ここからは、製品の品質検査(外観検査)をテーマとしてディープラーニングをどのように活用するか解説します。まずは、機械学習の5つの学習モデルや機械学習の仕組みを理解しましょう。その上で、カメラで撮影した動画をどのように機械学習して異常検知(Anomaly Detection)するのかという全体構成を掴んでみたいと思います。

機械学習の学習モデル
異常検知のモデルを考えるにあたり、図1に示す5つの学習モデルの違いを知っておく必要があります。実は、異常検知システムを作るのに、これらのどのモデルを使うかという選択肢は非常に幅広いからです。以下、簡単に各モデルの仕組みと異常検知との関係を簡単に解説します。それぞれの学習モデルの詳細な内容について興味のある方は、ブログ「AIをぱっと理解する」の各章をご覧ください。
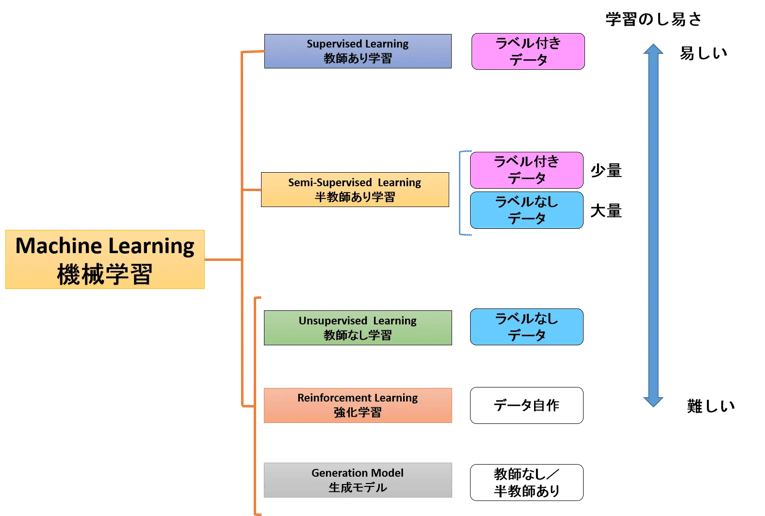
図1:機械学習の学習モデル
(1)教師あり学習
教師あり学習は、図2のような学習処理と判定処理の2つのプロセスに分かれます。学習プロセスでは、大量の学習データにラベル(正常品か不良品か)を付けた上でAIに学習させます。このように、学習データにラベルを付ける作業をアノテーション(Annotation)と言います。
学習は1回で済むわけではありません。何回も繰り返してトレーニングした結果「あ、さっきまではわからなかったけど今ならわかるぞ」というように認識精度が高くなるのです(人間と一緒ですね)。そして、目標に定めた精度で正常・異常の判定ができるようになれば訓練終了です。機械学習の訓練方法にはいろいろテクニックがあるのですが、そのあたりに興味ある人は機械学習の仕組みをご覧ください。
判定プロセスでは、訓練が終わった分類器(学習済モデル)を異常検知システムに用いて、検査対象(未知のデータ)を読み取り、正常品か不良品かを判定します。こんなふうにラベルを付けて事前訓練する学習プロセスがあるのが教師あり学習モデルです。
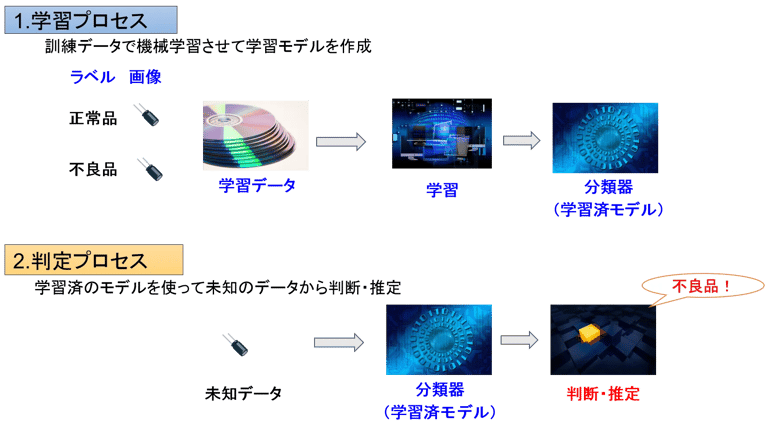
図2:機械学習の2つのプロセス
(2)教師なし学習
教師なし学習も、事前に学習を行います。ただし、教師あり学習とは違って正常品、不良品のラベルを付けずにひたすらデータを読み込む感じです。大量に読み込んだデータのサイズや色(RGB)などの要素で分布図を作り、分布から外れた値のものは異常なのではと判定するのが外れ値検知(Outlier Detection)になります。教師なし学習のクラスタリングというアルゴリズムについては、教師あり学習と教師なし学習をご参照ください。
(3)半教師あり学習
全てのデータにラベルを付けるのではなく、少量のデータにラベルを付けることで大量のラベルなしデータを活かすモデルが半教師あり学習です。ブートストラップ法や混合ガウスモデルなどのアルゴリズムがあり、ラベル付きデータだけだと疎ら(data sparseness)になってしまうのをラベルなしデータが補う考え方が基本になります。なお、異常検知においては、正常データのみ学習するといった方法が用いられることも多く、本来の半教師学習とは違うのですがこれを半教師学習と呼ぶこともあります。
(4)強化学習
AIが報酬を得るために自ら学んで賢くなる学習法が強化学習です。囲碁棋士を破ったアルファGoや株取引などで活躍する注目度の高いアルゴリズムですが、異常検知では今のところあまり出番がないようです。このブログでは解説しませんが、興味のある方は強化学習とバンディットアルゴリズムやQ学習をご覧になってください。
(5)生成モデル
ディープラーニングには、識別モデル(Discriminative Model)と生成モデル(Generative Model)があります。花の名前を見分ける、正常品と不良品を見分ける、癌の兆候を早期発見する、などは識別モデルで、本物そっくりの写真や映像を作るなど、データをもとにオブジェクトを作るのが生成モデルです。普通に考えれば、異常検知は識別モデルの独壇場と思われますが、実は生成モデルも正常データだけ学習するケースにおいて重要な役割を果たします(次回、解説します)。
生成モデルの方法としては、オートエンコーダーやGANなどが有名です。このブログの中では、これらを技術を使った異常検知を解説していきます。
品質検査モデル
異常検知(品質検査)も学習プロセスと判定プロセスに分かれます。それぞれについてベルトコンベアのモデルを使って説明しましょう。
(1)学習プロセス
図3は、ベルトコンベアの上を流れてくる製品(コンデンサ)の動画をもとに、品質検査を行うモデルの学習プロセスです。このような外観検査モデルにおけるポイントを順に説明します。
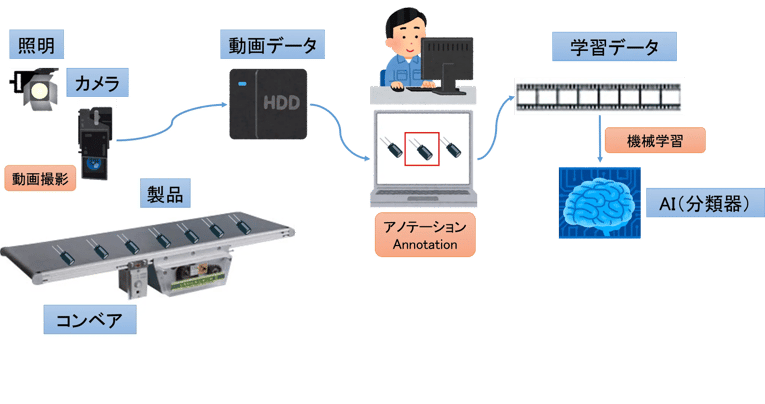
図3:品質検査モデル(学習プロセス)
動画撮影
ドローンで橋梁を撮影するのも、コンベアで流れてくる製品を撮影するのも、もとのデータは動画となります。動画を撮影する際にポイントとなるのがフレームレートと呼ばれる値で、単位はfps(frames per second)です。実は動画は静止画の集まりであり、基本原理はパラパラめくる漫画と一緒です。fpsは1秒間に何コマあるかを示す値で、fpsが大きいほど滑らかな動きに見え、少ないとカクカクした感じになります。
地上デジタル放送は30fps、映画は24fpsとなっています。しかし、異常検知の撮影では滑らかな動きに見える必要はなく、確実に対象オブジェクト(ここではコンデンサ)が1コマ(フレーム)に収まっていればいいので、通常は1~3fpsくらいで設定します。
アノテーション
動画の場合、1コマ1コマに写っている対象オブジェクトを指定して、ラベル(正常品or不良品)と位置(物体を囲む矩形の座標)を付ける作業がアノテーションとなります。コンデンサ以外に抵抗器やダイオードなども流れてくる場合は、そうした種類もラベルとして指定します。
アノテーションは地味で面倒くさい作業なのですが、これを簡単にできる便利なアノテーションツールがたくさん出回っています。例えば、dlibと呼ばれるオープンソースの画像処理ライブラリの中にあるimgLabや、Githubで公開されているlabelImgというアノテーションツールなどがよく知られています。次々と新しいツールが登場しており、アノテーションツールリストもネット上で紹介されていますので、良さそうなものを選んで作業を行ってください。
機械学習
機械学習を使った異常検知でよくぶつかる問題は、不良品のデータがそうやたらにないということです。もともとAIを使った外観検査を考えてなかったわけなので、わざわざ不良品の画像を撮っておいてないケースが多く「異常データなんてないよ」って言われてしまうのです。
まあ、それでもそこそこ不良品が発生するのであれば、一定期間動画を撮ってデータを蓄積しておいてから、そこに含まれる不良品に不良ラベルを付けて学習させることは可能でしょう。でも、歩留まりが良くてめったに不良品が発生しない現場では、正常品だけを学習する方法もよくとられます。
実は、正常品だけ学習する方法と正常・不良の両方を学習する方法とで使うアルゴリズムも異なるのですが、その辺りの仕組は次回説明します。
(2)判定プロセス
図4は、学習プロセスで学んだAI(分類器)を使って、流れてくる製品の異常を検知する判定プロセスです。おおまかな仕掛けは学習プロセスと一緒ですが、いくつか違う点がありますので、そこを中心に説明しましょう。
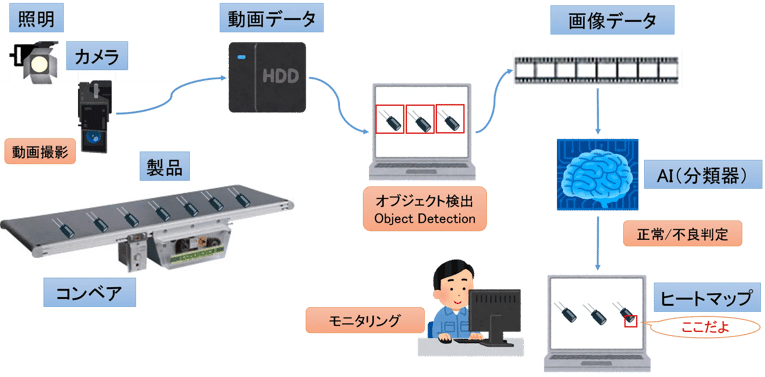 図4:品質検査モデル(判定プロセス)
図4:品質検査モデル(判定プロセス)
動画撮影
学習プロセスの動画は、撮り貯めした動画データを後からアノテーションする想定でしたが、判定プロセスではリアルタイムに判定して不良品が完成品に流れ込んでしまないようにしています。
オブジェクト検出
AIの記事などで、写真の中の人や自動車などのオブジェクトに四角い矩形を付けた画像を見たことあるでしょうか。これは、AIが写真の中のオブジェクトを認識して、これは人、これは自動車というようにラベルを付けてくれているわけです。このように人間がアノテーション作業でラベル付けするような作業を、AIが自動的にやってくれるのがオブジェクト検出(Object Detection)です。
アノテーションツールと同様、オブジェクト検出ツールもいろいろ出回っています。例えば、Googleの機械学習ライブラリTensorFlow(テンソーフロー)に基づいて構築されたオープンソースのオブジェクト検出ツールObject Detection APIを使うと、画像の中からオブジェクトを認識してラベル判定&座標取得をやってくれます。
ただし、Object Detection APIもディープラーニングのライブラリなので、事前に学習させる必要があります。動画のコマ画像に対してアノテーションツールでラベル(コンデンサやダイオードなど対象オブジェクトの種類)とオブジェクトの位置(矩形座標)を取得し、それを学習データとしてトレーニングするうちに自分でオブジェクトの種類と位置を検出できるようになるわけです。
画像認識(Classification)は写真全体が何なのかを認識するだけですが、オブジェクト認識(Object Detection)は写真の中の1つ1つのオブジェクトを個別に認識して「これだよ!」と四角いマークを付けてくれます。(図5の左上と右上)。 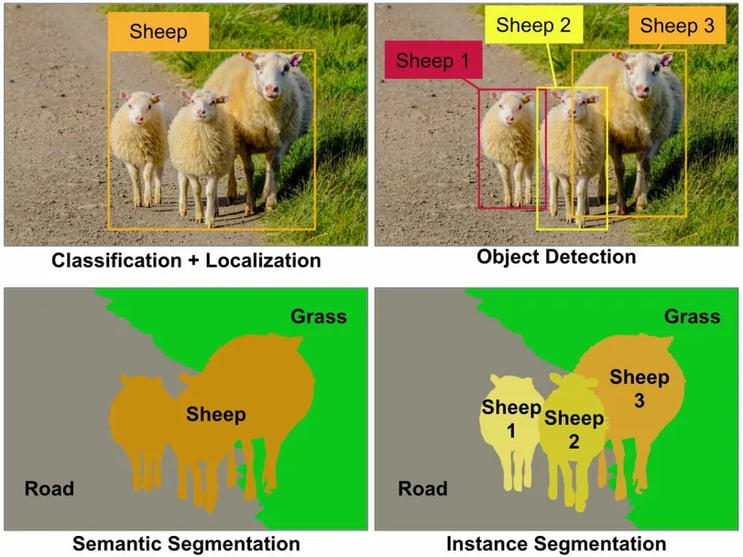
出展:https://www.oreilly.com/ideas/introducing-capsule-networks 図5:セマンティックセグメンテーションとインスタンスセグメンテーション |
正常/異常判定
オブジェクト検出で取り出した1つ1つの画像データを見て、図3で学習したAI(分類器)が正常品か不良品かを判定してくれます。AIが不良と判定したものは、どの製品が不良か、どこを不良と判断したかなどを印し(ヒートマップ)を付けたりして人がすぐに確認できるようにしたり、アクチュエータ(操作器)と連携して自動的に取り除いたりします。
【麻里ちゃんのAI奮闘記】 精度と正解率の違い

| 麻里:人工知能君は、不良品を人間よりスパッと見分けられるのですか? 先輩:う〜ん、どうかなぁ。人間よりも精度が高いといった事例も多く発表されているけど、人間と同程度になったというところかな。でも、人間が見落としがちなものを拾ってくれる効果は大きいと思うよ。 麻里:精度ってパーセンテージで出るんですよね。 先輩:うん、そうなんだけど、その前に精度って言葉の定義を理解しておく必要があるよ。 麻里:え、精度って…精度ですよねぇ…。 先輩:ふふ、それがそう単純じゃないんだ。厳密に定義すると、図6のように正解率、再現率、精度、調和平均の4つに使い分けられるんだ。 麻里:へっ、4つもあるんですか? 先輩:1000個のうち不良品が4個ある例で説明しようか。その場合、分類器がどう判定するかの組み合わせは表1の4通りになるだろう? 麻里:あ、そうですね。 先輩:正解率は単純に”全データに対する”正解した数の割合なので、(980+3)/1000=98.3% となる。 麻里:これは簡単ね。 先輩:で、再現率と精度は全データではなく”不良品に分類したデータ”に対する評価となるんだ。 麻里:なるほど〜。じゃあ、再現率は”不良品のうちいくつ不良品と認識できたか”なので、3/4=75%となるのね。 先輩:うん。そして精度は、”不良品に分類したうち、いくつ本当に不良品だったか”なので、3/(16+3)=15.8%になる。 麻里:ほうほう。 先輩:異常検知の場合、大事なのは不良品の再現率なので”怪しいものは罰する”という姿勢で閾値を設定するんだけど、そうすると精度は下がってしまい正解率も下がることになる。 麻里:再現率と精度はトレードオフの関係なんですね。 先輩:そのため、再現率と精度を統合して評価する調和平均(F値)という指標もある。両方をバランス良く高めるときは、F値に注目して分類器を調整することになる。 麻里:ラーメン食べたいけど、チャーハンも食べたい。じゃあ、中華の神メニューの半チャンラーメンにしようって感じですね。 先輩:麻里ちゃん、例えがめっちゃおっさんくさいよ。なおかつ古~い。半チャンラーメンって、今は絶滅危惧種になっているよ。 麻里:え、でも私、まんぷく屋の半チャンラーメン大好きなんだけどなぁ…餃子とビールも付けたら最高よ! |
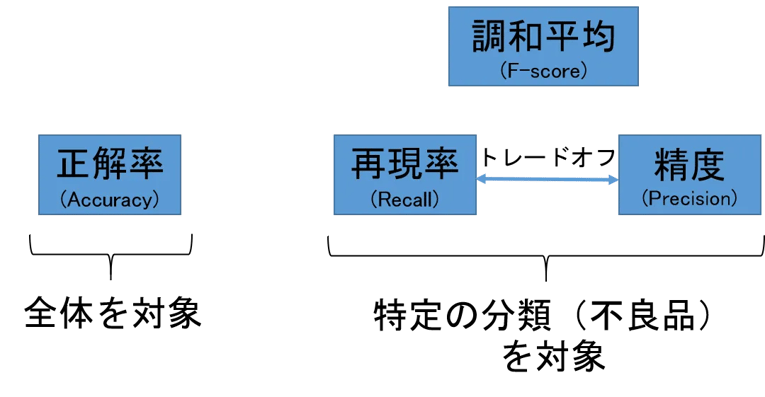
図6:精度と再現率
正解率:(980+3)/1000=98.3%
不良品の再現率:3/4=75%
不良品の精度:3/(16+3)=15.8%
調和平均(F値):2☓再現率☓精度/(再現率+精度)= 2☓75☓15.8/(75+15.8)=26.1
| 正常品(996個) | 不良品 (4個) | |
|---|---|---|
| 正常品に分類 | 980 | 1 |
| 不良品に分類 | 16 | 3 |
表1:分割表 (赤字は誤り)
ヒートマップ
分類器は、動画から切り出されたコマのうち、どのコマ(フレーム)の、どのオブジェクト(製品)を不良と判定したかをヒートマップ(赤枠など)で印しを付けてくれます。製品全体でなく、どの部分を異常と判定したかまでピンポイントで印しを付けてあげればさらに効率的に確認ができます。
モニタリングとアクティブラーニング
人間は、AIが不良品と判定した画像を確認して、本当に不良品なのかどうかを確認したり、不良品をラインから取り除いたりします。AIが一次判定してくれることにより、複数の検品ラインを1人で同時にモニタリングするなどの省力化も図ることができます。
AIの判定が誤っていたものを人間が訂正した場合、その訂正データは貴重な追加学習の種となります。こうした訂正データを蓄積して、運用しながらAIを追加学習する仕組みをアクティブラーニングと言います。

まとめ
異常検知の全体イメージがつかめましたでしょうか。動画の原理がパラパラ漫画であること、オブジェクト検出や分類器は、予め学習プロセスでトレーニングする必要があること、学習プロセスではアノテーションが必要であり、便利なアノテーションツールが出回っていること、AIが異常と認識した箇所はヒートマップで印を付けること、半チャンラーメンに餃子とビールを付けた鉄板メニューは不滅だということ、などが理解できたと思います。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano