はじめに
CNN、RNN、LSTMと3回にわたってディープラーニングを支える代表的なアルゴリズムを見てきました。今回は、このところ注目されている敵対的生成ネットワークのGANとDCGANをご紹介しましょう。これまで見てきた識別や回帰などの人工知能と違い、GANは生成するモデルです。贋作者とか物まね名人などと不名誉なレッテルを貼られていますが、人間のデザイナーやアーティストが良いものを学んで秀作を作るのと同じく、もはや立派なクリエータの風格が出ています。
GANとは
GAN(Generative Adversarial Networks)とは、2つのネットワークが、切磋琢磨しながらお互い成長してゆく教師なし学習のモデルです。親が教えないのに、兄弟で何回も将棋や囲碁をやるうちに親よりもずっと強くなる。それがGAN兄弟です。ただし、この2人には役割があって、お兄さんのジェネレーター(generator)は偽物作り(生成器)、弟のディスクリミネイター(discriminator)はそれを見破る役(識別器)です。この関係から敵対的(Adversarial)というきつい言葉がついていますが、実際は心優しい弟が兄の成長のために協力してあげているイメージじです(GANの主役は兄の生成器です)。
図1のGANの基本構造をご覧ください。ジェネ君が実物サンプルに似せた偽物をせっせと作り、本物と称して本物と交互にディス君に見せます。ディス君は偽物を見たときに、どっちの確率が高いか判断してシグモイド関数(Vol.18で説明)により本物(1)か偽物(0)か見分けます。そしてディス君が正解したかどうかの判定で誤差逆伝播 (Backpropagation) により、ジェネ君とディス君を順番に調教(重みの変更)します。通常、調教はミニバッチ1セットずつ交互に行われ、ジェネ君を調教するときはディス君を固定とし、ディス君を調教するときはジェネ君を固定して行います。

図1:GANの基本構造
この調教により、ジェネ君はさらに本物に似せて作れるようになり、ディス君も”なんでも鑑定団”レベルに成長していきます。最終的に、ジェネ君が”贋作つくりの名人”になって本物と全く見分けがつかない偽物を生成できれば、ディス君の判定確率は半々になりミッションコンプリートです。
実際にGANでどんなことができるか2つのYouTubeの動画を見てください。映像 1は、左の男性そっくりに動作をする女性の映像です(後半は男女役割が入れ替わっています)。このリアル感ある美女が、実は本物の彼女を実物サンプルとしてGANで学習してジェネ君が作った偽物なのです。映像2は、本物のオバマさんで訓練して作られた偽オバマさんがリアルタイムに話しているものです。こちらの方が普通の応用ですが、実によく似ていますね。
[RELATED_POSTS]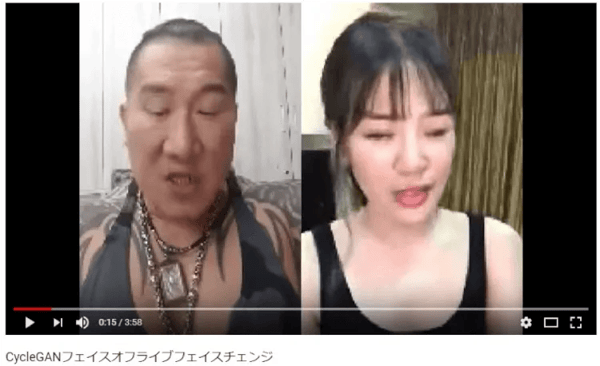
GANはこうした学習技法の総称でいろいろなバリエーションがあります。映像1はその1つであるCycle GANというものを使って学習しています。今回は、画像生成を大きく進化させた畳み込みNNを利用したDCGANを説明することにします。
潜在変数とノイズ
麻里ちゃんは、なぜかGANに興味があるそうです。なんでも、GANはわくわくする人工知能なんだそうで、こんな質問をしてくれました。
「まず、わからないのが潜在変数って何ものかってこと。ジェネ君は何をもとに偽物を作っているの?」
おお~、ちゃんと勉強しているじゃないの。でも、はなから難しい質問で、GANの説明の出鼻くじかれるなぁ。これ、統計の話を先にしないとダメそうです(付いてきてくださいね)。
(1)生成と認識
まず、抑えておきたいのは生成と認識は対のプロセスということです。図2のようにアサガオの画像の特徴点を認識して変数化できるのなら、その逆に特徴点(n次元の潜在変数)から画像を生成することができるはず。これが生成モデルの基本的な考え方になります。

図2:認識と生成は逆処理
(2)潜在変数と観測変数
世の中には、直接、測定しにくい抽象的な尺度がたくさんあります。例えば、麻里ちゃんをどれくらい好きかという気持ちは、いざ、自分に向き合ってもうまく言い表せません。いったい人を好きになる度合いをどう測ればいいのでしょうか。考えた挙句、次の3つをファクターとし、これを測定するための質問を作成して5段階評価で回答してもらうことにしました。3つの解答の合計で好きの度合いを得点化するわけです。
1.麻里ちゃんのことを考える…>週に何回考えるか?
2.麻里ちゃんに会いたいと思う…>週に何回思うか?
3.この景色を麻里ちゃんに見せてあげたいと思う…>いい景色を見たときにどのくらいの確率で思うか?
この場合、直接、測定できない「好きな度合い」を潜在変数、何回とか確率とか数値化できる3つのファクターを観測変数と呼びます。実は潜在変数の概念は、これまでの学習にも出てきています。Vol.13のサポートベクターマシーン(SVM)では、行動的か慎重か、社交的か内向的か、を性格テストで測り、これを観測変数として営業向きか管理部向きかという潜在変数を決めていました。
また、クラスタリング(Vol.15)では、顧客の特性(潜在変数)を、店で購入した数やネットで購入した数を観測変数としてグループ化していましたし、次元の削減で出てきた主成分分析(PCA)でも、「重量」「内圧」「弾力性」「硬さ」「触感」という5つの観測変数をもとに、「ふわふわ度」「すべすべ感」という潜在変数を求めていたわけです。
(3)生成モデル(generative model)と識別モデル(discriminative model)
生成モデルと識別モデルの違いを少し詳しく見ていきましょう。生成モデルは、データの分布状態を確率的に捉え、その分布法則に従ってデータ生成を行う確率モデルです。一方、識別モデルは確率を使いません。与えられたデータをSVMやk均衡法、畳み込みNNなどにより識別するモデルです。
同じ認識モデルでも、SVMのように単に境界面のみ学習するタイプとk均衡法やk平均法のようにデータ分布を学習するタイプがあります。そして、データ分布を認識しているのなら、識別の逆プロセスとして分布のど真ん中(確率的にここが一番というポイント)からデータを生成するすることができます。k平均法で新しい重心を求めていたのは、まさにど真ん中を見つけていたわけです。
あ、モデルを忘れた人のために簡単にメモっておきます。詳細はそれぞれのVolの説明をご覧ください。
SVM:データ群を一番うまく分ける(川幅を最大にする)境界を見つける。 (Vol.13)
k均衡法:近くに多くいるグループの方に仕分け(多数決で分類)する。 (Vol.14)
k平均法:1.グループごとに重心を求めて、2.最も近い新重心のグループになる。
これを繰り返す方法。(Vol.15)
(4)同時確率分布
確率モデルには同時確率分布という概念があります。ピザ屋さんの例で説明しましょう。ピザの会員1000人のうち、1か月以内に新商品「ふわふわピザの割引クーポン」を取得した人とピザを購入してくれた人を集計したら表1のようになりました。
|
グループ |
クーポン取得 X |
ピザ購入 Z |
人数 |
同時分布p(X,Z) |
|
クーポン取得して購入 |
○ |
○ |
200 |
p(1,1)=0.20 |
|
クーポンのみ取得 |
○ |
× |
250 |
p(1,0)=0.25 |
|
クーポン取得しないで購入 |
× |
○ |
150 |
p(0,1)=0.15 |
|
クーポンも購入もナシ |
× |
× |
400 |
p(0,0)=0.40 |
|
合計(確率分布) |
p(X)=0.45 |
p(Z)=0.35 |
1000 |
1 |
表1:会員1000人の1か月のCRM情報

クーポン取得者をX、ピザ購入者をZとしましょう(XとZは確率変数)。XとZが相互に与える影響を無視して、それぞれ独立の確率分布(周辺確率)を求めると、クーポンを取得した人の周辺確率p(X)は0.45、ピザを購入した人の周辺確率p(Z)は0.35となります。
お互いに影響を及ぼすことも考慮した場合(同時確率分布)は、2つの確率変数を使ってp(X,Z)と表します。2つの変数が両方動くと計算しにくいので、1つを固定してもう1つの変化で見ていきます(条件付き確率分布)。
|
統計はどうしても数式っぽいのが出てきてしまうので、ここで用語と記号をおさらいします。 XやZ:確率変数 周辺確率:p(X) 同時確率分布:p(X,Z) 条件付き確率分布:p(Z|X)…Xが起こる条件下でのZの確率 ついでに次の2つの定理も覚えておきましょうか。 確率の加法定理:p(X)=ΣZp(X,Z) 確率の乗法定理:p(X,Z)=p(Z|X)*p(X) 例えば表1で当てはめてみると、次のように定理が成立していることがわかります。 加法定理:p(1)=ΣZp(1,Z)⇒0.45=0.25+ 0.20 乗法定理:p(1,1)=p(1,1)/(p(1,1)+P(1,0))*p(1)⇒0.2=0,2/(0.2+0.25)*0.45 |
では、Xを固定してZの変化を見る条件付き確率p(Z|X)を見てみましょう。クーポンを取得(X=1)した人を対象に、ピザを購入した人(Z=1)の確率を求めると、クーポンを取得して購入p(1,1)=0.2人、クーポンのみ取得p(1,0)=250人なので、0.2/(0.2+0.25)=0.44となります。もう1つ、クーポンを取得しない人(X=0)を対象に、ピザを購入した人(Z=1)の確率は、0.15/(0.15+0.4)=0.27と、クーポンを取得した人に比べると6割程度になっているのがわかります。
統計用語と記号がいろいろ出てきましたので、いったん図3にまとめておきます。

図3:潜在変数モデル
(5)生成的確率モデルと潜在変数モデル
先ほど説明したようにデータの確率分布にもとづいて、データを生成するのが生成的確率モデルです。潜在変数モデルは生成的確率モデルであり、観測変数Xと潜在変数Zとパラメータθを持ちます。この潜在変数モデルを p(x, z | θ)と書くことにします。観測変数Xは測定可能ですが、潜在変数Zとパラメータθは未知の変数です。2つ未知の値があるので、条件付き確率分布で見比べて、潜在変数Zを固定してθを求め、次にθを固定して潜在変数Zを求めるということになります。
ここまで理解したところで、もう1度、図1をご覧ください。ジェネ君は潜在変数モデルの生成器なので、p(x, z | θ)と表されます。Xが観測関数でZが潜在変数です。θはなんでしょうか。これは、データ分布の尤度を最大化するパラメータです。尤度はVol.14で出てきた”もっとも”という確率でlikelihoodでしたね。まあ、ディス君が見破ったことにより誤差逆伝搬で調整されるジェネ君の重み(フィルタ)で、”データ分布の真ん中”を決めるパラメータされるだと思ってください。
生成する潜在変数(データ分布の真ん中)を変更するときは、ジェネ君の重みを更新しない(θを固定)で学習します。そして、ジェネ君の調教のときは潜在変数Zを固定(投げる球を一定)にしてθで重みを更新、という処理を交互に行っているのです。
DCGAN
ここでもう一度生成モデルについて振り返ってみましょう。なにもないとイメージが湧きにくいので、画像から画像を生成する画像変換を題材とします。図4は、モネの画風を真似る訓練をしたジェネ君が、写真をもとにモネのタッチで絵を生成した例です。となりのゴッホと比べると、ずいぶんモネっぽいですね(一応、Googleで"Monet"で検索・画像表示して確認しました^^;)。言語の翻訳の画像版ということで、画像の翻訳とも呼ばれている技術です。

図4:モネを真似するGeneratorがモネっぽい絵を生成
こうした画像処理は、畳み込みニューラルネットワークの十八番(おはこ)です。そこで、畳み込みニューラルネットワークを使ったDCGAN(Deep Convolutional Generative Adversarial Networks) が現れ、GANの画像生成技術を飛躍的に向上させました。Deep Convolutionalってそのまま深層・畳み込みって言葉なので、ちょっと安易に感じるネーミングです。
実は図1のジェネ君、ディス君もNNのイメージを貼り付けていました。これもDCGANだったのです。そして、ジェネ君のNNがディス君と逆向きだなって気づいた方は、「間違い探し大会」に出場資格があるかも知れません。これ、ミスったわけではないんですよ。
最初にお伝えしたように、生成モデル(generative model)は、認識モデル(discriminative model)と逆のことをします。Vol.16で学んだ畳み込みニューラルネットワーク(CNN)を使って入力画像がモネの絵かどうかを判定する。これがディス君の役割です。畳み込み処理とプーリング処理を繰り返して大きな画像を小さなたくさんの画像に変換していき、最後に全結合層の多数決で判定するのでしたね。
ただし、DCGANのディス君はプーリング層をストライド2の畳み込み(1ピクセルずつでなく、2ピクセル間隔で畳み込み処理する=ストライド1より小さくできる)に置き換えるとか、全結合層で総当たり戦をやる代わりにglobal average pooling(出力画像ごとに画素平均を求めそれを1対1で出力する=出力に関連付ける重みパラメータが大幅に減る)など処理の軽量化を行っています(図5)。
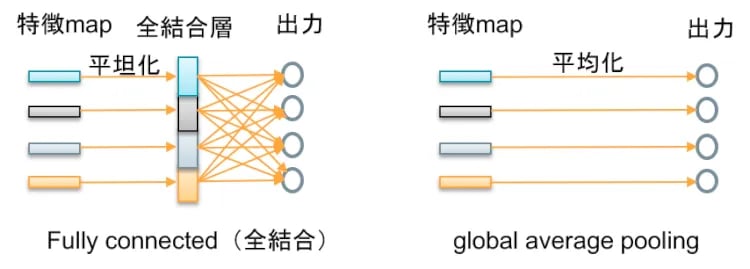
図5:global average pooling
一方、ジェネ君は畳み込み処理の逆のことをします。n次元の潜在変数を種として、逆畳み込み処理(deconvolution)を行い、種を徐々にモネっぽい画片に育て、最後に1枚の絵を作り出すわけです。ディス君はアップサンプリングする逆畳み込みのニューラルネットワークなのです(図6)。
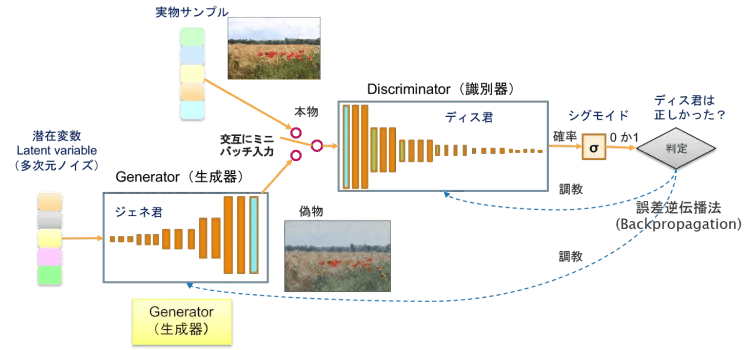
図6:DCGANの画像生成と画像識別
GANの学習
GANの種には一様分布や正規分布をもとに取り出した潜在変数を使います。k平均法(Vol.15)の初期振り分けが人間からしたらあちゃーって感じだったのと同じですね。k平均法は、そこからEMアルゴリズムを繰り返して収束していきました。DCGANも同じです。学習初期のジェネ君のアウトプットは、アナログテレビの砂嵐画面(あ、若い人はこれも知らないか)のようにノイズ一色という感じです。
GANは、教師なし学習なので学習に時間がかかり、また、きちんとミッションコンプリートさせるのが難しいです。学習には、本物のデータ量(画像枚数)と潜在変数の次元数(Vol.15)が関係します。データ量や次元が多い方が精度の高いものを作れますが、次元を100、200と大きくしてゆくとそれだけ学習に時間がかかります。どうしてもランダムノイズの種だけだと学習が大変なので、Conditional GANなどデータの一部にラベルを付けた半教師あり学習モデルも出現しています。半教師あり学習については、次回まとめて説明します。
GANの学習には、Vol.4で学んだミニバッチ学習法(元データからランダムに少量抜き出してバッチ学習するのを何回も繰り返す)が用いられます。学習は野球やアメフトのような交代制で、本物だけで学習した後に偽物だけで学習するというバッチ学習を交代で行います。ジェネ君はうぶなので、Vol.10の麻里ちゃんのじゃんけんと同じく、一方がずっと続いたから次もそっちだろうなどというベイズ確率(Vol.13)は考えないのです。
ジェネ君の学習では(ディス君も使う場合があります)、Batch Normalization(バッチ正規化)が使われます。これは、ニューラルネットワークの各層の出力データを正規化することにより、勾配消失・爆発や過学習を防ぐ工夫です。また、ジェネ君の活性化関数(入力信号の総和を出力信号に変換する伝達関数)には出力層のみTanh(Vol.18)を使いますが、それ以外の層はReLu(Vol.16)というランプ関数を使います。一方、ディス君は、全ての層でLeaky ReLUを使います。ReLuはxが負なら0を、正なら入力値xを出力する関数で、Leaky ReLUはxが負なら0.2xを、正なら入力値xを出力する関数です(図7)。なぜ、これらの関数を用いるかを説明するには数式がたくさん出現するのでここでは省略します。
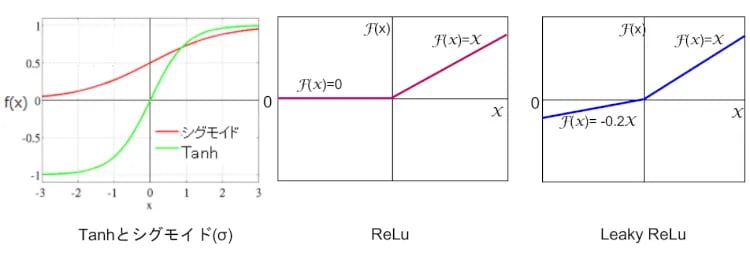
図7:TanhとReLuとLeaky ReLu
学習データを1巡すると1エポックとカウントされます。エポックごとにディス君とジェネ君のロス率(どれくらい間違えたか)が表示されますので、我々はこれらの値を確認しながら訓練を進めます。この2人はバランスよく成長させる必要があります。GANのユニークなのは、ジェネ君は本物を見たことがないってことです。本物をまんま真似ているわけではなく、本物っぽい特徴をつかんで、「ほら、こんな特徴があれば本物だと思うだろう」という具合に、ディス君(彼はしょっちゅう本物も見ている)さえ騙せればいいのです。
このため、ディス君が弱すぎるとジェネ君は相手の弱みに付け込んで、同じようなカードを出し続けてしまいます。逆に、ディス君が強すぎて何を出しても見破られるとジェネ君は勾配消滅という深い迷路に入ってしまいます。また、学習ごとに強弱が入れ替わって振幅しがちで、生成物の結果が良くなったり悪くなったりします。振幅しながらも収束すればいいのですが、そのままのこともよくあります。
アップサンプリング
「CNNは、情報量を減らすのだからいいけど、生成モデルは逆だよね。プアな情報からリッチな画像なんて作れるものなの?」
あっ、次はそこですか。確かにjpegはエンコーダによって画像を圧縮して保存できますが、デコーダーで復元しようとしても情報が削除されてしまったので粗い画面になってしまいます(図8)。特徴点を残しながら画質を保ったまま小さくはできるけど、小さいものは情報を足さないと大きいものを作れないですね。どんな情報を足すかなんて神のみぞ知るのように思えますが、アップサンプリングってどうやっているのでしょうね。

図8:画像のダウンサンプリングとアップサンプリング
GANは神ではないのですが確率使いです。Vol.16の畳み込み演算の説明で3×3の9ピクセルの平均で1枠の値を決めた処理を思い出してください。実は逆畳み込み処理でもそのテクニックを使って、欠落している部分に平均値を埋め込んでアップサンプリングしています(実は人間だって同じように、無意識に欠落部分を補完して物事を認識しています)。
図9を使って説明しましょう。
①相対的に拡大
3×3の9マスを5×5の25マスに相対的(相似)に拡大します。このとき、空きピクセルが生じますので、そこにはゼロをパディング(埋め込み)しておきます。
②隙間を中間色で埋める
5×5の左上から9マスずつ範囲を絞り、そこに含まれている情報での平均値で5×5ピクセルの値を決めます。9マスに含まれる情報がaとbの2つなら(a+b)/2、4つなら(a+b+c+d)/4を求め、その値で隙間を埋めます。手っ取り早くいうと、隣にある情報の中間色で隙間を埋めるということです。これを左上から1ピクセルずつ順番に行うことで、隙間に隣と違和感のない情報が入るわけです。
③特徴を比較
サイズがアップされたなら、後はCNNと同じくフィルタ(特徴)を比較して画像を変換します。 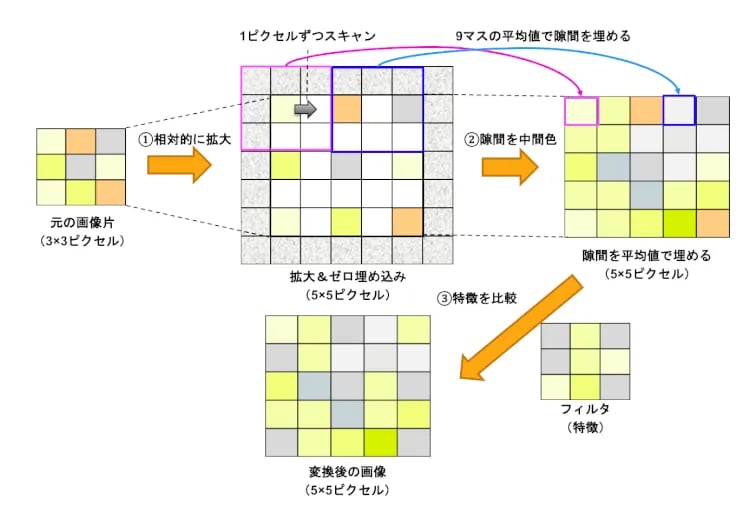
図9:3×3から5×5へのアップサイジング
GANの用途
「これからGANは、世の中で使われるようになるのかしら?」
GANは今まさに絶賛発展途上中です。まだ、ディス君は騙せても人間を騙せるレベルには到達していませんが、このまま進化すれば遠からずそのレベルをクリアしそうです。どのようなジャンルで使われてゆくのか、どんなことができそうなのかをさっと見てみましょう
①高解像度の画像生成(create image)
ディープラーニングの利用は、これまで「分類」や「回帰」などが中心でしたが、GANにより逆アプローチである「生成」が実用的なレベルになると期待されています。特に画像の生成は、DCGANにより、もう一歩(もう二歩かな)というところまで来ています。人の顔、部屋のイメージ、インテリア、クールなファッション、アニメ、などさまざまな分野で研究発表が行われており、遠くないうちに実用例がいくつか出てきそうです。
また、直接の使い方ではないのですが、学習データを増やすための水増し(Vol.7)などにもGANを応用している例が発表されています。サンプル数が限られていいる医療画像データを生成して、医療トレーニングに使うなどの用途も発表されています。
②画像の翻訳(image to image translation)
図4のような画像から画像への翻訳は、DCGANの登場によりかなりいいところまで来ています。図2はもともと輪郭がぼけている油絵を生成するものなのでお手の物でしたが、別の例でもリアリティのある高解像度の画像を作れるレベルまで来ています。漫画などでラフスケッチを書けば漫画家のタッチで仕上げてくれたり、航空地図から航空写真を作ってくれたり、さまざまな用途が期待されています。
③文章からの画像起こし(text to image)
絵の特徴を文章で語っただけで画像にしてくれるText to Imageなども発表されています。モンタージュ写真なんかも、今よりずっと精度の良いものができそうですね。
④動画の翻訳(video to video translation)
冒頭の動画を見る限り、動画から動画の翻訳も結構のレベルまで来ていることがわかります。映像2のオバマさんは同一人物ですが、映像1の偽美女動画は別の人をリアルタイムにシンクロさせていて、最初に見たときにびっくりしました。往年の女優を使った映画を作ったり、亡くなってしまった彼女が若いころの姿で毎晩話しかけてくれたり、そんなことをサービスするビジネスが生まれたり、などいろんな妄想が湧き出てきます。でも、詐欺やペテンの類に使われる恐れもありそうで、ちょっと怖い技術でもあります。
⑤ビデオ予測(video prediction)
画像をもとに、その数秒先までの動画を予測する発表がMITからなされています。この技術はまだまだ実用化には遠そうですが、完成すれば、例えば自動運転車の車載モニターに積んで、歩行者や自転車の動きを予測できそうです。
⑥イメージの演算
GANの面白いのは、偽物を作るだけでなく、生成したイメージを演算できることです。図10Aをご覧ください。左端の「メガネをかけた男」から「メガネをかけない男」を引き算し、それに「メガネをかけない女」を足すと、なんと「メガネをかけた女性」が生成されるという嘘みたいな演算ができるのです。
この仕組みを潜在変数Z空間で表したのが図10Bです。GANで学習した結果の潜在変数Z空間において、「A.メガネをかけた男」と「B.メガネをかけない男」の差分ベクトルを求め、それを「C.メガネをかけない女」にベクトル加算すると「D.メガネ先輩」が作り出されるのです。矢印の部分を徐々に移動すると、イメージが少しずつ変化しているのがわかります。n次元からなる潜在変数からメガネ以外の次元を引き算するとメガネの次元だけが残されるってわけです。
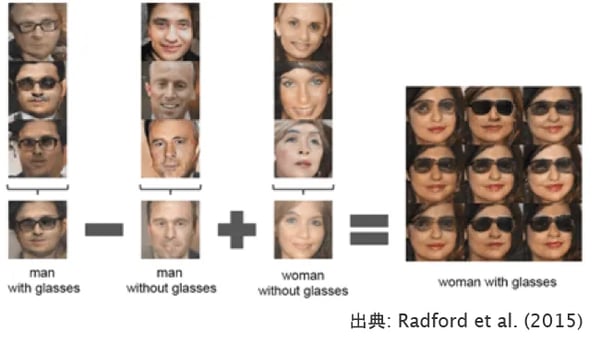
図10A:イメージの演算
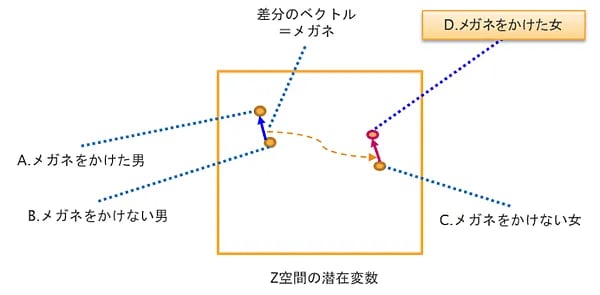
図10B:潜在変数(Z)のベクトル演算
⑦デザイナー
例えばファッションで服や帽子などをバーチャルで着せ替えるアプリがありますが、これらもGAN技術ベースになるかも知れません。それにも増して期待されるのがデザイナーとしてのGANです。トップデザイナーや流行のファッションスタイルを学んだGANが、新しいデザインを創り出すということもすでに実用化に向けて進められています。ことはファッションに限りません。建築や工業製品、看板、ロゴなど、あらゆるデザイナーの世界でGANが利用される可能性があります。
⑧アーティスト
同じように、いわゆるアーティストと呼ばれる世界にもGANが入っていきそうです。囲碁や将棋の世界でトップ騎士たちがAIを使って新手を発見したり自己研鑽したりしているように、絵画や書道、彫刻などの美術家をはじめ、小説家や詩人、映画制作、華道家など、さまざまなアートの世界にGANが利用される可能性があります。
まとめ
今回は、今、もっとも注目されているAI技術の1つであるGANを解説しました。生成が主役であるGANを進化させるための研究が世界中で行われており、我々の生活にも実用化されたものが次々と登場してくるように思われます。
次回のテーマは、「半教師あり学習」です。これまでのAIは、学習しやすい「教師あり学習」が主役で対抗馬として学習データのラベル付けがいらない「教師なし学習」がいたわけですが、そのいいとこどりをしようとする「半教師あり」学習が注目されています。最初はコツを教えてやるから後は自分で考えて学べって感じでしょうか。そう思うと、なんか現代教育にも通じるものがあります。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano











