![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890646.png)
インデックスの作成はパフォーマンス改善に役立つといわれているが
インデックスの作成というのは、データベースのパフォーマンス改善方法の一つとしてよく用いられる方法かと思います。実際にインデックスを作成することで改善できたという経験をお持ちの方も多いのではないでしょうか。
インデックスの作成にあたり、パフォーマンスが改善すると一般的に言われている状況はいくつか存在しますが、状況によってパフォーマンスは改善せず、最悪の場合劣化する可能性があります。インデックスの作成はその状況に応じて正しく作成することが重要となります。
今回の検証では、Bツリーインデックスを用い、一般的にインデックスを作成すると良いと言われているケースのうち、以下の2パターンを例に挙げ、実際にSQL実行速度にどれくらいの違いが出るのかを検証していきます。
ケース1:大量データが格納されているテーブルから、少量データを検索する場合
ケース2:該当の列に格納されているデータの種類が多い場合
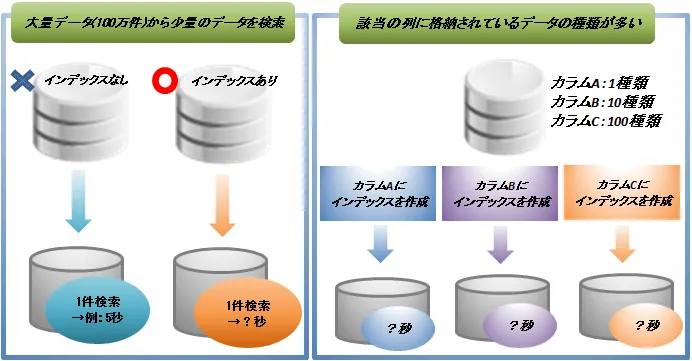
図1:検証イメージ
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890818.png)
インデックスの効果が出ると言われているケース
ケース1:大量データが格納されているテーブルから、少量データを検索する場合
全体のデータ数に対して、検索するデータ数が少ない場合にインデックスの効果があると言われています。
インデックスを作成することで、パフォーマンスが改善されるというデータの割合に関しては、データの構造など環境面での影響を大きく受けるため一概には言えないようです。
(全体の2~4%未満という人もいれば、20%未満という人も・・・)
また、テーブルの全体データ数によっても、インデックスの効果が出ず、逆に劣化する場合があります。
ケース2:該当の列に格納されているデータの種類が多い場合
データの内容(種類)が多い場合もインデックスの効果があると言われています。
例えばフラグとして利用としているカラムで、「Y」か「N」しかセットされていないカラムは、Bツリーインデックスの効果はほとんどありません。
逆に、全て違う値がセットされているカラムは、Bツリーインデックスの特性が生かされ、効果が発揮されます。
検証内容
今回は前述したインデックスの効果が出るといわれているケースを再現し、インデックスあり・なしの状態でSELECT文の実行時間の比較検証を行います。
また、データの内容が影響するケースでは、テーブルに格納されているデータの内容を書き換えながら計測を行っていきます。
検証詳細
ケース1:大量データが格納されているテーブルから、少量データを検索する場合
・サンプルテーブルに100万件のデータを作成
・それぞれのデータ数が検索でヒットするようなデータを用意
データA:1件
データB:10件
データC:25件
データD:50件
データE:100件
データF:1000件
データG:10000件
・検索用のデータを検索条件に指定してSELECT文を実行
select * from TEST_INDEX1 where COL2 = ‘(データA)’
select * from TEST_INDEX1 where COL2 = ‘(データB)’
select * from TEST_INDEX1 where COL2 = ‘(データC)’
select * from TEST_INDEX1 where COL2 = ‘(データD)’
select * from TEST_INDEX1 where COL2 = ‘(データE)’
select * from TEST_INDEX1 where COL2 = ‘(データF)’
select * from TEST_INDEX1 where COL2 = ‘(データG)’
・インデックスをあり・なしでそれぞれ5回実施し、平均値で比較を行う
・一回の検証ごとに監査ログ(テーブル、XML)、DBバッファキャッシュをクリア
・データ生成には OBのデータ生成機能を使用
ケース2:該当の列に格納されているデータの種類が多い場合
・サンプルテーブルに10万件のデータを作成
・格納するデータの種類毎にカラムを用意
カラムA:1種類 (×100000件)
カラムB:10種類 (×10000件)
カラムC:100種類 (×1000件)
カラムD:1000種類 (×100件)
カラムE:10000種類 (×10件)
カラムF:100000種類 (×1件)
・各カラムを検索条件に指定してSELECT文を実行
select * from TEST_INDEX2
where カラムA = ‘(検索用データ)'
and カラムB = ‘(検索用データ)’
and カラムC = ‘(検索用データ)’
and カラムD = ‘(検索用データ)’
and カラムE = ‘(検索用データ)’
and カラムF = ‘(検索用データ)’
・各カラムにインデックスを作成してそれぞれ5回実施し、平均値で比較を行う
・一回の検証ごとに監査ログ(テーブル、XML)、DBバッファキャッシュをクリア
・データ生成には OBのデータ生成機能を使用
検証環境
今回の検証環境は以下の通りです。
| マシン | OS | Windows7 | |||||||||||||
| CPU | Intel Core i5-2430M 2.40GHz | ||||||||||||||
| メモリ | 4GB | ||||||||||||||
| その他 | 特に無し | ||||||||||||||
| DB ケース1 |
対象RDBMS | Oracle11.0.2.0.1.0 | |||||||||||||
| テーブル名 | TEST_INDEX1 | ||||||||||||||
| テーブル項目 |
※主キー設定:COL1 |
||||||||||||||
| DB ケース2 |
対象RDBMS | Oracle11.0.2.0.1.0 | |||||||||||||
| テーブル名 | TEST_INDEX2 | ||||||||||||||
| テーブル項目 |
※主キー設定:COL1 |
検証準備
ケース1:大量データが格納されているテーブルから、少量データを検索する場合
① データ生成(100万件を用意)
まずは100万件のデータを下記の通り設定しました。
いつものようにSI Object Browserのデータ生成機能を使って準備します。(第1回参照)
| カラム名 | データ生成方法 |
|---|---|
| COL1 | 連番。1から開始し1ずつカウントアップ |
| COL2 | 乱数値 全桁埋め |
② データ生成(既存データのUPDATE)
データ生成機能の一つ「既存データのUPDATE」を使用して、検索用データを作成します。
「既存データのUPDATE」では、既にテーブルに格納されているデータに対して更新を行うことが可能です。
テーブルに格納されている全データに対しても、条件を指定して任意のレコードに対して更新を行うことも可能です。
図2では10000件のデータを用意するため、「既存データのUPDATE」を使用しているところです。
同様の操作を、1件、10件、25件、50件、100件、1000件、10000件と実施します。
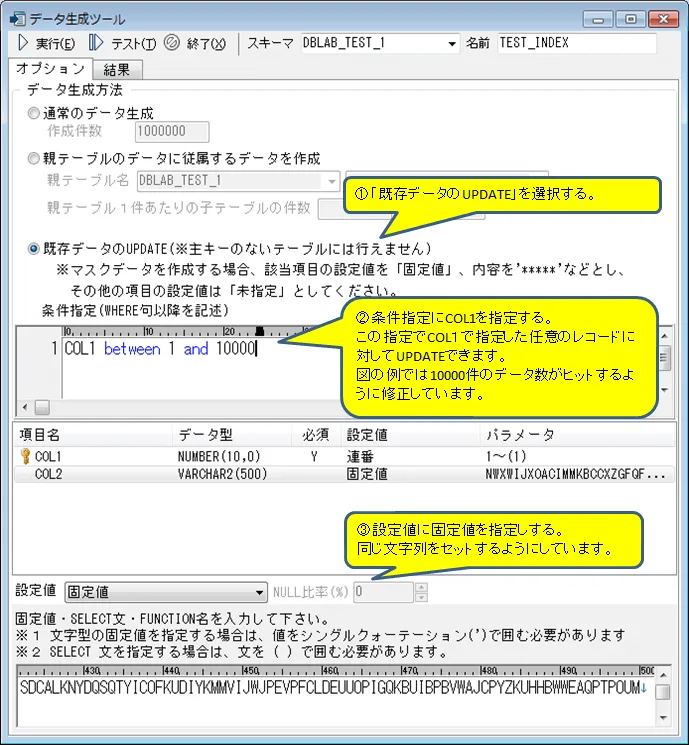
図2.既存データのUPDATE
ケース2:該当の列に格納されているデータの種類が多い場合
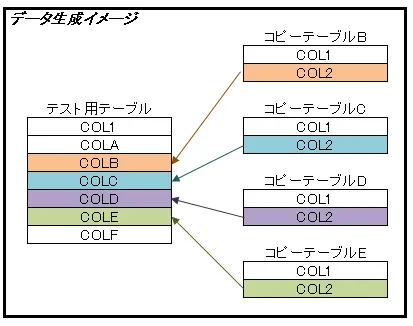
①コピーテーブルの作成
検証で使うテーブルと同じ定義のテーブルを4つコピーし、それぞれのテーブルにはデータ生成でデータを用意しておきます。
なぜコピーテーブルを作成するのかというと、10種類~10000種類のデータを用意するためですが、詳細は次の手順で説明します。
コピーはSI Object Browserのコピー機能を使用します。(第5回参照)
データ生成は以下の設定で実行します。
| カラム名 | データ生成方法 |
|---|---|
| COL1 | 連番。1から開始し1ずつカウントアップ |
| COL2 | 乱数値 全桁埋め |
コピーした4つのテーブルには、10件、100件、1000件、10000件のデータを作成しておきます。
②データ生成(テスト用テーブル(本物)) データ生成機能を使って10万件のデータを準備します。
| カラム名 | データ生成方法 |
|---|---|
| COL1 | 連番。1から開始し1ずつカウントアップ |
| COLA | 固定値 |
| COLB | リンクテーブル値 コピーテーブルB:COL2 |
| COLC | リンクテーブル値 コピーテーブルC:COL2 |
| COLD | リンクテーブル値 コピーテーブルD:COL2 |
| COLE | リンクテーブル値 コピーテーブルE:COL2 |
| COLF | 乱数値 全桁埋め |
| ここで重要なのが「リンクテーブル値」です。 これは、指定したテーブルのカラムのデータを参照してセットすることができます。 この機能を使えば、先ほど作成したコピーテーブルを指定することで、10種類~10000種類のデータを用意することができるのです。 (図3.リンクテーブルを使ったデータ生成を参照) |
図3.リンクテーブルを使ったデータ生成 |
|
検証結果
ケース1:大量データが格納されているテーブルから、少量データを検索する場合
インデックスなし
| 検索条件 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 平均 |
|---|---|---|---|---|---|---|
| データA:1件 | 00:07.239 | 00:06.988 | 00:06.895 | 00:06.864 | 00:06.558 | 00:06.909 |
| データB:10件 | 00:07.286 | 00:06.833 | 00:06.771 | 00:06.615 | 00:06.802 | 00:06.861 |
| データC:25件 | 00:07.233 | 00:06.989 | 00:07.395 | 00:07.020 | 00:07.348 | 00:07.197 |
| データD:50件 | 00:00.078 | 00:00.062 | 00:00.078 | 00:00.062 | 00:00.079 | 00:00.072 |
| データE:100件 | 00:00.031 | 00:00.062 | 00:00.031 | 00:00.094 | 00:00.078 | 00:00.059 |
| データF:1000件 | 00:00.062 | 00:00.093 | 00:00.047 | 00:00.063 | 00:00.031 | 00:00.059 |
| データG:10000件 | 00:00.188 | 00:00.125 | 00:00.109 | 00:00.125 | 00:00.141 | 00:00.138 |
※単位:秒
インデックスあり
| 検索条件 | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 平均 (改善率) |
|---|---|---|---|---|---|---|
| データA:1件 | 00:00.047 | 00:00.047 | 00:00.063 | 00:00.047 | 00:00.078 | 00:00.056 99.18% |
| データB:10件 | 00:00.094 | 00:00.109 | 00:00.047 | 00:00.094 | 00:00.093 | 00:00.087 98.73% |
| データC:25件 | 00:00.093 | 00:00.078 | 00:00.078 | 00:00.031 | 00:00.078 | 00:00.072 99.01% |
| データD:50件 | 00:00.031 | 00:00.031 | 00:00.032 | 00:00.032 | 00:00.031 | 00:00.031 56.39% |
| データE:100件 | 00:00.016 | 00:00.015 | 00:00.015 | 00:00.016 | 00:00.016 | 00:00.016 73.56% |
| データF:1000件 | 00:00.015 | 00:00.016 | 00:00.015 | 00:00.015 | 00:00.015 | 00:00.015 74.24% |
| データG:10000件 | 00:00.031 | 00:00.032 | 00:00.047 | 00:00.047 | 00:00.046 | 00:00.041 70.58% |
※単位:秒
平均値での実行時間の対比は以下の通りです。
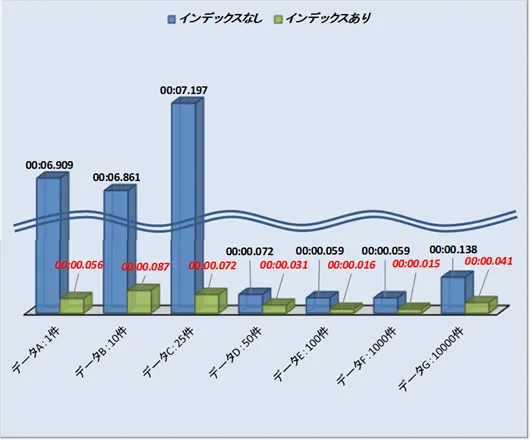
図4.平均時間(ケース1)
1件~25件まではインデックスなしの場合の実行時間が長く、インデックスを付けることでパフォーマンスの改善が見られます。
改善率は98%以上を叩き出しています。
50件以降はインデックスなしでの実行時間も短いため、インデックスの効果は少ないようです。
ケース2:該当の列に格納されているデータの種類が多い場合
| インデックス作成カラム | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 平均 (改善率) |
|---|---|---|---|---|---|---|
| なし | 00:05.162 | 00:05.156 | 00:05.027 | 00:04.866 | 00:04.824 | 00:05.007 - |
| カラムA 1種類 | 00:04.762 | 00:04.846 | 00:04.885 | 00:04.864 | 00:04.799 | 00:04.831 3.51% |
| カラムB 10種類 | 01:39.457 | 01:14.233 | 01:54.867 | 02:46.472 | 02:40.104 | 02:03.027 △-2357.09% |
| カラムC 100種類 | 00:03.075 | 00:04.013 | 00:03.277 | 00:03.133 | 00:03.162 | 00:21.358 △-326.56% |
| カラムD 1000種類 | 00:00.309 | 00:00.430 | 00:00.296 | 00:00.301 | 00:00.293 | 00:03.332 33.45% |
| カラムE 10000種類 | 00:00.015 | 00:00.016 | 00:00.015 | 00:00.015 | 00:00.015 | 00:00.326 93.49% |
| カラムF 100000種類 | 00:00.207 | 00:00.290 | 00:00.162 | 00:00.244 | 00:00.173 | 00:00.215 95.70% |
※単位:秒
平均値での実行時間の対比は以下の通りです。
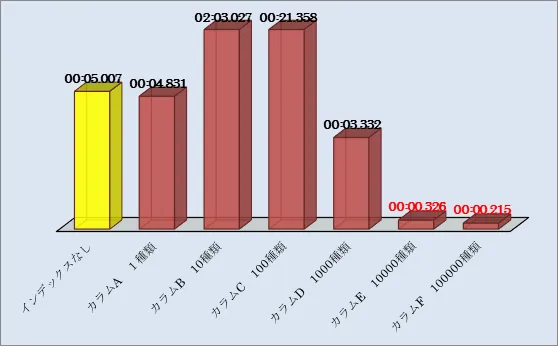
図5.平均時間(ケース2)
1種類から1000種類のデータを含むカラムにインデックスを作成しても効果は低く、パフォーマンスが悪化する場合もありました。
10000種類、100000種類のデータを含むカラムにインデックスを作成すると効果が高いという結果となりました。
改善率も95%以上を叩き出しています。 [RELATED_POSTS]
結論
今回の検証結果では、以下のようになりました。
・大量データを検索する場合よりも、少量データを検索する場合の方が効果が高い
・データ種類が少ない項目よりも、多い項目にインデックスを作成する方が効果が高い
・データ種類が少ない項目の場合(全体の1%以下)は、パフォーマンスが悪化してしまう
インデックスの作成によってパフォーマンスの改善が見られるパターンは、巷で言われている通りとなりましたが、今回作成したデータ数、データ種類ではかなり高い改善率が見られ、インデックスの作成がパフォーマンスの改善にどれだけ有効かを示す結果となりました。
ひとえにパフォーマンス改善といっても、データの内容や実施環境に左右される部分がかなり大きいかと思われますが、Oracleが推奨するだけあってインデックスの作成がもたらす効果は絶大ということになります。
今回もデータ種類が少ない場合にパフォーマンスの悪化を確認しましたが、インデックスを作成することが推奨されていない場合に、どれくらいの悪化が見られるかという検証も今後実施できればと思います。
今回の検証結果は以上となります。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890651.png)








![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890654.png)