データベースを利用している方々は常にパフォーマンスの改善に頭を悩ませているのではないでしょうか。それが大量のデータを扱うとなると、パフォーマンスの劣化は現れやすくなります。ソート処理を行うとなると尚更です。
ソート処理はリソースへの負荷が高く、パフォーマンスの劣化原因になりがちです。
今回の検証では、「データの種類によって、ソート処理はどれだけ遅くなるか」を検証します。
併せてインデックスの有無による性能の変化に関しましても、検証を行っていきます。
なお、今回はパフォーマンスの改善方法に関しては取り上げません。
パフォーマンスの「劣化」を検証していくという趣旨で進めていきますので、普段はパフォーマンス改善に頭を悩まされている方も、今回の検証で少し休憩していってください。
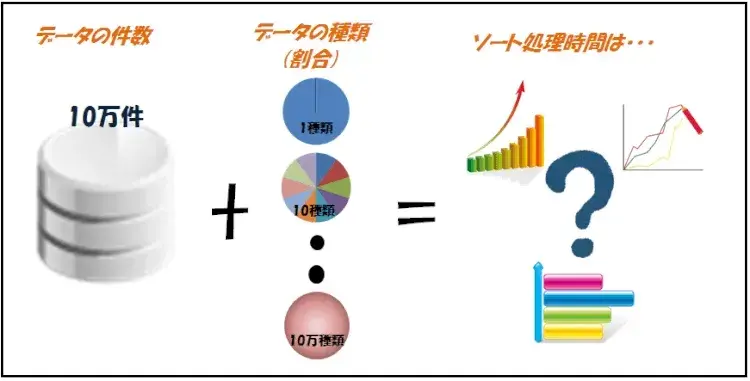
図1:検証イメージ
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890646.png)
検証内容
適当なテーブルを作成、同件数の大量データを作成し、select文の実行にかかる時間を計測します。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890818.png)
検証詳細
・サンプルテーブルに10万件のデータを作成
・その際、データの内容をいくつかのグループに分ける。
(1種類、10種類、100種類、1000種類、10000種類、100000種類)
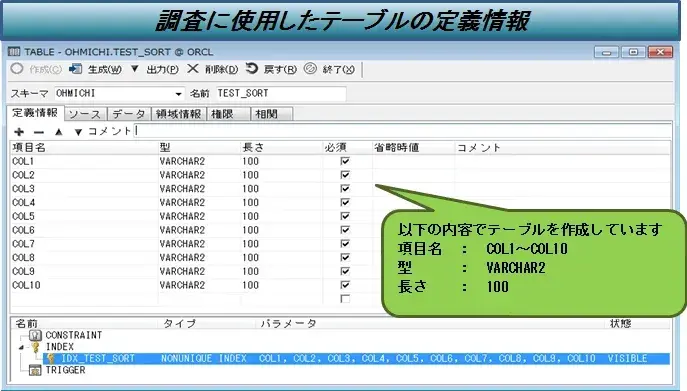
図2:検証詳細(テーブル)
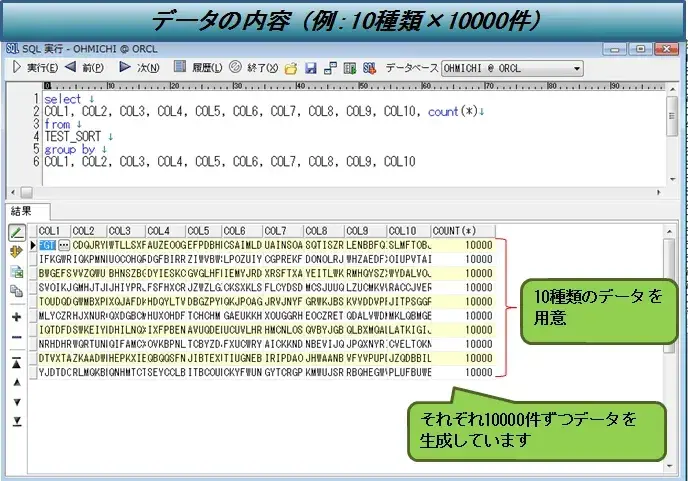
図3:検証詳細(データ)
・テーブルに対してソート句を含むSELECT文を実行する。
(SELECT * FROM テーブル名 order by 項目名)
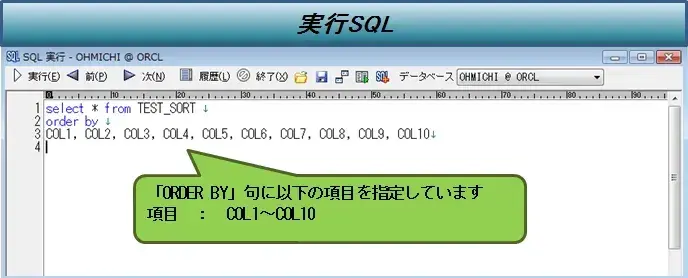
図4:検証詳細(SQL)
・インデックスなし、インデックスありの2パターンを検証する。
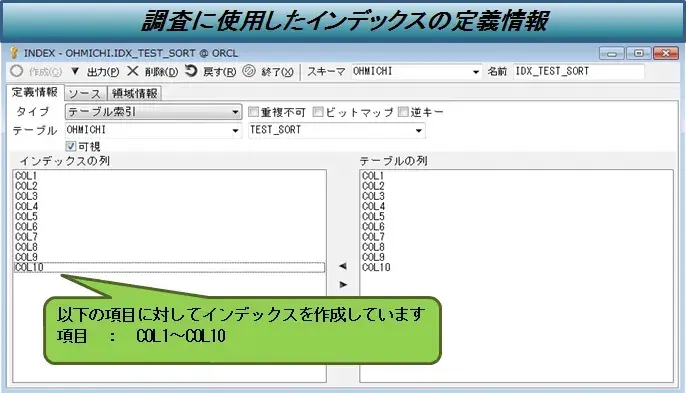
図5:検証詳細(インデックス)
・それぞれ10回実施し、平均実行時間を採用する。
・一回の検証ごとにテーブルデータを削除し、DBバッファキャッシュをクリア
・データの作成には OBのデータ生成機能を使用
・グループ分けしたデータを用意するため、OBのロード機能を使用
データ生成機能
OBにはデータ生成機能というものがあります。これは指定件数分データを自動で作成する機能です。パフォーマンステストなど大量のデータが必要な場合非常に役立つ機能です。
単独テーブルのデータを生成する通常機能のほか、親テーブル(マスタデータ)を意識したデータや、既存データをUPDATEし、住所などをマスキングした状態にすることも可能です。
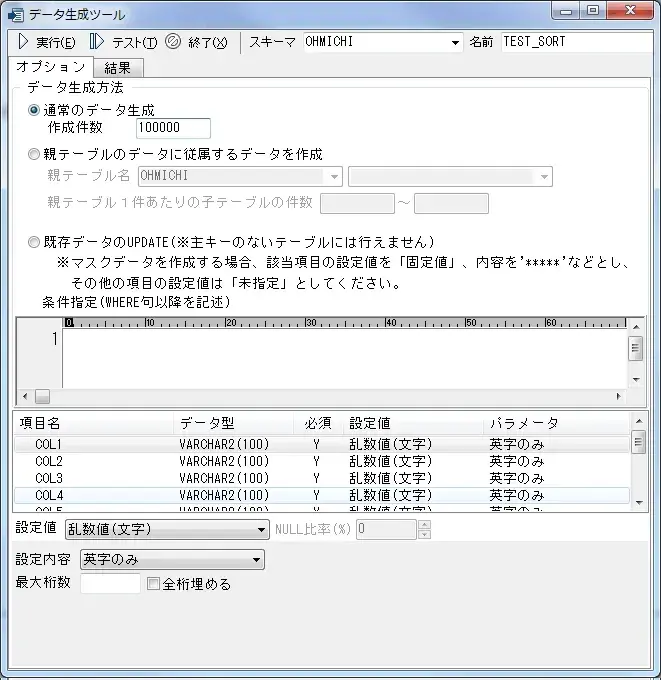
図6:データ生成画面
各項目には連番やランダムな値、住所・氏名電話番号等あらかじめ用意されたテンプレートから選択することも可能です。今回の検証ではCOL1~COL10に乱数値(文字)を選択しました。
ロード機能
OBにはロード機能というものがあります。これはOracleのSQL*Loaderを利用したもので、CSV形式で記載されているファイルをテーブルに挿入する機能です。
テーブルの内容をCSV形式で作成、挿入することが可能なため、データの管理、修正が容易で、同じ大量データを繰り返しテーブルに挿入したい場合に有効な機能です。
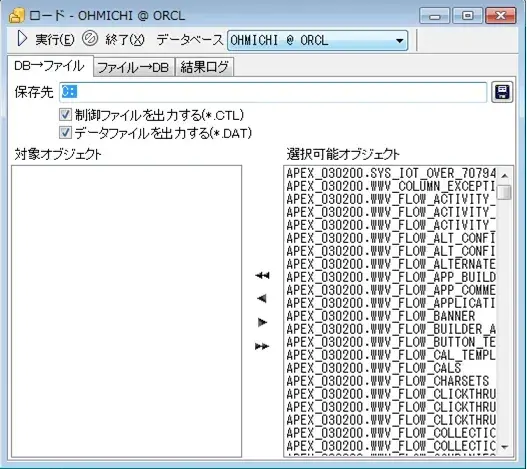
図7:ロード画面(DB→ファイル)
「DB→ファイル」タブでは、指定したテーブルをSQL*Loaderで使用するファイルに出力します。今回は、OBのデータ生成を使って10万件のデータを作成し、そのデータをファイルに出力します。
ロードに必要なファイルは以下の通りです。
・制御ファイル
→データファイルの各項目と、テーブル項目との関連付け等を定義します。
・データファイル
→実際にテーブル格納されているデータです。(CSV形式)
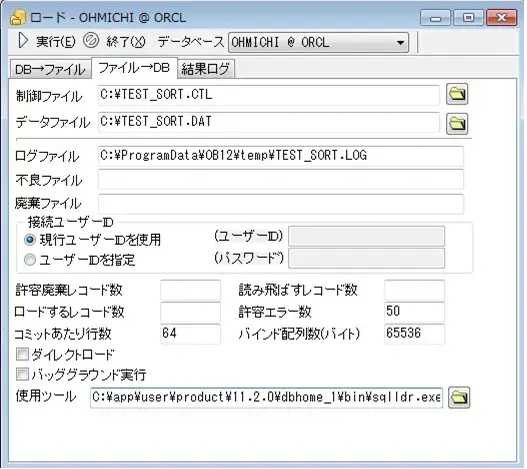
図8:ロード画面(ファイル→DB)
「ファイル→DB」タブでは、指定したファイルをSQL*Loaderを使用してテーブルに挿入します。今回は同じくロード機能で出力したファイルの内容を修正しながら(データに種類を変えながら)、テーブルに挿入します。 [RELATED_POSTS]
検証環境
今回の検証環境は以下の通りです。
| マシン | OS | Windows7 |
| CPU | Intel Core i5-2430M 2.40GHz | |
| メモリ | 4GB | |
| その他 | 特に無し | |
| DB | 対象RDBMS | Oracle11.0.2.0.1.0 |
| テーブル名 | TEST_SORT | |
| テーブル項目 | COL1,COL2・・・COL10 (データ型:VARCHAR2型, 長さ:100) ※主キー設定なし |
検証結果
以下のようになりました。
<インデックスなし> ※単位:秒
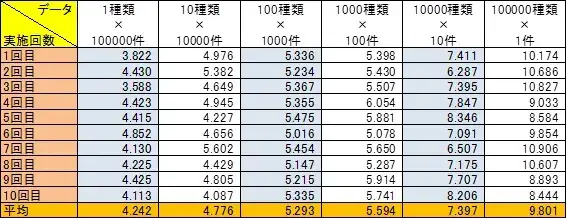
図9:検証結果(インデックスなし)
平均値での処理時間の推移は以下の通りです。
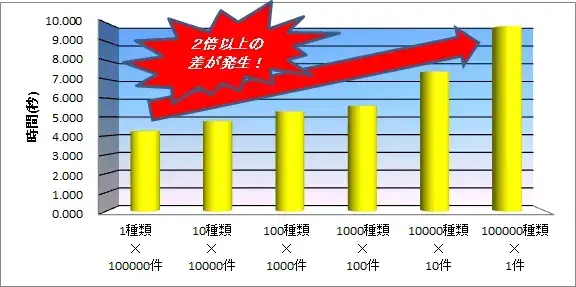
図10:検証結果グラフ(インデックスなし)
「1種類」データと、「100000種類」データの実行時間の差は2倍以上となりました。
(「1000種類」からの伸びが顕著ですね。)
<インデックスあり> ※単位:秒
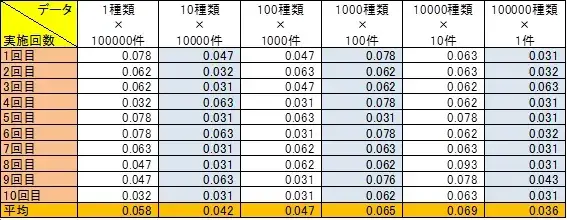
図11:検証結果(インデックスあり)
平均値での処理時間の推移は以下の通りです。
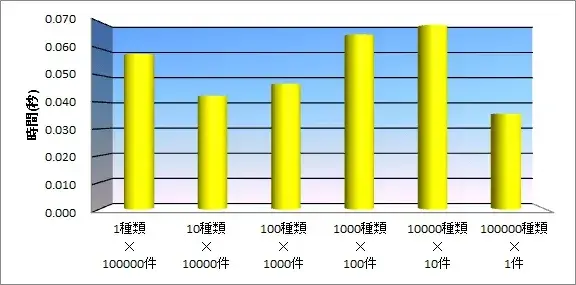
図12:検証結果グラフ(インデックスあり)
「1種類」データと、「100000種類」データの実行時間の差ほとんどありません。
なお、ソート句に指定した項目をすべて含むインデックスを作成しているため、SQL実行時にインデックスが使用され、実行時間は大幅に改善されています。
実行計画でもインデックスの使用を確認することができました。
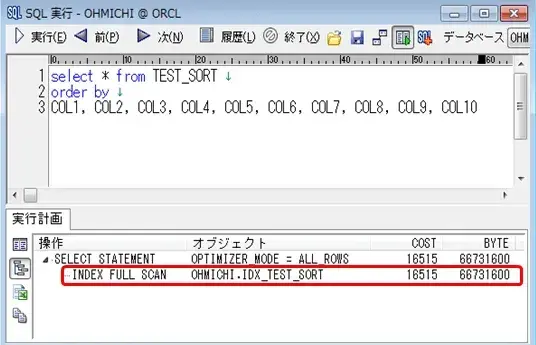
図13:実行計画
結論
今回の検証では以下のような結果となりました。
・ソート対象行のデータ種類が増加すると、ソート処理時間も増加する。
・データ種類の増加とパフォーマンス低下は単純な比例ではなく、ある一定以上になると加速する。
・ソート対象行にインデックスを設定すると、大幅にパフォーマンスが向上する。
また、今回の検証結果では<インデックスなし>の場合、1種類と100000種類で2倍近くの差が発生する結果となりました。データ種類の増加に伴い、ソート処理時間も増加する結果は想定通りでしたが、増加率は想定を上回るものでした。
通常扱うデータや項目は多岐に渡りますので、調査結果も今回の条件に限定されるものですが、ソート処理がパフォーマンスのネックになる証拠となったものと考えます。
また、パフォーマンス改善として代表的な、インデックスによる効果もかなり目立ちますので、また別の機会に検証していきたいと思います。
さて、普段はパフォーマンスの改善を追求している中、パフォーマンスの悪化を追求した今回の調査結果はいかがでしたでしょうか。
ソート処理の影響を実際に確認することで、また新たな気持ちでパフォーマンスの改善に取り組んでいただければ幸いです。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890651.png)








![いまさら聞けない Oracleの基本 [初級編]](https://products.sint.co.jp/hubfs/images/siob/thumb/ora_b.png)

![いまさら聞けない Oracleの基本 [中級編]](https://products.sint.co.jp/hubfs/images/siob/thumb/ora2.webp)
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890654.png)