このブログは、「ディープラーニングを使った異常検知」を現場で実用化するための連載です。異常検知はAIが最も得意とする技術分野の1つです。社会のいたるところで異常検知に対するニーズがあり、市場も非常に大きい分野なので、さまざまな現場でpoc(Proof of Concept:概念の実証)が取り組まれており、着実に実用化も進んでいます。
これからも加速度的に実用化が広がり、Digital disruption(デジタル破壊)を巻き起こすと予想されている分野なのですが、そのわりには、実用的な情報、実践的な情報があまり出回っていません。そこで、このブログで異常検知に関していろいろ整理してお伝えしたいと思います。

さまざまな分野で利用される異常検知
一口に異常検知と言っても、利用される分野に応じて”異常”の内容がさまざまです。図1をご覧ください。医療の世界では、CTやレントゲン、心臓MRI、超音波エコーなどの画像による診断支援が盛んです。お医者さんが見落とすような早期の癌をAIがぱっと見つけてくれるような事例があちこちで発表されています。農業でも、セスナやドローンからの空中映像や衛星画像を高解像度画像処理し、生育マップを作成して生育不良の場所を知らせる運用が行われています。また、農作物の規格外判定やサイズによる仕分け、虫食いなどの検査などに、AIを使おうという試みがなされています。
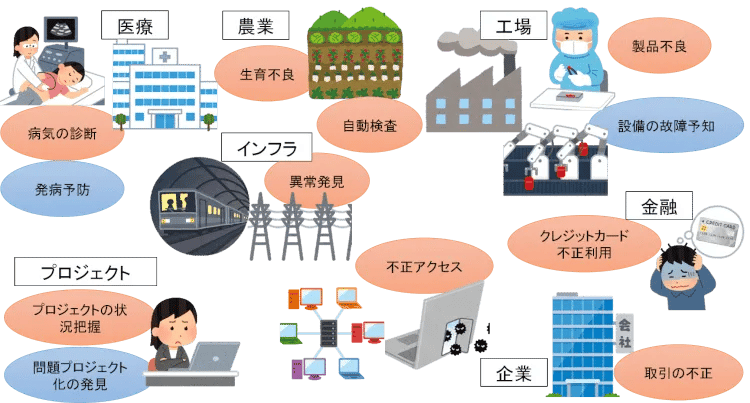
図1:さまざまな分野で利用される異常検知
高度成長期のインフラの老朽化が社会問題になっている中、鉄塔やトンネル、線路、橋、道路、壁といった設備の異常検知も取り組まれています。ドローン映像を使ってひび割れ、ボルトのゆるみ、空洞などの異常を判断できれば、人が高い鉄塔に登ったり、橋の下にもぐったりする必要もありません。ドローンの進化とともに実用化が大いに期待されています。
日本の産業を代表する製造業でも、これまで人に頼っていた目視検査をAIに置き換える動きが広がっています。また、製品不良だけでなく、生産設備や装置の異常をいち早く発見して故障によるトラブルを未然に防ぐ、いわゆる予知保全へのAI導入も盛んに行われています。
異常の判断は画像や音声データとは限りません。、IT企業やプラントなどプロジェクト型のビジネスを行っているところでは、PMO(Project Management Office)の役割を支援するために、プロジェクトの健康状態を判断したり、このままいくと失敗すると思われるプロジェクトを早期に検知するようなAIの登場が期待されています。
クレジットカードの世界では、人工知能が不正利用を検知することがよく知られていますし、それを企業に応用して不正な取引や経費の不正使用を見張るようなトライもなされています。企業ネットワークへの不正アクセスやサイバー攻撃監視、社外送信メールからの情報漏洩監視などにAIを利用する取組みも盛んに行われています。
異常検知と予知保全
もう1つ、異常検知と予知保全の違いについても抑えておきましょう。図2は、この2つの違いを示したものです。現在すでに異常が発生している状態を発見するのが異常検知(Anomaly Detection)、異常の予兆をつかんでこのままいったら故障するのを予測するのが予知保全(Predictive Maintenance)です。異常検知という言葉の中に、こうした予知保全も含まれていることが多いので、この2つの違いを理解した上でとちらを対象にしているのか判断してください。

図2:異常検知と予知保全
さらに、別の角度で設備異常と製品不良でも分けられます。橋や壁、トンネルなどのひび割れや製造装置、機械などの設備の異常状態を見分ける設備異常に対し、ベルトコンベアに流れてくる製品や収穫物の規格判定などプロダクトの品質検査で見つけるものが製品不良です。
図2のように4つのカテゴリーに分けるのは、私が単なる分類好きだからではありません。どのカテゴリーの課題に向き合うかによって、適用するディープラーニングや機械学習のアルゴリズムが変わるからです。例えば、ドローンの画像を使ってインフラのひび割れを発見するのは画像データをもとにしたCNN(畳み込みニューラルネットワーク)が用いられますが、製造設備の故障を予知する場合は音や振動などのセンサーデータをもとにした時系列モデルの変化点検知などが有効になります。
実は、図1でも、ベージュが現在でブルーが未来というように異常検知(現在)と予知保全(未来)の要素を入り交えていました。異常検知というテーマはとても幅が広いので、自分が向き合うのがどんな分野の(図1)、どのような課題を(図2)解決するものかを整理してから腕まくりする必要があるのです。
異常検知システムの仕組みを解説するためには、適用範囲とモデルを明確にする必要があります。このブログでは図2の赤枠で囲った範囲、すなわちディープラーニングを使って製品不良の異常検知を行う仕組みに的を絞って解説することにします。
【麻里ちゃんのAI奮闘記】 異常検知って英語で何と言うの?

|
麻里:せんぱい、異常検知って英語でどういうんですか? |
異常検知を3種類の手法で分類する古典的な分け方もよく用いられます。機械学習アルゴリズムが主流だった頃の分類方法で、ディープラーニングの時代となって手法が多様化した今ではちょっと古い分け方だと感じています。 ①外れ値検知 ②変化点検出 ③異常状態検出 |

機械学習とディープラーニングの違い
ブログ「AI技術をぱっと理解する」で機械学習とディープラーニングの違いとして次の3点を説明しました。
定義1:ディープラーニングは、機械学習の一部である。
定義2:ディープラーニングは、機械学習の中で隠れ層が多層化して深くなっているもの。
定義3:機械学習はルールベースの計算で、ディープラーニングはブラックボックス。
このうち定義3はとても重要です。機械学習は数学であり統計学ですが、ディープラーニングは相手が人間のようなものと考えて対峙することが肝要です。異常検知システムを作る際に、どの技術・アルゴリズムを使うか選択する上で、この違いを理解しておく必要があるので覚えておいてください。
構造化データと非構造化データ
AIを使った異常検知を行う上で、もう1つ抑えておくべき重要なことがあります。それは構造化データと非構造化データの違いです。図3をベースに説明しましょう。世の中の事象は基本的に非構造化データです。それをリレーショナルデータベース(RDB)やExcel、CSVファイルのような構造化データにするのはなぜでしょうか。
それは、コンピュータ君のためなのです。コンピュータ君は構造化データに対してはめっぽう強く、高速に計算できてかつ正確です。1980年代に世の中の事象がどんどん構造化データになり、コンピュータが大活躍する時代が訪れたわけです。
1990年代になると、非構造化データに規則性を持たせたHTMLやXMLなどのデータが誕生しました。こちらは、インターネット君のためです。非構造化データに規則を持たせることでインターネット君が処理できるようになり、デザインというややこしい対象でも、きれいに表示してくれるようになったのです。
残ったものが、言語や画像などの非構造化データの規則性なしです。これらはコンピュータで処理しにくいものだったので、仕方がなく人間が処理していたわけです。しかし、2012年にディープラーニングが脚光を浴びてから、これらの”人間くさい処理”をAI君がやれるようになってきています。
AIを使って何かやろうと考える場合に、こうした関係性を理解しておくことは重要です。構造化データとして取り扱えるのであれば、そこにAI君の出番はありません。コンピュータ君にやらせた方がずっと速くて正確です。この関係は機械学習とディープラーニングでも同じです。異常検知を行うのにルールベースの機械学習で行うのか、人間くさい処理が得意なディープラーニングを用いるかをよくよく見極める必要があるのです。
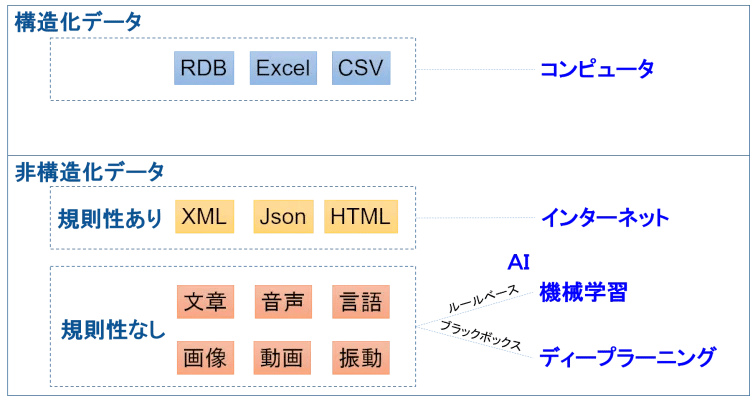
図3:構造化データと非構造化データ
まとめ
異常検知のブログ連載を始めるうえで、まず、抑えておくべきことを中心に解説しました。一口に異常検知といっても、さまざまな分野での適用があり、異常検知と予知保全があり、設備異常と製品不良があること。そして、異常検知の3つの古典的な分類法のほか、ルールベースの機械学習と人間くさいディープラーニングという大きな分類もあること。さらに、納豆に砂糖と味噌を混ぜて食べるとおいしいこと(私は子供の頃こうやって食べていました)など理解できましたでしょうか。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano