はじめに
2回にわたって教師あり学習について解説してきましたが、今回はいよいよ教師なし学習です。クラスタリングのアルゴリズムとして、k平均法と混合ガウス分布を抑えておきましょう。そして、麻里ちゃんが登場したことにより、次元の呪い、次元削減の1つの方法として主成分分析などについても説明します。
図1:3つの機械学習法と統計的手法(再掲)
クラスタリング(Clustering)
分類(Classification)もクラスタリング(Clustering)も同じく”分類”を行う機械学習処理です。クラスタリングのクラスタが房の意味でグルーピングと同義だということ、分類が教師あり学習なのに対しクラスタリングが教師なし学習という違いはVol.9で勉強しましたね(表1)。いったい教師なし学習で分類するってのはどういうことなのでしょうか。いくつかのアルゴリズムを説明しますので、イメージをつかんでください。
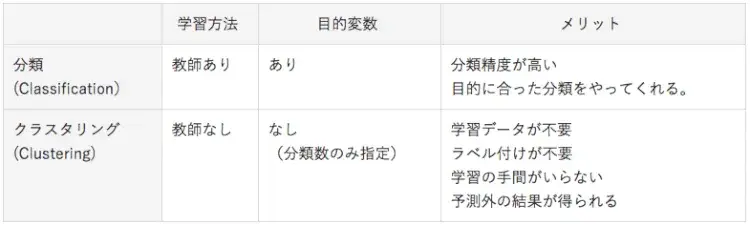
表1:分類(Classification)とクラスター分析(Clustering)の違い(Vol.9再掲)
(1)k平均法
前回、多項分類のk近傍法(k Nearest Neighbor)を学びました。k平均法(k-means)というのも、同じような名前で紛らわしいのですが、こちらの方は教師なし学習のクラスタリングに使うアルゴリズムで全く別物です。k平均法を一言で言うと、”仮グループごとにその集団の重心を求め、その重心に近いものでグループ再結成することを繰り返す分類法”です。
[RELATED_POSTS]例をあげて説明しましょう。店舗とECサイトの両方で販売している小売店が、一度でも購入してくれたことのある顧客がどちらでよく買っているかを調査しました。
①初期状態
調査結果は図2の通りです。表1にあるように、クラスタリングは目的変数(顧客グループ名)は指定せず、単に分類数だけを指定するところが醍醐味で、予想外の結果が得られることもあります。今回は分類数k=4とします。そうです、k近傍法のkはサンプルデータの数でしたが、k平均法のkは分類数であり全然違うんです。

図2:k平均法(調査結果)
②ランダムに4つに分類
人が見るとこんな感じに分類すればいいのにって思うわけですが、とりあえずランダムに4種類(赤、青、黄、緑)に振り分けます。バラバラであちゃーって感じの割り振りですが、この後の処理を繰り返してゆくことでいい感じにグルーピングされてゆくわけです。

図3:k平均法(初期振り分け)
③重心を求める
4つのクラスタ(赤、青、黄、緑)ごとに重心を求めます。重心とは、各データの座標の平均値で、このことからk平均法と呼ばれていることがわかります。

図4:k平均法(重心を求める)
④一番近い重心の色に染まる

各データを一番近い重心の色に塗り替えます。これで、だいぶクラスタっぽくなってきましたね。

図5:k平均法(一番近い重心の色に染まる)
⑤重心が動かなくなるまで③と④を繰り返す。
③に戻って重心を再計算します。重心が動かなくなったら、クラスタリング終了ということになります。この結果に対してグループ名を付けるとしたら、例えば、青:ロイヤル顧客、赤:ネット顧客、黄:店舗顧客、緑:ランクアップ顧客という感じでしょうか。先にグループ名(ラベル)を決めて分類するClassificationに対し、clusteringはグルーピングした後で適切なグループ名を付ける感じになります。

