はじめに
前回は「教師あり学習」の「回帰」と「分類」、「教師なし学習」の「クラスタリング」について説明しました。今回は、もう1つの学習法である「強化学習」について、その代表的なアルゴリズムである「バンディットアルゴリズム」と一緒に説明します。
強化学習とバンディットアルゴリズム
強化学習は、教師あり学習のように「答え」が与えられるわけではなく、「報酬」を得るために自ら学んで賢くなる学習法です。囲碁や将棋のようなゲームで圧倒的な力を示しますので、”氷上のチェス”と呼ばれるカーリングを例に説明しましょう。
カーリングは4人チームで10エンド戦って合計点数の多い方が勝ちとなるスポーツです。エンドごとに先攻後攻があって後攻が有利なゲームなのですが、エンドに勝つと次のエンドは先攻になるため、わざと引き分けて後攻を続けたり、先攻の時は相手に1点だけ勝たせて後攻を得たりするなどの駆け引きもあります。ゲームの報酬は最終的に試合に勝つことですが、そのためにどのように戦うかという途中途中の戦術面が非常に大きい競技です。
通常、カーリングにはコーチがいます。8エンドで先攻で2点リードの時に取るべき作戦、第3投でこういうストーンの配置のときにどういう投球をすべきか、麻里ちゃんが投げる番だとして彼女の力量ならどうすべきか、など場面場面でコーチが最適なアドバイスを教えてくれるのが「教師あり学習」です。(本当のルールでは5エンド終了後の休憩時間とタイムアウト以外はコーチとの話し合いは認められていないですが)。
一方、「強化学習」はコーチがいません。エンド10の投球が終わって報酬(勝利)が得られなかったときに、じゃあ、その前のエンド9がどう悪かったのかを反省し、そこで取った戦術の見直しをします。エンド9の悪い原因がエンド8にある場合は、エンド8で採択した戦術を見直ししてこちらも改善します。このように、どうすればもっと報酬を得られるかを自ら反省して強くなっていくわけです。
囲碁や将棋、チェスでは対局が終了した後で対局者同士で感想戦を行って、お互いのどの手が悪かったかを話し合って最善手を追究します。強化学習はこの感想戦のような反省を自分自身で行い、その内容を記録しておきます。次の対戦では、その記録した内容を参考にしながら戦い、負けたらまた反省して記録を更新する。この作業を繰り返すうちにだんだん強くなってゆく学習方法なのです。
バンディットアルゴリズムとABテスト
強化学習で報酬を最大にする手法の1つにバンディットアルゴリズムというものがあります。実は、バンディットアルゴリズムは、強化学習がこれほど注目される以前からWebマーケティングでお客様により多くクリックしてもらったり、ゲームで勝つための手法としても使われていました。麻里ちゃんに登場してもらって、簡単に説明しましょう。
舞台はメイド喫茶でバイトしている麻里ちゃんとのじゃんけん勝負です。コインを50枚購入したので50回じゃんけんができます。コインを1枚出してじゃんけんをし、麻里ちゃんに勝てばコインは3倍になり、あいこか負けなら取られてしまいます。このほかにパスと言うことも可能で、その場合は1枚がそのまま手元に残ります。
50回じゃんけんして手元に残ったコイン数を分換算して、その時間だけ麻里ちゃんが席についておしゃべりの相手をしてくれます。この至福の時間(報酬)を最大化するために活用するのがバンディットアルゴリズムです。
人にはそれぞれ癖があって、麻里ちゃんはパーを出す確率が50%、グーが30%でチョキが20%です。もし、それを知っていたら最初からチョキを出し続けるわけで、その時の期待値は50回×0.5×3枚=75枚になります。そして全部パスなら50枚というわけです。
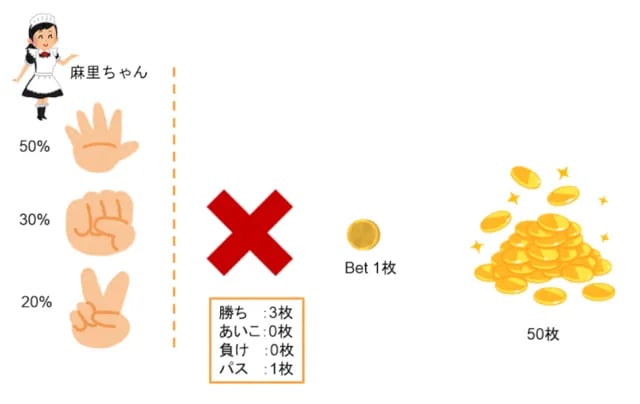
図1:麻里ちゃんとのじゃんけん勝負
(1)ABテスト
最初に、バンディットアルゴリズムを説明する際によく比較されるABテストを説明しましょう。ABテストは、パターンAとパターンBを用意して、どちらのパターンが効果が高い(報酬が大きい)かを調査するテスト手法です。eコマースサイトやWeb広告で使われる場合は、デザインAとデザインBのどちらがクリックされるか一定期間テストして、クリックの多かった方のデザインを採用するというように使われます。Facebookに広告を出すときにも、広告主が複数の広告セットを用意してABテストを行うことができますし、Facebook自身も新機能の評価検証にABテストをよく使っています。

麻里ちゃんとのじゃんけん勝負にABテストを使ってみましょう。最初に10回ずつグーチョキパーを均等に出して麻里ちゃんの癖を探索し、パーが一番多いと判断したら残り20回はチョキを出し続けることになります。この場合の期待値は、10回×0.5×3枚(チョキ)+10回×0.3×3枚(パー)+10×0.2×3枚(グー)+20回×0.5×3枚(チョキ)=60枚です。まずまずの成果ですね。
[RELATED_POSTS]このとき、最初の30回は麻里ちゃんの癖を見抜くための「探索」です。そして、パーが多いと思った後にチョキを出し続けるのが「活用」です。この「探索(Explore)」と「活用(Exploit)」はトレードオフの関係があります(図2)。癖をきちんと見分けるためには探索の数を増やさなければなりませんが、そうすると活用できる数が減ってしまうのです。
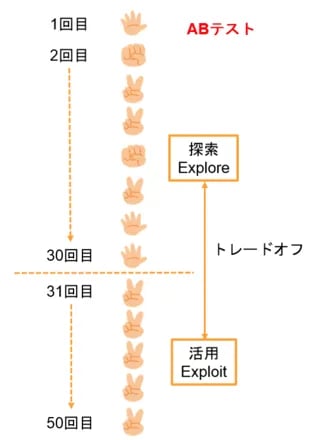
図2:探索と活用はトレードオフ
ABテストのウィークポイントは2つあります。
① 探索の際に確率の悪い手も均等に出さなければならない
② 探索の結果見つけた癖が正解じゃなかった場合に、同じ手を出し続けて大きな損失になる
先ほど、ABテストの期待値を60枚としましたが、正解を間違ってしまった場合を考慮するともっと低い値になるわけです(それ以前に活用で連続20回チョキ出し続けているのに、パーを出す麻里ちゃんも天然入っていますが…)。
(2)バンディットアルゴリズム
上記2つの課題を解決するための手法がバンディットアルゴリズムです。ABテストは一定期間の探索とその後の活用を完全に分けていますが、バンディットアルゴリズムはこの2つをミックスして探索しながら活用します。つまり「序盤からこれまで得た情報で活用しながら、適度に探索もし続ける」というもので、そのバランスの求め方の違いから次のような手法があります。
・Greedy
・UCB(Upper Confidence Bounds)
・Softmax
・Thompson Sampling
また、最初は探索を多く、徐々に活用の比率を上げるannealing(焼きなまし)という(これまた日本語訳が面白いですね)手法もあって、上記3つに焼きなましをミックスする手法も有力です。
Optimism in face of uncertainty
さてさて、世の中はそれほど甘くはありません。パチンコ台やスロットマシンのように、現実の世界では勝つ確率がわからないのが普通です。このメイド喫茶でも麻里ちゃんと生でじゃんけんできるわけではなく、端末のじゃんけんボタンを押すと麻里ちゃんの手がモニター上に同時表示されて勝敗が付きます。
当然のことながら、ちょっと負けが込むとひょっとしてシステムが”ズル”していて、きちんと1/3の確率で勝てる設定になっていないのではと疑心暗鬼が生じてきます(ゲーセンの脱衣麻雀ゲーム経験者なら、間違いなく疑います)。そんな心理状態になってしまった場合、確実にコイン1枚ゲットできる「パス」ばかり選択して、最適な正解(チョキ)にたどり着けなくなるジレンマに陥ってしまいます。
実は、そうならないための原理もあるんです。Optimism in face of uncertaintyについて説明しましょう。
最初に麻里ちゃんのチョキに何回かグーで勝ったとします。すると「お、グーが勝てる」と思ってグーを多めに出しますね。ところが、次第に負けが込んでしまうと、「あれ、グーはイマイチだった」と反省してグーを出すのをやめます。楽観的な勘違いは解消して別の選択に移れるのです。
一方、最初に麻里ちゃんのグーに何回かチョキで負けたとします。今度は「ああ、チョキは負ける」と思って、しだいにチョキを出さなくなってしまい、チョキが最適だと気付かずじまいになります。悲観的な勘違いは解消されず、最適な選択にたどり着けないのです。
このバイアスを解決するには少し楽観的側に倒す必要があります。それが、「不確定なときは楽観的な選択をする」という原理で、Optimism in face of uncertaintyと呼ばれています。方法はいろいろありますが、その1つが楽観的初期値法です。これは、例えば最初にグーチョキパーそれぞれで10回勝ったと初期値を与えてスタートします。序盤チョキで負けが続いたとしても、10回勝っているという貯金が働くので粘り強くたびたびチョキを出し、そのうちチョキで勝つことが増えて正解にたどり着けるわけです。
モンテカルロ法
ABテストの「探索」に関連する手法として、モンテカルロ法があります。カジノで有名なモナコの都市の名前がついていてなんだか凄そうですね。でも仕組みは至ってシンプルなもので、ランダムに試してみて、その結果から近似値を求めるシミュレーション法です。麻里ちゃんが出すグーチョキパーを集計していくうちに、パーが50%、グーが30%、チョキが20%という麻里ちゃんの癖が近似値として見えてくるのです。
生じゃんけんじゃない場合は、麻里ちゃんの手ではなく自分の手で統計を取ってみましょう。チョキで勝つ40%、パーで勝つ20%、グーで勝つ15%と合計が100%にならない近似値が出たとしたら、やっぱりイカサマじゃんけんだったんだとわかります。
まとめ
みなさんは座右の銘とかありますか。実は私はインタビューなどで座右の銘を聞かれたときに「迷ったときは積極的な道」と答えていました。この言葉は私のオリジナルなのですが、バンディットアルゴリズムのOptimism in face of uncertaintyという言葉に出会って「あ、同じだ」ってびっくりしまいました。ゲームに勝てるアルゴリズムですので、”人生というゲームに勝つ”ための大切な言葉だったんだと感慨深いです。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano









