![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890646.png)
Oracle Database 12cで注目されている
「Oracle Database In-Memory」
この度「SI Object Browser for Oracle Ver.13.0」(以下、Object Browser)がこの機能に対応しましたので今回のDBラボはインメモリについて行っていこうと思います。
インメモリとは?
Oracle Database 12cの代表的な機能の一つであり、「Oracle Database In-Memory」といいます。
メモリー上にカラムフォーマットで載せることにより、分析系クエリが高速化し、従来のローフォーマットも同時に使用することでトランザクション処理のパフォーマンスも向上するのが特徴です。
導入の際にアプリケーション側での変更は必要なく、テーブル定義の変更でインメモリ化が可能となっています。
(※この機能はOracle 12c(12.1.0.2)からご利用できます。)
従来の通常テーブルとインメモリ設定を施したインメモリテーブルでどの程度パフォーマンスが向上するか、今回は以下のケースについて検証しようと思います。
ケース1:テーブルの全件検索
ケース2:テーブルの1レコード検索とインデックス検索
ケース3:表結合でも有効か否か
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890818.png)
検証環境
今回の検証環境は以下の通りです。
クライアント環境
| OS | Windows Server 2012 R2 Standard (64ビット) |
| CPU | Intel(R) Xeon(R)CPU E5-2670 v2 @2.50GHz |
| メモリ | 7.50GB |
| 補足1 | SI Object Browser Ver.13 をインストール |
サーバー環境
| 補足1 | クライアントと同じ環境 |
データベース
| 製品名 | Oracle Database 12c |
| エディション | Enterprise Edition |
| バージョン | 12.1.0.2.0 |
| ビット数 | 64ビット |
| 補足1 | SGAのサイズを十分に確保すること(当環境は3GB確保しています) |
| 補足2 | 初期化パラメータ "inmemory_size" を 500MB 以上にすること |
ケース1:テーブルの全件検索
従来の通常テーブルとインメモリ設定を施したインメモリテーブルでフルスキャンを行った際にどのくらいの違いが生じるのだろうか?
従来のテーブルとインメモリ化したテーブルを比較し、平均実行時間を調べました。
ケース1の準備
まず、ベースになるテーブルを下記SQLで作成します。
CREATE TABLE TBL_LABO_NOMAL
(
F_ID NUMBER NOT NULL,
F_VALUE NUMBER,
F_DATE DATE,
CONSTRAINT PK_TBL_LABO_NOMAL PRIMARY KEY (F_ID) USING INDEX
)
/
上記のテーブルを作成した後、データの作成を行います。
今回は500万レコードセットした状態で行います。もちろん手入力では作成が難しいので、
SI Object Browserのデータ生成ツールの機能を使用します。
詳細は(第1回参照)
F_ID 列の設定値:無難に1~の連番を設定しました。
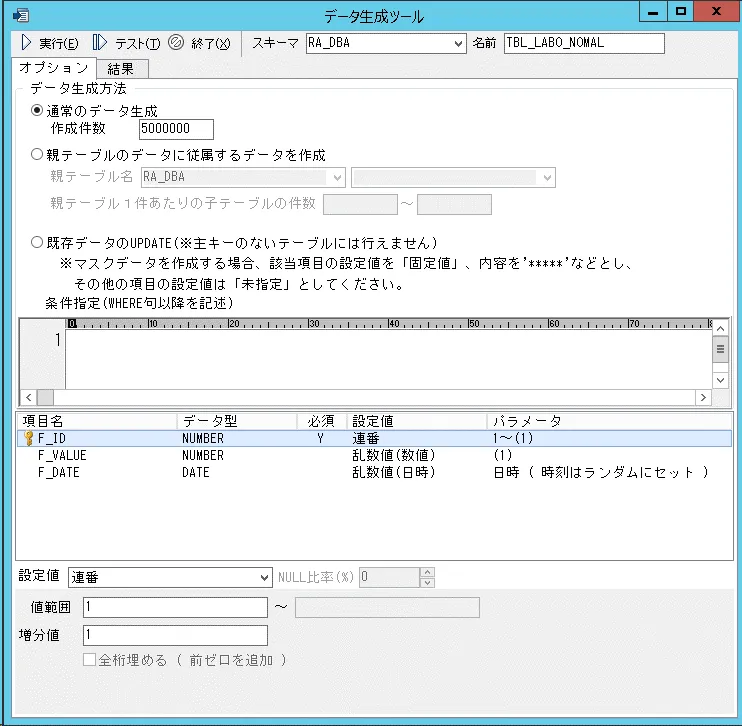
F_VALUE 列の設定値:全て整数になるように丸め値を設定しました。
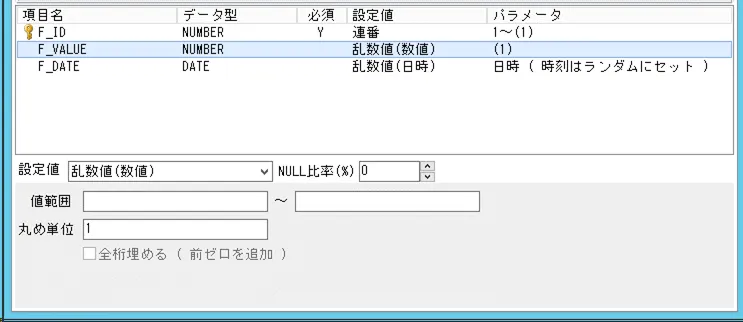
F_DATE 列の設定値:日付の乱数値を設定しました。
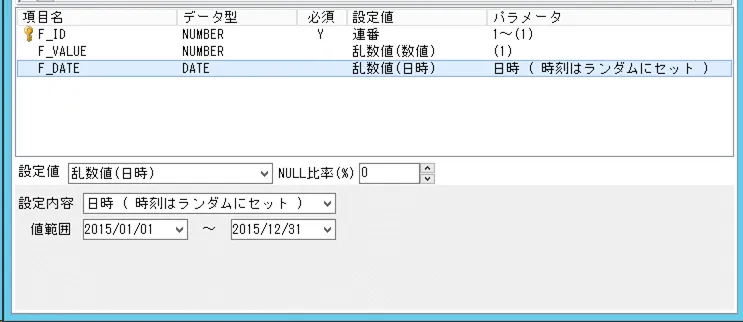
データの作成が終了しましたら、次はインメモリテーブルを作成します。
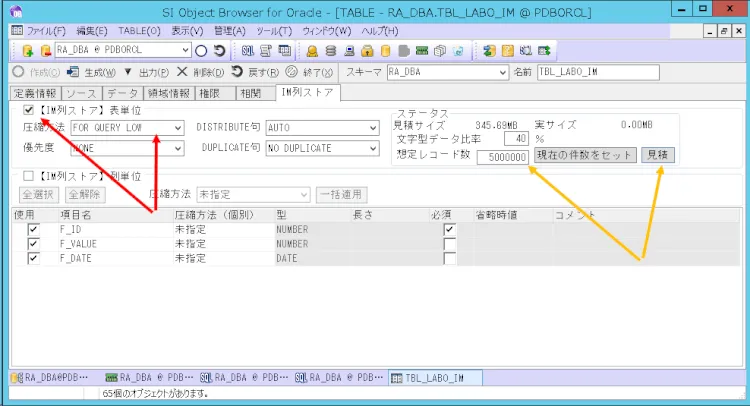
SI Object Browserのオブジェクトリストより「TBL_LABO_NOMAL」を選択し、右クリックよりコピー&ペーストを行います。リネームを促されますので下記画像のように変更します。
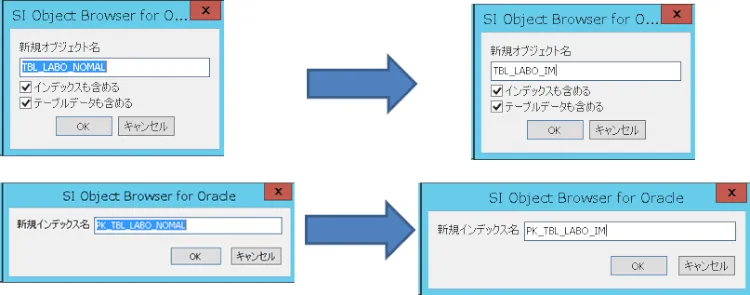 コピーが終わったら、次はインメモリの設定を行います。
コピーが終わったら、次はインメモリの設定を行います。
テーブル画面より[IM列ストア]タブの左上のチェックボックスをチェックし、圧縮方法を「FOR QUERY LOW」を指定して[作成]ボタンを押すことでインメモリ設定を行います。
また、事前に右上の見積機能を使い、メモリがどの程度使用されるかを確認しておくことをお勧めします。
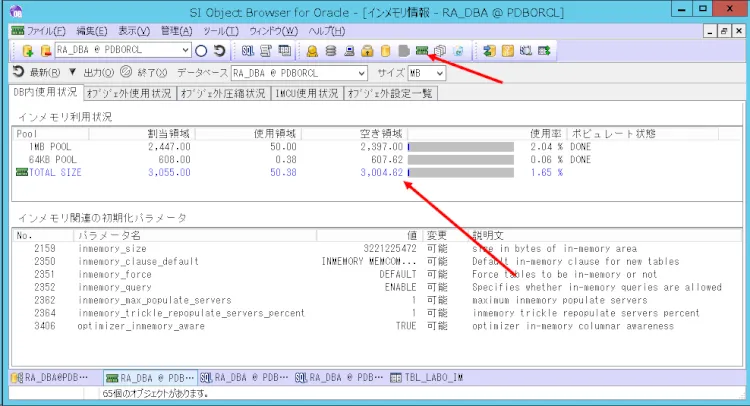
インメモリ領域の空き領域を確認しておきます。3004MBの空きがあるので実験には問題ありません。
ケース1の実験開始
準備が整いましたら、下記SQLで実行時間を計測していきます。
※平均実行時間について
10回計測を行い、そのうちの5つの中央値を使用。その5つの値の平均を平均実行時間とします。
SELECT
COUNT(F_VALUE), MAX(F_VALUE), MIN(F_VALUE), AVG(F_VALUE)
FROM
テーブル名
/
| 通常テーブル(TBL_LABO_NOMAL)
|
インメモリテーブル(TBL_LABO_IM)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
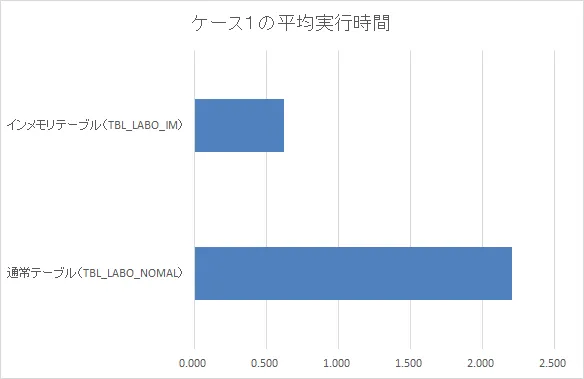
テスト1考察
圧倒的にインメモリの方が早いという結果となりました。
フルスキャンに関してはインメモリの方が圧倒的に早くなっています。
ケース2:テーブルの1レコード検索とインデックス検索
次は通常テーブル、インデックス有りの通常テーブル、そしてインメモリテーブルの実行時間を計測します。
ケース2の準備
下記のテスト1と同様の方法で新しいテーブル(TBL_LABO_NOMAL2)を作成します。
作成後に下記SQLでインデックスを付加します。
CREATE INDEX IX_TBL_LABO_NOMAL2
ON TBL_LABO_NOMAL2(F_DATE)
/
作成したら次はテスト1と同様の方法でTBL_LABO_NOMAL2 に TBL_LABO_NOMAL のデータをコピーします。
ケース2の実験開始
準備が整いましたら、下記SQLで実行時間を計測していきます。
SELECT
COUNT(F_VALUE), MAX(F_VALUE), MIN(F_VALUE), AVG(F_VALUE)
FROM
TBL_LABO_NOMAL2
WHERE
F_DATE = TO_DATE('1レコードに絞り込む日時', 'YYYY/MM/DD HH24:MI:SS')
/
| 通常テーブル(TBL_LABO_NOMAL)
|
通常テーブル・INDEX付与(TBL_LABO_NOMAL2)
|
インメモリテーブル(TBL_LABO_IM)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
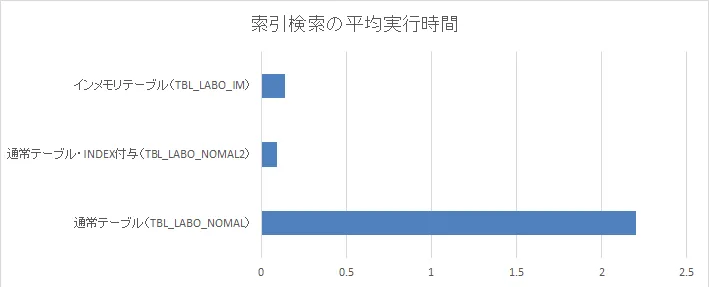
テスト2考察
平均実行時間は若干ですがインデックス有りの通常テーブルが早いという結果になりました。
これはインメモリが大量レコードの中から数行のレコードを取得するのが、あまり得意でないという点も影響していると思いますが、インデックス無しの通常テーブルと比較した場合、パフォーマンスは大きく向上しており、インメモリ化してインデックスを外しても大きくパフォーマンス低下することはなさそうです。
※Oracle公式ホームページでは導入前の事前調査と、メモリー管理が重要であると明言されています。実装の際は実行計画を有効に活用し、チューニングを行ったほうが良いと思います。 [RELATED_POSTS]
ケース3:表結合でも有効か否か
普段の開発で使用しているような結合(JOIN)しているテーブルにも有効だろうか?
従来のテーブルをLEFT JOINしたものとインメモリテーブルをLEFT JOINしたものを比較し、平均実行時間を調べました。
ケース3の準備
1つのトランザクションテーブルに3つのマスタテーブルが結合したものを計測するため、下記の8つのテーブルを用意します。また、レコード数はトランザクションテーブルに500万件、マスタテーブルには10万件の登録して計測します。
| ■通常テーブル | ■インメモリテーブル | ||
| TBL_LABO_TRN | TBL_LABO_TRN_IM | ||
| TBL_LABO_MST1 | TBL_LABO_MST1_IM | ||
| TBL_LABO_MST2 | TBL_LABO_MST2_IM | ||
| TBL_LABO_MST3 | TBL_LABO_MST3_IM | ||
トランザクションテーブルの内容は以下のようになっております。
CREATE TABLE RA_DBA.TBL_LABO_TRN
(
F_ID NUMBERNOTNULL,
F_NAME VARCHAR2(64),
F_DATE DATE,
F_MST1_ID NUMBER,--TBL_LABO_MST1のキー
F_MST2_ID NUMBER,--TBL_LABO_MST2のキー
F_MST3_ID NUMBER,--TBL_LABO_MST3のキー
F_TEXT VARCHAR2(256),
CONSTRAINT PK_TBL_LABO_TRN PRIMARY KEY (F_ID) USING INDEX
)
/
※TBL_LABO_TRN_IM も同じ構成のため割愛します。
マスタテーブルの内容は以下のようになっております。
CREATE TABLE RA_DBA.TBL_LABO_MST1
(
F_MST1_ID NUMBER NOT NULL,
F_VALUE NUMBER,
F_DATE DATE,
F_TEXT VARCHAR2(256),
CONSTRAINT PK_TBL_LABO_MST1_IM PRIMARY KEY (F_MST1_ID) USING INDEX
)
/
※TBL_LABO_MST2 / TBL_LABO_MST3 / TBL_LABO_MST1_IM / TBL_LABO_MST2_IM / TBL_LABO_MST3_IM も同じ構成のため割愛します。
作成したら次はテスト1と同様の方法でトランザクションテーブルをコピーで作成、マスタテーブルを7つコピーします。
データが全て作成し終えた状態で「_IM」が末尾に付いたテーブルをインメモリ化します。
ケース3の実験開始
準備が整いましたら、下記SQLで実行時間を計測していきます。
SELECT
COUNT(A.F_ID)