図6:k平均法(重心が動かなくなったら終わり)
k平均法は、実は初期値(②の割り振り)によって結果が異なります。なので、実際は全くランダムというよりも、少し狙いを付けて初期値を設定したり、初期値を何回か変えて分析を行うなどの処理も行われます。また、この例は2次元でしたが、k近傍法と同じように3次元、4次元と次元を増やして行うことも可能です。
|
Vol.13のSVMの説明でハードマシーンとソフトマシーンという言葉が出てきましたが、クラスタリングにもハードとソフトの使い分けがあります。k平均法では、1つのデータは1つのクラスタにのみ分類されますが、これをハードクラスタリングと呼びます。一方、混合ガウスモデルのように、1つのデータが確率的に複数のクラスタに属することができる方法はソフトクラスタリングと呼ばれています。 |
(2)混合ガウス分布
k平均法は座標の近さをベースにクラスタリングするので、基本的な考えはクラスタは円(3次元なら球)という考えに基づいています。そのため、細長いクラスタがあった場合にうまく分類することができません。また、クラスタのサイズに依らずに近さだけで判定するので、クラスタのサイズが大きく違う場合にも不都合が生じます。そこで登場したのが混合ガウス分布とEMアルゴリズムです。
混合ガウス分布(Gaussian mixture models)を一言で言うと、”データが複数のクラスタに属する確率を要因(次元)ごとに重ね合わせてEMを繰り返すk平均法の改良モデル”です。あれ、まだ、ちょっとピンときませんね。
まず第一に言葉が難しそうです。混合ガウス分布って、なんだか聞いただけで腰が引けそうですね。なら、言葉に惑わされないように名前の理解から入ってみましょう。まずは、”ガウス”です。前回、尤度関数のところで正規分布が出てきましたが、ガウス分布とは正規分布のことでしたね。正規分布=確率分布のことなので、確率を使った手法であることがわかります。
では、”混合”はどうでしょうか。これは、複数のガウス分布を重ね合わせて結果を評価することを指しています。例えば、上記の例で言えば、Xの値(店舗で購入)から4つのクラスタに属する確率をガウス分布で求め、Yの値(ECで購入)からも同じく4つのクラスタに属する確率を求め、それぞれのガウス分布を重ね合わ(混合)せて、個々のデータが4つのクラスタに属する確率を求めます。
後は、下記のEMアルゴリズムを繰り返せばいいわけです。k平均法を理解した後なので、混合ガウス分布も言葉に脅かされるほどには難しくなかったですよね。
|
混合ガウス分布はEMアルゴリズムに基づいたクラスタリング手法です。EMとは、Expectation(予想)とMaximization(最大化)の略で、EとMを繰り返すことにより最適なクラスタ分類を行います。各データがどのクラスタに属するかの確率を計算するのがE、確率分布を混合してk平均法における重心に相当するポイントを探すのがMです。k平均法では、重心が動かなくなったら終了でしたが、混合ガウス分布では尤度の変化をみて収束基準を満たしている、もしくは規定回数を超えれば終了とすることが多いです。 |
次元の呪い
あ、久しぶりに麻里ちゃんがやってきました。思わず心が弾んでくるのを感じつつ、最近、妙に人工知能について聞きかじっているので、またどんな質問が飛び出すかってことでも少しドキドキします。
「次元の呪いってな~に?」
お、今回は久しぶりにまともな質問です。まさか、映画のタイトルと勘違いしているわけではなさそうです(それはそれで、こんな映画があったらヒットしそうな予感もしますが…)。さて、っと説明しようとして、分っているはずの次元というものの深みにはまってしまいました。1次元が線、2次元が面、3次元が立体ということ、そして4次元になるとウルトラQの世界(古いっ)ということはわかりますが(あ、ウルトラQはわからなくていいです)、いったい次元ってなんでしょうか。
その4次元の世界から来た怪獣に、”初めてのお使い”でバレーボールを買ってきてもらうとしましょう(また、無茶苦茶な例ですが…)。バレーボールを見たことがない怪獣ですので、バレーボールの特徴を伝えて見極めてもらう必要があります。バレーボールの特徴点ってどんなものがあるでしょうか。
1つは丸い球体であることですね。これでラグビーやアメフトのボールと間違えることはないでしょう。そして大きさが両手を伸ばして挟める程度(直径20cm程度)というのも重要で、これで野球やテニス、ゴルフボール、バランスボールと明確に区別できます。でも、この2つだけでは、まだサッカーボールやバスケットボール、水球、ハンドボール、ボーリングなどと見分けるのは難しそうです。
色が白ってのも入れましょうか。と思ったら、それは古臭い感覚で今は図のようにカラフルなボールが主流でダメでした(図6)。代わりに重さが軽い(270g前後)は有効そうな指標で、バスケットボール(600g前後)やサッカーボール(410g前後)、ボーリングなどと区別できそうです。このほかにも、内圧、弾力性、触感、硬さ、模様など、追加で情報を付け加えれば4次元怪獣は間違いなくバレーボールを買ってこれるでしょう。

図7:バレーボール
もうお分かりですね。これら1つ1つの特徴点(説明変数とも言います)が”次元”です。さきほど4次元以上って存在しないのではって思ったのは、あくまでも空間における次元をイメージしているからで、世の中には次元はいくらでもあります。勘のいいひとはもうお分かりの通り、このAIにおける次元は、BI(ビジネス・インテリジェント)におけるディメンションであり、もっと古い人向けには”顧客別部門別月次売上表”という帳票における顧客、部門、月という集計単位です。
特徴点(次元)を増やすほど精度は高まります。しかし、BIにおいて、ディメンションを多くし過ぎるとデータ量が爆発する問題があったことを思い出してください。それと同じく、機械学習においても高次元になると認識すべき組み合わせは指数関数的に増えてしまい、学習データの用意や学習の難易度が跳ね上がってしまいます。そして悪いことに、過学習の原因にもなってしまいます。はい、このような困った問題を次元の呪い(CurseofDimensionality)と呼ぶのです。
ということで、お待たせしました。上野の麻辣大学で巨大ゴマ団子でも食べながら、麻里ちゃんに答えましょう。この巨大ゴマ団子は、一握りの材料を達人技で延ばしてゆくことで、中が空洞、皮がパリッと優しい甘みの食感になるそうです。「まさか4次元怪獣がこれを買ってくるとは思わなかった」なんてオチのために登場したのではなく、次元の呪いの説明に使おうと思ったのですが、麻里ちゃんがパクリと食べてしまいました。そこで困ってしまい、次のような説明を考えました。

図8:麻辣大学の巨大(30cm)ゴマ団子
「モノを特徴付ける、丸い、大きい、柔らかい、白い、などの尺度を次元と言うんだ。次元を増やせば増やすほど正確にそのモノの特徴を表すことができるんだけど、次元数が大きくなると1つ次元が増えるたびに爆発的に組み合わせが増えてしまって、そんな学習データを用意できなくなってしまうんだ。この問題を次元の呪いというんだよ。」
精度や特徴点、高次元、指数関数的などの用語を使わないのでちょっと長いけど、理解してもらえるかなぁ…(不安)。
次元の削減
さて、次元の呪いがわかったところで、いよいよ次元の削減(Dimensionality Reduction)です。次元の削減とは、”目的(分類や回帰)を達成できる限りの最小の次元にして、次元の呪いを回避すること”です。ポイントは”目的に応じた次元”という考え方です。上記のバレーボールの例で言えば、もし、買いに行ったお店にバレーボール以外に野球のボールとラグビーボールしかなければ、重さや色、内圧、弾力性などの次元をカットして、形状(丸い)と大きさ(20cmくらい)の2次元(特徴)だけでも認識(目的を達成)できます。
次元削減は、厳密に言うと、特徴選択と次元削減の2ステップに分けられます。
(1)特徴選択
考えられる特徴の中から、有用なものを厳選するのが特徴選択です。予算の立て方と同じく、2方向の選択方法があります。
・前向き法…有用な特徴点を1つずつ選択追加してゆく
・後ろ向き法…不要な特徴点を1つずつ削除してゆく
後ろ向き法には、Lasso回帰や決定木などのテクニックも使われます。Lasso回帰は極端な意見の排除(ノイズっぽい次元を無視)、決定木は意見が割れない分岐の削除(割れないならなくてもかまわない)により影響の少ない次元を見つけ出します。
(2)次元削減
次元削減にはLasso回帰や決定木などを使って取り除いても影響のない次元を見つけ出し、これを削減する方法がシンプルで分かりやすいでしょう。このほかに、もともとの次元を掛け合わせて新たな次元を生成する主成分分析というテクニックがあります。これについて少し説明しましょう。
主成分分析(PCA:Principal Component Analysis)
主成分分析(PCA)とは、データ全体の分布を近似した新たな指標を合成して次元を削減する方法です。例えば、「重量」「内圧」「弾力性」「硬さ」「触感」という5つの要素を掛け合わせて(直行して)、「ふわふわ度」「すべすべ感」なる2つの指標にうまく合成することができれば、5次元を2次元に減らすことができます。この合成された指標のことを「主成分」と言います。
主成分には寄与率に応じた序列があります。寄与率とは、元データ(重量、内圧、弾力性、硬さ、触感)に対する相関の強さを表す値で、例えば図8のような寄与率だった場合、「ふわふわ度」は第3主成分、「すべすべ感」が第4主成分となります。第4主成分までで寄与率の合計が0.95となっいます。通常、元データの90%を近似できれば十分とされていますので、次元としてはここまででOKと判断する目安になります。
 図9:主成分分析
図9:主成分分析
なお、図1において、次元削減を教師なし学習に紐付けていますが、本来は回帰や分類、Q学習などのように何かを行うためのアルゴリズムではなく、それらのアルゴリズムを支援するためのテクニックです。そのため、教師なし学習だけでなく、教師あり学習における学習データ作成時にも有効利用できますので、次元抽出と次元削減のテクニックを覚えておくと便利です。
まとめ
今回は、教師なし学習のクラスタリング(Clustering)と次元の削減について解説しました。あ、最後に、なぜ、巨大ゴマ団子が突然登場したか気になる人のために少しヒントを掲げておきます。次元削減の有名な話に、サクサクメロンパンやフランスパンの例えがあります。いわく、3次元で普通のメロンパンが高次元になると中までぎっしり皮になるという話です。これを今、巷で話題の巨大ゴマ団子で例えようかと思ったのですが、我々は空間の概念が3次元までという人生を過ごしてきているので、かえってわかりにくいかと思ってやめたのでした。興味のある人は、サクサクメロンパンで調べてみてください。
梅田弘之株式会社システムインテグレータ:Twitter@umedano









