はじめに
機械学習には「教師あり学習」、「教師なし学習」、「強化学習」という3つの学習方法があります。そして、その背後には「回帰」、「分類」、「クラスタリング」などの統計学があり、解を求める方法として「決定木」、「サポートベクターマシーン」、「k平均法」など多くのアルゴリズムがあります。
「学習方法」と「統計学」と「アルゴリズム」。いったいこの三角関係はどうなっているのでしょうか。まず、「学習方法」と「統計学」の関係から紐解いてみます。
機械学習法と統計学
まずは図1をご覧ください。「教師あり学習」、「教師なし学習」、「強化学習」という3つの学習方法と「回帰」「分類」「クラスタリング」といった統計学の関係をパッと図にしてみました。

図1:3つの機械学習法と統計学
教師あり学習と教師なし学習と強化学習
教師あり学習(Supervised Learning)は、学習データに正解ラベルを付けて学習する方法です。例えば、花の名前を教えてくれるAIを作るのなら、学習データ(画像)に対して、これは「バラ」、これは「ボタン」というようにラベルを付けて学習させます。何種類の花の名前を覚えるかが、Vol.5で学んだ出力層のノード数になります。
Vol.7で紹介したILSVRC(画像認識コンテスト)では、ImageNetという膨大な画像データセットの中から1000カテゴリーの画像を当てさせるお題を出しているわけなので、そこに参加する学習モデルは1000ノードの出力を持つモデルとなります。
どんなに優秀な学習モデルでも、習っていないカテゴリーは解答の選択肢にありません。ILSVRC2017の1000カテゴリーの中で、花はDaisy(デージー)しかないので、バラを見てもボタンを見てもデージーと答えるわけです。
一方、教師なし学習(Unsupervised Learning)は、学習データにラベルを付けないで学習する方法です。2012年にGoogleが猫を認識できるAIを作成したことが大きなニュースになったのは、それが教師なし学習だったからです。Web上の画像や動画をラベルなしで1週間読み取るうちに、AIが自律的に「猫」というものを認識するようになりました。これは、幼児が毎日いろいろなものを見るうちに、自然と「こういうものが猫ってものか」と認識してゆくのに似ています。
もう1つ、2016年にGoogleのAlphaGoというAIが韓国の囲碁プロ棋士を破ったという大きなニュースがありましたね。実は、これは強化学習(Reinforcement Learning)という別の学習方法を使って強くなりました。強化学習は、正解を与える代わりに将来の価値を最大化することを学習するモデルです。囲碁のように、必ずしも人間に正解がわかるわけではない場合でも学習できるので、人間を超える力を身につけることが期待されています。
回帰(Regression)
教師あり学習で使う代表的な統計手法は、回帰(Regression)と分類(Classification)です。回帰はVol.8でも簡単に説明しましたが、「たくさんのデータをプロットしたときに、その関係性を表す線(関数)を見出すこと」でしたね。これを予測に使った場合は、「これまでのデータを元に傾向(関数)を導き出し、今後の数値を予測する」というような使い方ができます。

例えば、コンビニが明日どのくらい弁当が売れるだろうという予測を正確に立てられれば、機会損失(品切れ)を避けつつ、ロス(廃棄処分)を最小限にできます。そこで図2のように過去3年の売上データを元に、そこに曜日、天気、気温、広告、イベント、前日何が売れたか、などの情報をかぶせて、どの因子要因がどれくらい影響するかを機械学習させます(教師あり学習)。3年前と2年前のデータで学習し、過去1年のデータでテストして相関関係が得られれば店長の発注を支援する「弁当売上予測AI」の出来上がりです。

図2:回帰を使った売上予測モデル
未来が予測できればすごいことです。まさに「世界は自分のもの!」という感じです。なので、こうした商品の売上予測以外にも来店者数予測、来場者数予測、電力需要予測などさまざまな分野で回帰を使った予測AIの作成が取り組まれています。いまは、まだ背伸びした事例発表が多いですが、近いうちに”本当の成功例”が次々と出て来ると”予測”しています。
分類(Classification)
教師あり学習のもう1つの代表的手法が分類(クラス分類とも言います)です。これは、その名の通り未知のデータを自動分類するもので、出来上がったものは分類器とも呼ばれています。はい、そうです。Vol.4で花の名前を教えてくれる人工知能(分類器)を作成していたのは、この分類という判別作業をディープラーニングを使って教え込んでいたわけです。
分類も幅広く人工知能で使われています。花の認識のように物体(Object)を見分ける画像分類(Image classification)の他にも、正常と不良を見分ける故障診断(Daiagnostics)や離れていきそうな顧客を検知する顧客維持(Customer Retention)など、さまざまな分野で使われています。
分類は古くから行われてきた人工知能の代表的な作業です。そのため、分類を行う機械学習アルゴリズムも数多くあり、ルールベースで分類する決定木(Decision Tree)や確率で表現するK近傍法などさまざまなものが使い分けられています。そして、特徴点を見つけて分類してゆく作業はディープラーニングも得意なジャンルなので、ルールベースで決まらない曖昧なものの分類にはディープラーニングが使われるようになりつつあります。
クラスタリング(Clustering)
クラスターという言葉はクラスター爆弾のせいでイメージが悪いですが、もともとは「房」とか「群れ」というような意味です。クラスタリングを一言で言い表すと、「いろいろなものの中から似たもの同士集めてグループ化すること」です。例えば、たくさんある花の写真から、「赤い花」「白い花」「青い花」など色で分類してグループ化するのがクラスタリングです。
例えばeコマースサイトの購買実績をもとに顧客をカテゴライズ(Customere Segmentation)してマーケティング手段を変えたり、顧客ごとにお勧め商品をレコメンド(Recommendation)したり、音や振動などのセンサー情報から平常と違う状態を早期に検知する予知保全(Predictive Maintenance)など、クラスタリングは大量のデータをもとにカテゴライズするのに適しています。少し前までよく名前を聞いたデータマイニングも基本的にクラスタリングをベースにしています。
分類とクラスター分析の違い
と、ここまで説明したところで、またまた麻里ちゃんが登場です。ちょっと嬉しいって顔をほころばせる間もなく、いきなりストレートな疑問をぶつけてきました。
「クラスタリングも分類することだよね。じゃあ、クラスタリングとクラシフィケーションはどう違うの?」
でた〜、素朴な質問ほど難しい! こういう質問を受けるとドギマギしますね。でも、落ち着いてもう一度図1を見れば、そこに答えがあります。確かに分類(Classification)もクラスタリング(Clustering)も同じく分類する作業ですが、次のように学習方法が大きく異なります。
分類(Classification) ・・・教師あり学習(目的変数あり)
クラスタリング(Clustering)・・・教師なし学習(目的変数なし)
花の色で花を分類する例で考えてみましょう。この分類をClassificationでやる場合は、写真(学習データ)に「これは赤い花」「これは白い花」とラベルを付けて学習させます。その際に「黒い花」を教えてなかったら、解答には「黒い花」は出てきません。目的変数(赤、白、青などの出力層のノード)に黒がないので、黒い花は認識できないのです。
一方、この分類をClusteringでやる場合は、ラベル付けは必要ありません。分類器は、花の色(RGB値)の違いを認識して「赤っぽい花のグループ」「白い花のグループ」というようにグループ分けします。黒い花が一定量あれば「黒っぽい花のグループ」も集められます。色の場合はRGBの3次元となるので、図3のようなイメージになります。  図3:クラスタリングによる色分け
図3:クラスタリングによる色分け
|
クラスタリングとは別にクラスター分析という言葉もあります。厳密に言うと、クラスタリングは分類すること自体を意味し、クラスター分析はクラスタの変化などを分析して有意義なことに役立てることを意味しますが、このブログでは特に区別しないこととしています。 |
表1に分類とクラスタリングの違いをまとめました。人工知能の活用は「教師あり」の分類の事例が多く登場しましたが、ここにきて学習データのラベル付け作業がいらなくて、学習データがない場合でも対応できる「教師なし」のクラスタリングもかなり実用化されてきています。今後は、それぞれに進化して役割に応じて使い分けられていくと思われます。
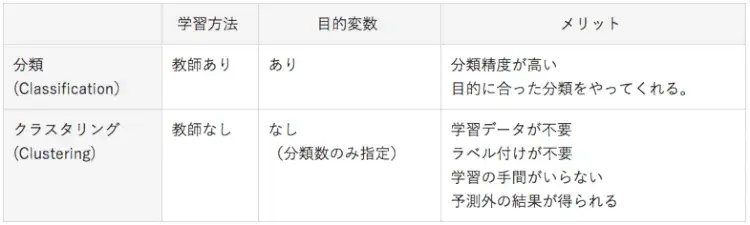
表1:分類(Classification)とクラスター分析(Clustering)の違い
まとめ
今回は「教師あり学習」「教師なし学習」「強化学習」という3つの学習法のうち、教師ありと教師なしに紐づく統計学「回帰」「分類」「クラスタリング」について説明しました。次回は、残りの「強化学習」と「バンディットアルゴリズム」について解説します。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano









