近年、機械学習による異常検知システムの開発が進んでいます。日本の製造業は世界的に見ても優秀ですが、少子高齢化や後継者不足といった課題に直面しているのが現状です。国家の危機ともいえる大きな課題を解消するために、機械学習による異常検知システムが注目を浴びています。
今回の記事では、機械学習における異常検知の手法や学習モデルなどをご紹介します。異常検知の自動化を検討している方は、ぜひご一読ください。

異常検知とは?
異常検知とは、「蓄積された大多数のデータと比べて、振る舞いが異なるデータを検出するための技術」です。
「簡単な異常の検知」から、人が認識するのは不可能な微細な変化や機器が故障する前の前兆といった「難しい異常の検知」まで、様々な異常検知が可能です。活用される分野には、クレジットカードの不正使用検知、システムの故障検知、異常行動検知などがあります。
この異常検知を特に必要としている分野のひとつに、製造業があります。
近年はグローバル競争が激化しているおり、品質や生産性のさらなる向上が求められています。しかし34歳以下の就業者の割合は24%程度と(※)、人手不足も深刻な問題になっているため、システムの活用に注目が集まっているのです。
次章では、異常検知の手法について説明します。
関連記事:製造業におけるディープラーニングを活用した異常検知のメリット
(※)第1節 デジタル技術の進展とものづくり人材育成の方向性|経済産業省

異常検知の代表的な手法

異常検知に使われる学習手法は様々あります。今回は代表的な3つの手法をご紹介します。
ホテリング理論
異常検知の手法のなかでも代表的なのが、統計モデルに基づく技術「ホテリング理論」です。ホテリング理論は、外れ値を検出する最も基礎的な方法として広く利用されています。
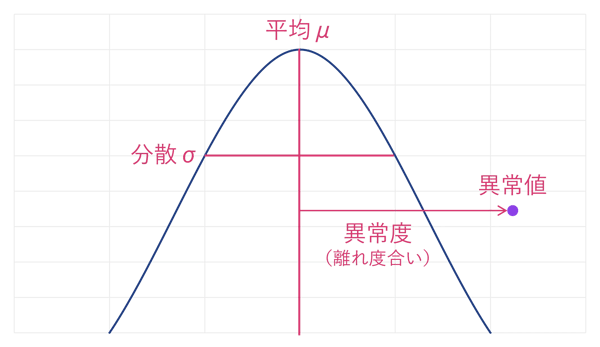
この手法では、平均や分散といったデータの正規の分布情報から外れる異常値を、観測値(x’)から算出した異常度(a(x’))を用いて検出します。
その際、使用するデータが正規分布であることを、ヒストグラムなどを使用して確認しておくことがポイントです。データセットの正規分布が著しく外れている場合は、異常値を正しく判断できなくなってしまうからです。正規分布でない場合は、対数変換やボックスコックス変換などをかけて正規化する必要があります。
ホテリング理論は以下の手順で進めます。
- 対象のデータが正規分布の定義に従うと仮定する
- 正規分布の平均μと分散σを推定する
- データの異常度a(x)を定義する
- 異常判定の閾値を設定する
ではここから、ほとんど異常値が含まれていない1次元のデータを使う場合を例に説明します。
この観測データが、以下の式で表される確率密度分布に従うと仮定し、正規分布を定義します。
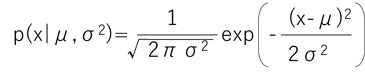
正規分布の母数である平均μと分散σは直接観測できませんが、観測値{x1,x2,…,xn}が与えられると、最尤推定法を使うことで以下の数式で推定できます。
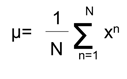
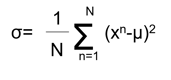
以上の計算式から正規分布が推定できたら、平均値を中心とした正規分布における平均からの離れ度合いとして、異常度a(x)を次のとおり定義します。
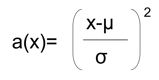
この計算式の分子では、対象のデータが平均μから離れるほど異常度が高くなることが表され、分母ではデータがどのくらい分散しているかが分散σによって表されています。これによって、分散しているデータであれば平均から離れていても異常として判定されない許容範囲が広がり、逆に密になっているデータでは少しでも平均から離れていれば異常として判定されます。
正常・異常の判定基準となるこの閾値を設定する際によく使われるのが、分位点を設定する手法です。たとえば分位点を2%とした場合は、先述の式から導き出した観測データから異常度のうち2%が異常と判定されます。つまり全観測データが100件あった場合、異常度を降順に並べて上から2%=2番目の異常度を閾値として設定することになります。
これは簡単に使える手法ですが、分散した観測データには向いていません。その場合、異常度の確率分布から閾値を設定する手法が使われます。
ホテリング理論は異常値の検出に使われる代表的な手法ですが、問題点もあります。ここでは主な問題点を2つ挙げます。
1つ目は、正規分布の山が複数あるデータでは正確に異常値を検出できないことです。ホテリング理論は単一の正規分布に従うデータに対して有効な手法ですが、分布の山が2つ以上ある場合、特に似た大きさの山が複数ある場合には適用が難しくなります。
2つ目は、局所的な変化を検出できないことです。ホテリング理論はデータの大域的な変化を検出するには有効ですが、例えば一定のデータに対して局所的に異常値が発生した場合などは正しく検出できない可能性があります。
k近傍法
k近傍法は、分類に使われる手法のひとつです。
ホテリング理論ではデータが正規分布から生成されていると仮定するため、正常なデータが多数のクラスターからなる場合には異常値を取り除くことができません。そこで、確率分布を明示的に仮定しないk近傍法が用いられます。
k近傍法は、与えられた学習データをベクトル空間上にプロットしておき、未知のデータが得られたら、そこから距離が近い順に任意のk個を取得し、その多数決でデータが属するクラスを判定する方法です。
独立変数が2個しかない場合は、2次元上にデータをプロットできるので、より直感的に理解できます。
距離の定義には、3つの方法を用いることが一般的です。3つの方法については、順番に説明していきます。
ユークリッド距離
日常で用いられる距離で最も一般的なものです。
二次元以上の点同士の距離を表したものであり、計算方法は「差の二乗和の平方根」です。平面であれば2点以上の座標が求まれば、ピタゴラスの定義で表すことができます。
この距離が離れているかどうかによって、「似ている・似ていない」という判定につなげます。
マハラノビス距離
変数同士に相関があるときに用いられる距離です。
あるデータが母集団からどれだけ逸脱しているかを表し、その距離が大きいほど異常度が高いと判断できます。
マンハッタン距離
こちらも距離ですが、ユークリッド距離のような直線ではなく、マンハッタンや京都のような碁盤の目のような街を移動するときの距離です。どこを通っても最短距離は等しくなります。2点間を直線で進めないので、ユークリッド距離よりもマンハッタン距離の方が長くなります。
LOF(Local Outlier Factor)法
LOF法(局所外れ値因子法)とは、データの集まりの中から外れ値を見つけ出す「外れ値検知アルゴリズム」のひとつです。
あらかじめ閾値を設定するk近傍法と異なり、データの集積を空間における密度に置き換える手段に置き換える方法を取ります。こちらを局所密度といいますが、簡単に言うと他のデータとどれだけ距離が近いかということになります。データの距離が近い=「密」であれば正常、データの距離が遠い=「疎」であれば異常、という判断で、異常度を算出することが特徴です。

たとえば上の図で異常値をp、pに最も近い正常値をp’とします。このとき、p’にとって最も近い点はpではなくその下に位置するいずれかの点になります。そのためpから最も近い点との距離r(p)は、p’から最も近い点との距離r(p’)よりも大きくなります。
ここでpの異常値a(p)を以下のように定義し、1よりも大きい任意の閾値を設定すると、観測データがその閾値を超えた場合に異常値として検出されることになります。
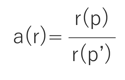
このLOF法は外れ値の検出が容易となり、特定の閾値や基準を設定しづらい複雑な要素で構成されるデータ分布に対して用いることができます。
ただし、LOF法には以下のような欠点があります。
- 疎密で異常を判断するので、膨大なデータが必要
- 近傍点までの距離を1点ずつ計算するため、計算コストがかかる
欠点はあるものの、k近傍法でうまく動作しない場合などに役立つことがあります。
以上に挙げた手法以外にも、異常検知の手法はたくさんあります。しかしながら、これら手法から最適なものを選択、使いこなして異常検知を実施するのは決して簡単ではありません。異常検知と機械学習の関係性

従来であれば、機械にセンサーを設置し、その値をもとに人間の目で正常・異常を判断していました。しかし近年では機械学習によって人間と同じレベルでの判断が可能になってきています。
機械学習を異常検知に用いるメリットは、大きく3つあります。
- 業務効率の改善
- ヒューマンエラーの発生防止
- 属人化の防止
上から順番に説明します。
業務効率の改善
たとえば、人の目で製品のチェックを行う目視検査よりも、AI搭載の外観検査装置を活用した方が検査の速度は速くなります。
目視検査は、検査員が多ければ多いほど人的コストが発生します。しかし現在はものづくりにおいて高い品質が求められており、品質を維持したり不良品の流出を防いだりするためには厳密な検査体制が求められます。単純にコスト削減のために検査員を減らしても、結果として品質低下を招きかねません。
AI搭載の外観検査装置を導入すれば、検査員を最小限にできるうえに過剰な人員を生産工程へ配置するなど、業務効率の改善が期待できます。
ヒューマンエラーの発生防止
機械学習の活用により、ヒューマンエラーを防止することも可能です。
目視検査は人が行っているので、誤って不良品を流出させたり良品を不良品と判定(オーバーキル)してしまったりすることもあります。人の検査精度は体調や精神状態といったコンディションが大きく影響するため、ミスを完全にゼロにすることは困難です。
しかし、AIを搭載した外観検査装置を導入することで、目視検査よりも高い精度で、なおかつコンディションなどに影響されず異常を検知できるようになるのです。
属人化の防止
人による外観検査の精度は、長年の経験による場合も多くあります。経験を積むほどにノウハウが確立されるので、熟練の検査員は新人の検査員と比べて検査の精度は高くなります。しかし、その熟練検査員たちが定年や転職などで退職してしまうと、現場には経験の浅い検査員しか残りません。
経験の浅い検査員ばかりになってしまうと、不良品の見逃しや判定ミスといったヒューマンエラーが発生する場合もあります。また、経験によるノウハウの習得はマニュアル化しづらい部分も多く、熟練検査員の技術継承も簡単ではありません。
熟練検査員の経験をAIに学習させることで、高い精度を保ったまま、属人化を防止することもできます。
異常検知に用いられる機械学習のモデル

そもそも機械学習とは、人や動物が経験から学ぶことをコンピューターが大量のデータから学習する技術のことです。人工知能の一種であり、アルゴリズムは学習用のサンプルが多いほど適応して性能も高くなります。
製造業ではディープラーニング(深層学習)が使って異常検知を行うことが一般的です。ディープラーニングについては、以下の記事でも詳しく解説しているので、ぜひあわせて参考にしてみてください。
製品の異常検知_Anomaly Detection (Vol.2)
また、以下は、異常検知に用いられる機械学習の5つのモデルです。
- 教師あり学習
- 教師なし学習
- 半教師あり学習
- 強化学習
- 生成モデル
それぞれ、順番に説明します。
教師あり学習
教師あり学習は、2つのプロセスに分かれることが特徴です。
- 学習プロセス
- 判定プロセス
学習プロセスでは、大量のデータに正常、異常といった判定(ラベル)を付けます。学習は一度だけでなく、人間のように何度も反復して学習させて認識制度を高めます。正常・異常を判定する精度が目標に達した時点で訓練を終えるのです。
一方の判定プロセスは、すでに訓練が終わった学習済みのモデルを異常検知システムに搭載して、検査対象の製品を検査して正常か異常かを判定します。
つまり、教師あり学習モデルは事前にラベル付けを行う必要があるモデルなのです。
教師なし学習
教師なし学習は、正解のラベルを必要としない学習手法です。
事前に学習を行う点は教師あり学習と共通していますが、事前のラベル付けは行いません。正常データを学習させてモデルを作成し、このモデルから外れたものを異常と判断するのが教師なし学習です。
また類似性や規則性を分類することで、正常データのモデルを自分で構築します。
正常データから外れた特徴を異常として判断するため、未知の異常を検出することに長けています。
半教師あり学習
半教師あり学習は、少量のデータにだけラベルを付けて、その他のラベルがない大量のデータを生かす学習手法です。ラベル付きデータが少量しかない場合やすべてのラベル付けが困難な場合にも、ラベルなしのデータを活用できる学習法です。
なお、異常検知では正常なデータだけを学習する方法が多いので、便宜上この手法を半教師なし学習と呼ぶこともあります。
強化学習
強化学習は、AIに報酬を与えて自発的に学んで賢くさせる手法です。
たとえば、試行錯誤を繰り返して最大化した利益を得るような方法は、強化学習に該当します。異常検知で採用される機会は少ないですが、株取引などでは活用されることの多いアルゴリズムです。
生成モデル
生成モデルは、データからオブジェクトを作成していく手法です。
正常データや外れ値の検出が可能で、データをサンプリングすることができます。異常検出においては、正常データだけを学習するときに役立ちます。
生成モデルとしては、たとえばオートエンコーダーなどが挙げられます。
オートエンコーダー(VAE)とは?
オートエンコーダーは、ニューラルネットワーク(脳内にある神経回路の一部を模した物理モデルのこと)の一種です。
入力されたデータを一旦圧縮して、必要な特徴量だけを残したあと、再び元の次元に復元処理をするアルゴリズムです。小さい次元へと落とし込む作業は「次元削減」「特徴抽出」と呼ばれます。
オートエンコーダーについては、こちらの記事でも詳しく解説しています。
AI(ディープラーニング)×画像認識技術による異常検知

近年、異常検出にはシステムが用いられていますが、その中でも画像認識技術とAI(ディープラーニング)を用いたものが注目されています。
画像認識によって生産ラインを流れる部品や製品の動画データ、画像データをサーバーに蓄積し、AIがそのデータを取り込んで良品、不良品を判定していきます。人手不足やヒューマンエラーを解消するなど、異常検知システムの導入によって検査にかかる工数、時間、コストを大幅に削減できます。
AISIA-ADによる異常検知
AISIA-ADでは、以下の機能群を、AIテクノロジーを活用してクラウド基板上に構築することで、異常検知に必要な機能をオールインワンで提供します。
| 機能構成 | 機能概要 | 機能名 |
| オブジェクト検出 | オブジェクト検出学習支援 | 動画アノテーション |
| 動画オブジェクト検出 | 動画オブジェクトの検出 | |
| オブジェクトの種類判定 | ||
| オブジェクトの座標取得 | ||
| 正常・異常判定 | 動画オブジェクト同一判定 | 移動速度自動計測 |
| フレームスルー判定 | ||
| 正常・異常判定処理 | オンライン閾値調整 | |
| 移動多数決判定 | ||
| 正常表示・監視 | 異常箇所表示 | 生成モデルヒートマップ |
| 識別モデルヒートマップ | ||
| リアルタイムモニタリング | 同時多面監視 | |
| ワンタッチ訂正 | ||
| 学習処理 | 正常データ学習処理 | VAE生成モデル学習 |
| 最適ノイズ除去 | ||
| 正常・異常データ学習処理 | 転移学習/水増し | |
| 汎化処理 | ||
| 追加学習 | 訂正データ蓄積 | |
| 追加学習処理 |
弊社システムインテグレータが提供するAISIA-ADは、ディープラーニング(深層学習)を活用した画像認識を搭載する最先端の異常検知システムです。
AISIA-ADは、製造現場で培った熟練の検査員の技術や経験をAIに学習させていることから、高い精度で不良品を検出することができます。肉眼での検出が困難なキズ、凹み、異物混入などの異常であっても、AISIA-ADなら高い精度での検出が可能です。
製造業の課題である人手不足の解消やヒューマンエラーの防止などに役立ちます。検査工程に割いていた貴重な人材は生産工程に配置することができるので、品質の向上にもつながります。
また、弊社は外観検査システムだけでなく、検査機、カメラ、照明などの検査装置も取り扱っていますので、トータルでのサポートも可能です。AIの知識を持つ人材が不在の企業様でも、業務効率を上げるお手伝いをさせていただきますので、お気軽にご相談ください。
まとめ
異常検知システムを導入することで、今まで人の目に頼っていた業務をシステムが担うことになり、結果として従業員の作業負荷軽減につながります。同時に、AIを活用することで、今までの課題であった問題点が改善されるメリットもあります。
異常検知に課題をお持ちの方や、システム導入を検討されている方は、お気軽に弊社までお問い合わせください。また、お役立ち資料も公開中ですので、お気軽にご活用ください。






