データベースにおけるインデックスとは、目的のレコードを効率よく取得するための「索引」のことです。テーブル内の特定の列を識別できる値(キー値)と、キー値によって特定された列のデータが格納されている位置を示すポインタで構成されています。インデックスを参照することで目的のデータが格納されている位置に直接アクセスすることができ、検索を高速化することができます。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890646.png)
インデックスとは
テーブルのある行へのアクセスを集合住宅での荷物の配達に例えると、インデックスの有無は以下のように表現することができます。
・インデックス無 集合住宅を歩き回り、各戸の表札を見て配達先かどうか確かめる
・インデックス有 住民の情報が書かれた見取り図で配達先を確認して向かう
インデックスの効果は以下のような特徴を持つ表で特に現れやすいです。
・行数が多い
・検索対象の項目に値の重複、偏りが少ない
・表の更新・追加・削除が少ない
一方以下のような表では効果が現れにくくなります。
・行数が少ない
・表のほとんどの行を取得する
先のように配達に例えると、数戸しかない集合住宅の場合やほとんどの部屋に届ける荷物がある場合はかたっぱしから回っても構わないということですね。
データベースはインデックスを使用するかどうかの判断を自動で行っています。より効率的だと判断された場合にはインデックスが使用されます。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890818.png)
インデックスの種類
インデックスはデータ構造によっていくつかの種類があります。
以下では、代表的なインデックスをご紹介します。
Bツリーインデックス
Bツリーインデックスは木構造のインデックスです。もっとも一般的なインデックスのデータ構造で、Oracleのインデックスにおけるデフォルトのデータ構造でもあります。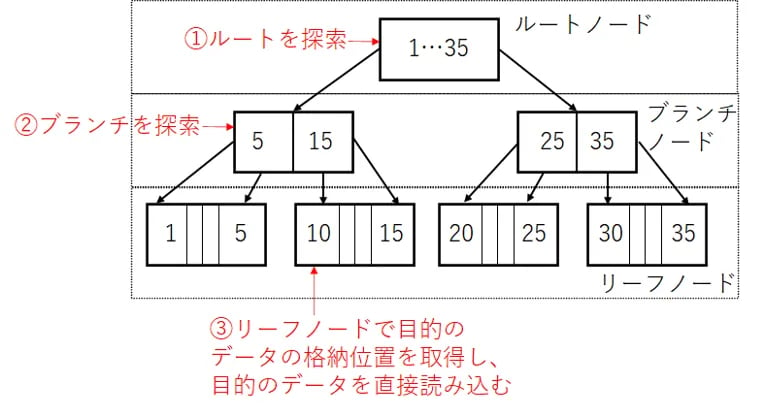
上の図はBツリーインデックスのイメージです。木構造のルートノード(親要素のないブロック)・ブランチノード(親要素・子要素を持つブロック)には関連付けられている子要素が持っているキー値のデータと、子要素の位置情報(ポインタ)が格納されています。一方リーフノード(子要素のないブロック)にはキー値と、対応するレコードの位置を示すポインタが格納されています。
検索の際には木構造のルートからたどり、目的のキー値を含む子要素を順次確認していくことで、効率化を可能にしています。
上図のインデックスを利用してキー値=10のデータ格納位置を特定したい場合、まず①ルートノードを探索します。ルートを探索した結果、左下のブランチノードがキー値=1~15のデータを含んでいることを確認し、②左下のブランチノードの格納位置を取得して探索を続けます。そして③ブランチノードでキー値=10のデータを含むリーフノードの格納位置を取得し、リーフノードで目的のレコードの位置を示すポインタを取得します。
ビットマップインデックス
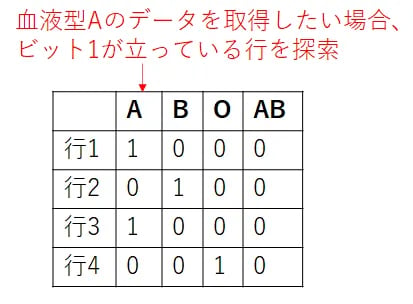
ビットマップインデックスは、上の図のようにあるキー値を含む行をビット1を立てて表すインデックスです。上の図のインデックスを利用して血液型A型の人のレコードを取得したい場合、Aのビット列を探索してビット1が立っている行の格納位置を取得した後に、取得した位置情報を使ってテーブル内のデータにアクセスします。
ハッシュインデックス
ハッシュインデックスはMySQL等で採用されているインデックスで、キー値をハッシュ関数でハッシュ化した値をレコードの住所としてデータを格納します。検索の際にはキー値をハッシュ化して導き出された場所に直接アクセスすることができます。
インデックスの設計
インデックスは以下のような列に設定すると、効果を得やすいです。
・SQLの検索条件で頻出する列や、結合条件に指定されている列
・テーブル内の全データの量に対して、取得対象のデータが少ない列
・Bツリーインデックスの場合はカーディナリティが高い列(格納されている値の種類が多い列)、ビットマップインデックスの場合はカーディナリティが低い列
人のプロフィールを管理するテーブルの場合、血液型はA、B、O、ABのいずれかになるためカーディナリティが低く、逆に身長や体重といった情報は人によりばらつきが大きいためカーディナリティが高いです。
複数の列から成るインデックス(複合インデックス)を作成する場合は順序も重要です。
より対象のレコードを絞り込める列を先に配置することで、検索が効率的になります。
つまり、値の重なりが少ない(カーディナリティが高い)列を先にするとよいでしょう。
またSQL文の評価順序を意識し、より先に評価される列を先にしたほうが効果的です。
SQLの評価順序は以下です。
FROM→JOIN→WHERE→GROUP BY→HAVING→SELECT→ORDER BY→LIMIT
たとえばWHERE句とORDER BY句を条件に持つSQLで使用するインデックスを作成する場合、WHERE句で使われている列を先にしましょう。
インデックスへのアクセスのみで目的のデータを取得することができれば、より検索が効率的になります。取得対象の列のデータをすべて含むインデックスを「カバリングインデックス」といいます。
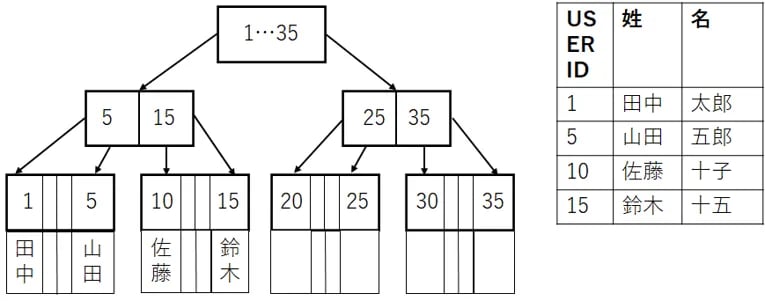
また、カバリングインデックス同様インデックスへのアクセスのみで目的のデータを取得させるインデックスに「付加列インデックス」があります。こちらは、インデックスとして機能させる列(データ抽出条件に含まれる列)とは別に、インデックスのリーフノードに取得対象の列を付加するインデックスです。インデックスから複数の列のデータを取得したい場合、複合インデックスよりもインデックスのサイズが小さくすることができます。
下の図は付加列インデックスのイメージです。右のテーブルからUSERIDと姓を取得したい場合、テーブルの主キーであるUSERIDのインデックスに姓のデータを付加したインデックスを作成することで、インデックスへのアクセスのみで必要なデータをすべて得ることができます。
インデックスの作成
インデックスの作成にはCREATE INDEX文を使用します。
以下に基本的なCREATE INDEX文を記します。
CREATE INDEX スキーマ名.インデックス名 ON インデックスを作成するテーブル名(列名 [ASC | DESC], ...)
例えば、EMPLOYEESテーブルのPOSITIONID,EMPID列に対してインデックスを作成する場合、SQLは以下となります。
CREATE INDEX EMP_POS_INDEX ON EMPLOYEES (POSITIONID, EMPID)
スキーマ名を指定しない場合、インデックスは自分のスキーマ内にあるとみなされます。
CREATE INDEX文では、この他インデックスのデータ構造の指定、インデックスを作成するスキーマの指定等が可能です。詳細は使用するデータベース製品のSQLリファレンスをご確認ください。
インデックスの削除
インデックスを削除する際にはDROP INDEX文を使用します。
以下に基本的なDROP INDEX文を記します。
DROP INDEX スキーマ名.インデックス
EMP_POS_IDXを削除する場合のSQLは以下です。
DROP INDEX EMP_POS_IDX
DROP INDEX文を実行することによりテーブルそのものが削除されることはありません。
まとめ
インデックスの作成はデータベースのパフォーマンスを向上させるために有効な手段です。が、インデックスを利用してデータの検索効率を上げるためには、その特性を理解してテーブルの実データや使用するSQLとも照らし合わせながら設計する必要があります。本記事やデータベースのマニュアルを参考にし、SQLの実行計画も取得しながらチューニングを試みてください。
![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890651.png)








![いまさら聞けない Oracleの基本[初級編]](https://hubspot-no-cache-na2-prod.s3.amazonaws.com/cta/default/2975556/interactive-176098890654.png)