前回は、正常データだけを学習する異常検知の仕組みを学びました。この方法は学習データの用意が楽ちんなのですが、生成データをどこまで実際のデータとそっくりにできるか、つまりDiffが真っ黒になるかがカギとなります。製品の向きや光の反射具合などにより、微妙に差分が出ることもあり、それをノイズとして無視するか本当の傷なのかの見分けがかなりデリケートで難しくもあります。
より確実なのは正常データと異常データを両方学習する「教師あり学習」です。今回は、この王道の異常検知の仕組みとポイントを解説します。

教師あり学習を使った異常検知
教師あり学習とは、正常品、不良品というラベルを付けた(Annotation)学習データでAI(分類器)を学習させることにより、AI君が正常品と不良品を見分けられるようになる仕組みです。これは、幼い子に「これはワンワン、これは猫ちゃん」と正解を言いながら犬と猫の写真をたくさん見せるうちに、子供が自然と犬と猫を見分けられるようになるのと同じです。写真をたくさん見るうちに犬と猫の特徴をつかむので、未知(見せていない犬や猫)の写真を見ても「あ、ワンワンだ!」と判別できるのです。
画像を見分けるディープラーニングのアルゴリズムとしては、一般に図1のような畳み込みニューラルネットワーク(CNN:Convolutional neural network)が使われます。1枚の入力画像を細かな範囲ずつスキャンしながら、畳み込み層とプーリング層からなる隠れ層(この階層が深いのがディープラーニング)で入力画像の特徴を少しずつ凝縮していって、最後に「この凝縮された特徴を持つものは正常品か異常品か?」という判事の声で陪審員が多数決で判定するような仕組みです。
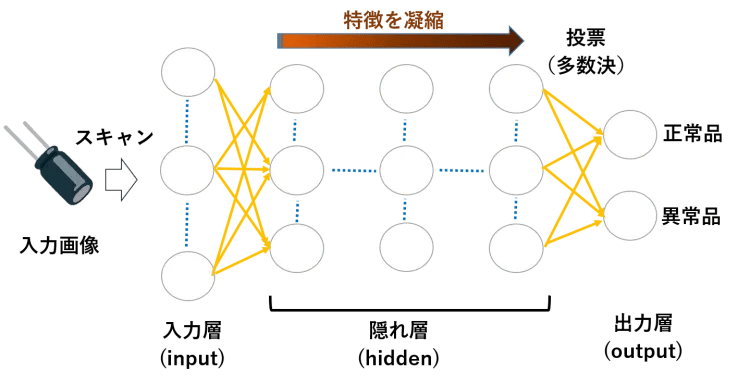
図1:畳み込みニューラルネットワーク
Vol.2でも説明しましたが、機械学習は図2のように学習プロセスと判定プロセスからなります。学習プロセスでは、例えば正常品の画像1000枚と不良品の画像(不良パターンごとに30枚程度)を正常・異常のラベル付きで学習させます。過学習を防ぎながら少量データで学習させる方法としては、転移学習や水増し、ホールドアウト法、ミニバッチ学習法、ドロップアウト、正則化、K分割交差検証などのテクニックがあるのですが、これらに興味のある方はAI技術をぱっと理解する(基礎編)をご覧ください。
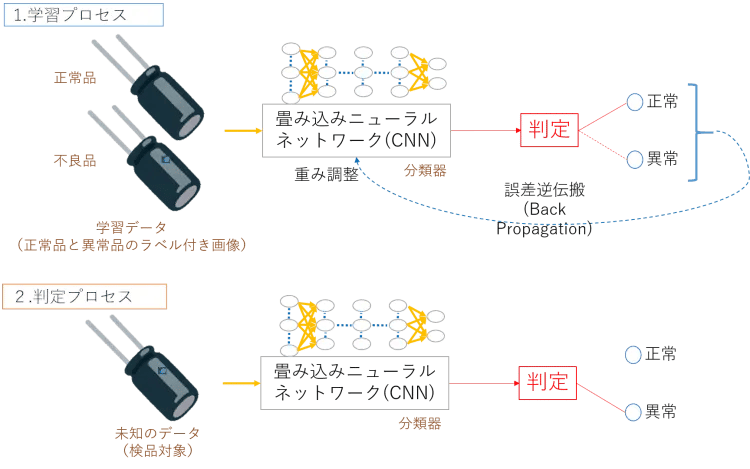
図2:教師あり学習による異常検知
AI(分類器)は自分の判定が間違ったときに、誤差逆伝搬という仕組みでニューラルネットワークの重み(Weight)を調節します。上記のテクニックを使って大量データで何回も学習するうちに、重みがいい塩梅に調整され、だんだん賢くなって遂には合格点を取れるレベルまで判定精度が高まるわけです。
判定プロセスでは、こうして合格した分類器をいよいよ本番デビューさせます。ベルトコンベアから流れてくる未知のデータを見て、「これは正常」「あ、これ不良品だ」というように分類器が判定してくれるわけです。
【麻里ちゃんのAI奮闘記】世紀をまたがって生き続けるホテリング理論

|
先輩:麻里ちゃん、ホテリング理論って知ってる? |
AIによる製品異常検知の課題
ここまでの説明で、「お、なんかいいじゃん。行けそうだ!」って思った方は、麻里ちゃんばりに素直で人が良くて幸せな人です。人と会うと、ああ、いい人だぁってすぐに好きになるタイプに間違いありません。でも、どんな人も欠点はあるわけで、付き合ううちにアラに気づいてゆく経験は誰でもあると思います。
AIによる製品異常検知にもアラ(課題)があります。人の長所を見てあげるポジティブシンキング時代に、アラをあげつらうのも気が引けるのですが、課題がはっきりすれば対応策が浮かびます。ここでAIによる異常検知の課題を確認しておきましょう。
(1)異常データが十分確保できない
一口に異常と言っても1種類ではありません。「サイズ規格外」「異物混入」「破損」「傷あり」「剥離」「色むら」「変色」「変形」など、製品によってさまざまな異常パターンがあり、これらは全て異常としてはじかなければなりません。
人の目視検査の場合は、通常、このような異常を見つけるためのチェック項目が作られています。そこには、これまでに発見された不良品の写真がサンプルとして貼られているのですが、人の場合はパターンごとに数枚写真があればことが足ります。
一方、AIの学習はそれでは足りません。転移学習や水増しなど、少量データで学習できるテクニックを使ったとしても、各パターンごとに30枚程度の画像は欲しいところです。でも、これまでAIの利用など考えてなかったわけなので、なかなか都合よく不良品の画像が蓄積されていないわけです。
【対応策】
・不良品の保管と撮影(運用の変更)
過去の不良品が保管されていれば、保管庫から取り出して写真を撮って学習データとすればOKです。問題ありませんね。でも、あまり不良品が残っていなかったらどうしましょうか。その場合は、これまで通りの運用を続けながら不良品をきちんと保管し、ある程度溜まった時点で学習に利用するしかありません。これからはAIを使った異常検知を意識した運用に変えるのです。歩留まり率をもとに計算すれば、だいたいどれくらいの期間でデータが集まるか想定することができます。
・少ないデータ量で学習する技術を採用
この2年くらいで転移学習や水増しなど、少ないデータで学習させることができる技術が進化してきました。このような技術を採用して少ないデータでも判別できるようにします。
・アクティブラーニング(追加学習)
いきなりAIに「じゃあ、後の検査は全部おまかせ!」と言えるほど、AIは完璧ではありませんし最初はミスも多いです。なので、AIの異常検知をスタートしても、少なくともある期間までは人間が外観検査を行うことになります。通常、AI は人を支援する用途で使われます。ワープロの誤字をコンピュータが「間違いでは?」と指摘してくれるように、AIが人が見落としてしまうようなミスを防止してくれるわけです。
当然のことながらAIの判定と人の判断に食い違いが生じます。通常、人間の方が偉いので、AIの判定をひっくり返し、「これは異常じゃなくて正常だよ」「おいおい、これは明らかに異常じゃないか、どこ目を付けてんだよ」とぶつぶつ言いながらAIの判定を訂正するわけです。この”AIの誤りを正してくれたデータ”が貴重な追加学習データとなります。このように運用しながら追加学習してAIがさらに賢くなる仕組みをアクティブラーニングと言います。
(2)目視の方向が1つとは限らない
品質検査対象の製品を人間が手に取って、ためつすがめつ、いろいろな角度から眺めて異常のないことを確認している場面を想像してみてください。そんな検査をAIに置き換えるような場合、1か所のカメラの画像だけで不良個所を判断できません。カメラ1台だけ付けとけばいいってほど、リアルの現場は単純じゃないのです。
【対応策】
製品の裏を見る必要がなければ、必要と思われる面に対して複数カメラを設置してそれぞれの画像を異常検知することになります。この場合、AIとしてはそれぞれ独立して異常かどうかを判断すればいいのですが、モニタリングでは複数の映像を同期させる必要があります。そのためには複数のカメラのfpsをそろえた上で、同時に撮影した音声を使って自動同期させる方法や、スタートからの位置で時間軸をそろえるタイムコード方式などさまざまな方法があり、そうした処理を行えるツールも充実しています。
人と同じように手に取ってしげしげ眺める必要がある場合は、猫の手ならぬロボットの手(ロボットアーム)を借りることになります。ロボットアームで製品をつかんで各面をカメラに向けたり、専用の検査台を設けたりしなければなりません。こうしたニーズに向けて、産業用ロボットのメーカーが人工知能ベンチャー企業とタイアップした取組みも活発に行われています。
(3)画像のオブジェクトと製品の紐付けが難しい
AIは動画から切り出されたフレーム(静止画)の中の製品を見て正常品か不良品かを判断します。このとき、フレームごとに製品がきれいに1つずつ写っているとは限りません。写り漏れが生じないようなfps速度とするので、製品が写り漏れするってことは通常ないのですが、その分、1つの製品が複数のフレームに重複して写っていることになります。
各製品に認識(ID)番号が表示されていればことは簡単です。異常を発見した製品のID番号を指定すれば、どの製品が不良だったか紐づけができます。しかし、製品にIDがないか、あっても製品IDが見えていない場合は、AIが「あ、このフレームの右上に映っているやつが異常だ!」と発見しても、それが実物のどれなのか後で紐付けするのが難しくなります。また、複数フレームに映りこんだ同一製品を、それぞれのフレームで異常と判断するわけなので、対応が煩雑になるほか、そのままカウントすると異常数が増えてしまい実際よりも異常発生率が高まってしまいます。
【対応策】
AIがオンラインで不良と判定した製品のIDを認識できない場合は、検査工程内で処理しなければなりません。検査工程の終わり(コンベアならコンベアの終端)に行くまでに処理(本当に異常かどうか判定して取り除く)しないと、後からではどれが異常だったかわからなくなってしまいます。
対応策は、どのような製品をどのように流して検査しているかという現場の状況ごとに変わりますが、代表的なパターンを挙げてみましょう。
①アラートを出して止める
例えばコンベアの上に製品が流れてくる場合、AIが異常を発見したときにパトライトなどのアラートを出し、自動もしくは手動でコンベアを止めます。そして、すぐに人間がモニタと実物を比較確認して異常製品を取り除くことになります。
②自動的に取り除く
不良品を取り除くアクチュエータやロボットアームを用意して自動的に不良品を取り除きます。これを行うためには、AIが認識した不良品情報をアクチュエータが受け取り、どこに流れている製品のことなのかを特定するような連携が必要となります。
連携の方法は千差万別です。一定の間隔、速度で製品が流れてくるので「見つけたよ」「はいな」ってタイミングだけ合わせて除去する餅つき夫婦型、製品自体もしくはその横に識別できる番号やコードがあり、AIもアクチュエータもその識別番号を認識して「F3903847番不良だよ」「ラジャー!」とAIが次々指定するオーディション審査員型(はい、3番と7番不合格。ご苦労様でした)など、いろいろ工夫を凝らして自動化します。
③複数フレームにまたがった製品が同一かどうか判定する
複数フレームに映りこんだ製品が同一かどうかを判定するには、それなりの工夫が必要です。ベルトコンベアのようにX軸だけ一定変化するようなものであれば、コンベアの速度をもとに判定できますが、ドローン画像のようなX軸とY軸が両方ずれて、かつ速度も一定じゃないものはより複雑なロジックが必要になります。
(4)異常箇所の特定が難しい
前回、オートエンコーダーを使った異常検知の仕組みを説明しました。この方法は、正常データで学んだ生成器が作り出す正常品イメージと不良品の差分を比較して、差分が生じたらそこが異常と判定するので、異常箇所(=差分の浮き出た所)の特定が簡単でした。
一方、正常品と異常品の両方を学習する教師あり学習モデルの異常検知では、AI君は異常箇所まで教えてくれません。もちろん、正常か不良かを判断する過程では異常箇所を見つけているのですが、アウトプット(ニューラルネットワークの出力層)は正常か異常かの2択なので、「これは正常」「あっ不良品だ」としか教えてくれません。「だめ!やり直し!」としか言わず、どこがだめなのかを具体的に指摘してくれない昭和の映画監督のようなのです(上司にもこういうタイプいますね)。
【対応策】
AIが異常と判断した不良品に対しては、畳込み処理のどこのどのフィルターで異常と判断したのかを逆順(出力層から前の方に)に追っていく必要があります。図1のようなディープラーニング(深層学習)のどの層で異常を認識したかを遡ると、例えば8層目のこのあたりで異常フィルタ(異常の特徴)との一致率が非常に高かったという情報がちゃんとあるのです。その箇所の座標をもとにヒートマップを付ければ、異常個所が特定できるわけです。
このように階層を遡って異常と判断したフィルタ情報を表示する技術がGRAD-CAMです。Vol.1でディープラーニングはブラックボックスだと説明しましたが、GRAN-CAMを使えば、どこでどのような判断をしたからこのような結果を出したのかを探ることができます。

GRAD-CAM
GRAD-CAMについて説明しましょう。図3は犬と猫を見分けられる畳み込みニューラルネットワーク(CNN)が、画像判定した際にどこに注目(Attention)したかをGRAD-CAMという技術を使って表したものです。
犬と猫、両方が写っている中央の写真がオリジナルの画像です。この画像をCNNで判別させたときに、これを猫と判別したときのフィルタをGRAD-CAMで表示したものが左の画像です。ヒートマップが当たっているところがAIが注目している点で、確かに猫に焦点が当たっていますね。右の画像は犬と認識したときのもので、こちらは犬に焦点が当たっています。犬は顔で犬と認識しているのに対し、猫は下腹部から下肢への柔らかなラインを見て猫と判断している様子がうかがえますね。

図3:GRAD-CAMによる猫と犬の認識
この技術を異常検知に応用すると、図4のように不良品(異常あり)と判断したときにどの異常に注目したのかをヒートマップで表示することができます。
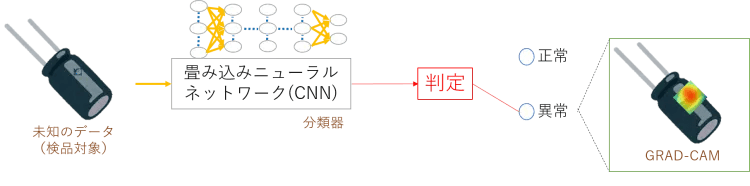
図4:GRAD-CAMによる異常個所表示
Guided Grad-CAM
Guided Grad-CAMも説明しておきましょう。図5はGuided Grad-CAMの仕組みを表したものです。オリジナルの画像(Input)を畳み込みニューラルネットワーク(CNN)で畳み込み処理(conv)により特徴(Feature Map)を凝縮(Rectify)していって、最後に全結合層(Fully Connected Layer)により多数決で猫か犬かを決めています。
ここでは猫(Tiger cat)と判定したので、特徴マップで強く猫の特徴に反応したフィルタがピックアップされています。特徴をランプ関数ReLUで正の値のみ取り出してヒートマップを表示したものがGrad-CAM(下の画像)です。確かに猫に注目していますね。
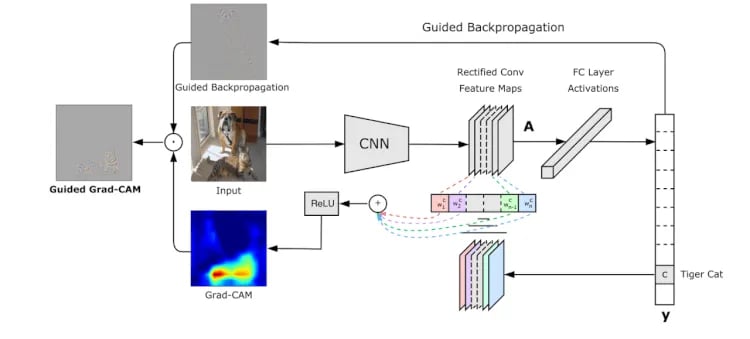
図5:Guided Grad-CAM(出展:http://gradcam.cloudcv.org/)
上の画像は、Guided Backpropagationというものです。これは、GRAD-CAMの前に提唱された手法で、出力(y)から入力(Input)を逆にたどって(Backpropagation)、AIが注目した特徴をピクセル単位で取り出す技術です。上の画像をよく見ると、猫と犬がうっすらとスケッチされているのがわかりますね。
Guided Backpropagation(上の画像)とGrad-CAM(下の画像)を合わせたものがGuided Grad-CAM(左の画像)です。重ねることで猫と判断した際に注目(Attention)した特徴(猫のフォルムと横じま)が浮き彫りになり、「なるほど、この写真からこういうふうに特徴をつかんだから猫と判定した」ということがわかります。
Guided Grad-CAMは、CNNがどこにどう注目したからこう判定したというプロセスを知る有効手段です。間違った判定をした場合にどうして間違ったかも追えるので、分類器の精度向上に役立てることもできます。ただし、異常検知ではおおよその異常の場所がわかればいいので、Grad-CAMでヒートマップを出すことでこと足ります。
まとめ
今回は、正常データと異常データの両方を学習する外観検査では畳み込みニューラルネットワーク(CNN)が用いられることと、正常データのみ学習する方法と比べて高い再現率で異常を発見できることを学びました。でも、現場はそんなに単純ではなく、いざ、実施しようとすると大きく4つの課題があることや、異常個所を特定するのにGrad-CAMという技術があることも理解できましたね。ついでにホテリング理論はデートのハウツーではないことも覚えておいてください。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano













