて速度を計測します。
インデックスの生成個数に応じたインデックスではない列のUPDATEの結果は、以下のとおりとなりました。
| UPDATE件数 | 1個 | 2個 | 3個 | 4個 | 5個 |
|---|---|---|---|---|---|
| 100件 | 2.182 | 1.031 | 1.032 | 1.012 | 1.296 |
| 1000件 | 1.838 | 1.078 | 1.110 | 1.115 | 1.235 |
| 10000件 | 2.188 | 1.407 | 1.469 | 1.532 | 1.641 |
| 20000件 | 2.687 | 1.957 | 1.986 | 2.075 | 1.967 |
| 50000件 | 3.668 | 2.844 | 2.438 | 2.615 | 2.500 |
※単位:秒 数値は、5回測定の平均
グラフは以下のとおりです。こちらも速度スケールを合わせて表示してみます。
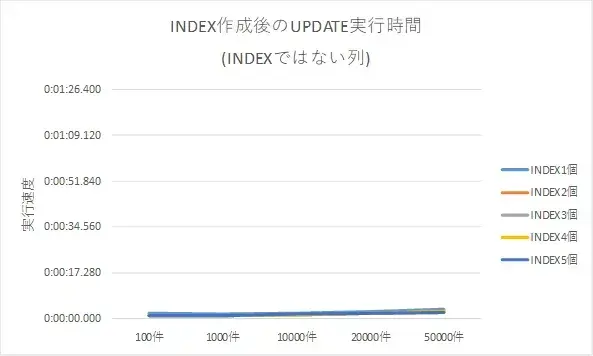
INDEXの更新があるかないか、それだけで実行時間にかなりの違いがあることがデータとして取れました。
[RELATED_POSTS]
結論
定説通り、インデックスを追加することにより、INSERTとUPDATEの実行時間に影響がみられることがわかりました。しかし、インデックスに加えられていない列のUPDATEについては、この限りではないこともデータとしてわかりました。
今回の検証では、各クエリの間にキャッシュのクリアを実行しています。このため、初回実行時の速度という見方が強い部分があります。クリアしない場合の傾向がどうなっていくのか、トランザクションの処理データ件数による傾向など、データの取得条件は様々ですので、まだまだ検証の余地はありそうです。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890651.png)








![いまさら聞けない Oracleの基本 [初級編]](https://products.sint.co.jp/hubfs/images/siob/thumb/ora_b.png)

![いまさら聞けない Oracleの基本 [中級編]](https://products.sint.co.jp/hubfs/images/siob/thumb/ora2.webp)
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890654.png)