, MAX(A.F_DATE), MAX(B.F_VALUE), MAX(C.F_VALUE), MAX(D.F_VALUE)
FROM
トランザクションテーブル
LEFT JOIN
マスタテーブル1 B
ON A.F_MST1_ID = B.F_MST1_ID
LEFT JOIN
マスタテーブル2 C
ON A.F_MST2_ID = C.F_MST2_ID
LEFT JOIN
マスタテーブル3 D
ON A.F_MST3_ID = D.F_MST3_ID
/
| 全て通常テーブル
|
マスタのみインメモリ
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| トランザクションテーブルのみインメモリ
|
全てインメモリ
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| パターン | 平均実行時間 |
|---|---|
| 全て通常テーブル | 18.359 |
| マスタのみインメモリ | 17.644 |
| トランザクションテーブルのみインメモリ | 4.960 |
| 全てインメモリ | 4.163 |
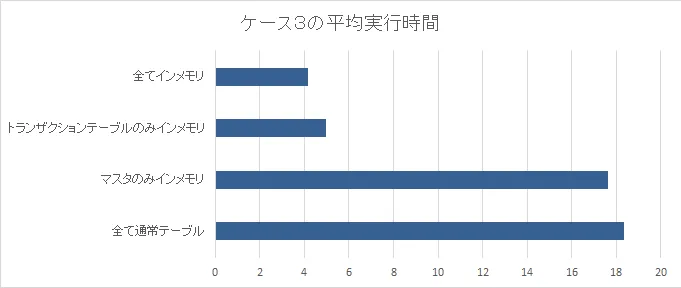
テスト3考察
インメモリ化を行うことでパフォーマンスはいずれも向上しました。
そしてインメモリにしている割合に応じてパフォーマンスも向上しました。
※「トランザクションのみ」が早いのは単純にマスタに対してデータ量の割合が大きくインメモリの恩恵もより大きく受けているからだと推測します。
結論
今回の検証結果では、以下のようになりました。
・インメモリ化はパフォーマンス向上に役立つ
・インデックスと同等の性能を持っている
・データ量が多ければ多いほど恩恵が大きい
今回の検証は本当に単純なテーブルの比較でしたが、インメモリはインデックスを使用してない列への検索は圧倒的に早いという結果になりました。
テスト2では僅差でインデックスの検索スピードに負けましたが、インデックスは断片化によるパフォーマンス低下や更新時のオーバーヘッドを持ち合わしているためインメモリ化はこれらを解消するというチューニングとしても期待できます。
しかし、何も考えずにインメモリ化を行えば、インメモリ領域がすぐに枯渇するのは明らかです。
そのため、インメモリ化は実装する前に事前にパフォーマンスが上がるか否かを検証し、ボトルネックになるテーブル、もしくは更新頻度は高いが多数のインデックスが存在するテーブルにのみインメモリ設定を行なう等の方針決めなどの必要性を感じました。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890651.png)








