探索アルゴリズムは、数あるアルゴリズムのなかでも、もっとも基本的なアルゴリズムの1つです。複数のデータの中から条件に一致した値を見つけるために用いられ、エンジニアはもちろん、ビジネスマンとしておさえておきたい考え方であるといえるでしょう。
この記事では、探索アルゴリズムのなかで主要な「線形探索アルゴリズム」と「二分探索アルゴリズム」、さらに応用編として「ハッシュ値」「ハッシュ表」「ハッシュチェイン法」を紹介していきます。

線形探索アルゴリズム
先頭のデータから順に、条件に照らし合わせながら調べていくのが線形探索アルゴリズムで、最もシンプルで基本的な探索アルゴリズムと言われています。単純な反面、探している値がデータベースの最後の要素であった場合、すべての要素を探索しなければいけないため手間がかかるというデメリットがあります。
探索例
- [5,3,7,1,8,6,11,2]という並びのデータの中から6を探す場合を説明します。
- まず、データの先頭の数字(5)と6が同じかを確認します
- 違っている場合、次にデータの2つ目の数字(3)と6が同じかを確認します。
- これを6が出るまで繰り返します。
探索回数
探索対象のデータの母数Nに対し、線形探索では最大探索回数はN回、平均探索回数はN/2回です。(あるアルゴリズムの利用を考えるときには必要な計算回数の想定が欠かせません。)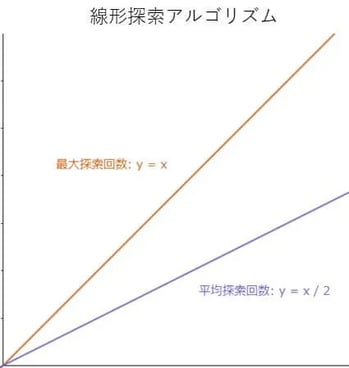

二分探索アルゴリズム
整列されたデータ群を2つのグループに分け、探索している要素がどちらのグループにあるかの判断を繰り返して探索範囲を狭めていく探索アルゴリズムを二分探索アルゴリズムと言います。
線形探索よりも効率的に探索を行えますが、データが整列されている必要があります。整列されていないデータに二分探索を行う場合は、ソートアルゴリズムを使って値を整列させてから二分探索を行います。
探索例
- [1,2,4,5,6,8,9,11,13,14,15]という並びのデータの中から6を探す場合を説明します。
- 真ん中の数字(8)と6を比較します。※真ん中がない場合は1つ左側 or 右側を選びます。
- 6のほうが小さいので、6はこれより左側に存在することがわかります。
- 次に左側の5つのデータ[1,2,4,5,6]から真ん中の数字(4)と6を比較します。
- 6のほうが大きいので、6はこれより右側に存在することがわかります。
- 次に右側の2つのデータ[5,6]から真ん中の数字(5)と6を比較します。
- 6のほうが大きいので、6はこれより右側に存在することがわかります。
- 一つまで絞れたのでこの値(6)を6と比較します。
探索回数
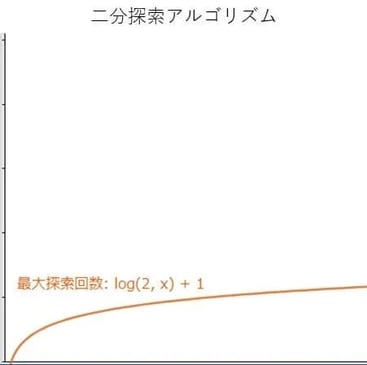
二分探索の場合、最大探索回数は(log2N+1)回、平均探索回数はlog2N回となります。
※ただし、あらかじめ大きい順または小さい順に整列されたデータである必要があることには注意が必要です。
より高度な探索アルゴリズム(ハッシュ値・ハッシュ表)
基本的な探索アルゴリズムをご紹介してきましたが、データを加工することでより効率的に探索を行う方法としてハッシュ法を説明します。
ハッシュ法は探索する値を直接探すのではなく、固定長の探しやすい情報(ハッシュ値)に変換して探索する方法です。原理上、非常に少ない探索回数で探索可能です。ハッシュ法では、探索を始める前にルールに基づきデータを変換しておきます(ハッシュ表の作成)。
探索例(考え方)
- ハッシュ表の作成ルールは特に決まったものはありません。
- 良く用いられるのは「nで割った余り」です。一例として「100で割った余り」とした場合を考えてみましょう。このルールを適用すると、例えば429というデータのハッシュ値は29となります。
- ②で作成したハッシュ値を使って、探索を実施していきます。
注意点
- ハッシュ法には解決しなければならない大きな問題があります。それは別々のデータが同じハッシュを持つ可能性があること(衝突)です。
- 上記の例では下2桁が同じであれば129でも2529でも9999929でも同じハッシュになってしまいます。これはハッシュ法において避けようがないので、衝突が起きたとしても問題ないような対策が必要になります。
- 一般的にはハッシュチェイン法とオープンアドレス法が有名です。今回のブログではハッシュチェイン法について説明したいと思います。
より高度な探索アルゴリズム(ハッシュチェイン法)
ハッシュチェイン法は同じハッシュ値をもつデータをグループとして連結させて保持する手法です。ひとつひとつのデータをラベルの付いた棚にしまっておくイメージです。
探索例(数値)
- [1,2,4,5,6,8,9,11,13,14,15]というデータの中から6を探す場合を説明します。
- ハッシュ表作成ルールを「5で割ったあまり→0,1,2,3,4」として、上記のデータを5つのグループに分割します。
余りが0のグループ:[5,15]
余りが1のグループ:[1,6,11]
余りが2のグループ:[2]
余りが3のグループ:[8,13]
余りが4のグループ:[4,9,14] - まず探索する6という数字をハッシュ表作成ルールに基づき5で割ります。余りは1なので、「余りが1のグループ」の中にあるはずです。[1,6,11]から線形探索を行うと2つ目に6を見つけることができました。
- 線形探索では5回、二分探索では4回の探索が必要だったのに対し、ハッシュチェイン法では3回(グループ探索1回+グループ内の探索2回)で探索を完了することができました。ハッシュチェイン法を用いることでより効率的に探索を行うことができました。
探索例(文字列)
順番が決まっていないデータに対しても探索できることがハッシュチェイン法の特徴です。さらに数値だけでなく、例えば文字列のような順番が決めづらいデータも探索することができます。以下の通り、具体例で見ていきましょう。
- [山田、佐々木、小島、富士、吉崎、吉田、木元、久下、岡、名倉]というデータから吉田を探す場合を説明したいと思います。
- まずはハッシュ表を作成しましょう。今回は「総画数(6以下は6、15以上は15)」をルールとしてハッシュ表を作成します。すると以下のように10個のグループに分けることができます。
6画以下のグループ:[久下]
7画のグループ:[]
8画のグループ:[山田、木元、岡]
9画のグループ:[]
10画のグループ:[]
11画のグループ:[吉田]
12画のグループ:[小島]
13画のグループ:[]
14画のグループ:[佐々木、富士]
15画以上のグループ:[名倉、吉崎] - では探索を行ってみましょう。まずは探索する「吉田」という文字から総画数を算出します。11画ということがわかりますので、「11画のグループ」を取り出します。
- このグループには[吉田]のみなので、これで対象のデータを見つけることができました。
- このように、ルールを決めてハッシュ表を作成することで、文字列など順番が決まっていないデータについても探索を行うことができます。
ハッシュチェイン法のメリット、デメリット
- 探索対象のデータの母数が増えても探索回数に与える影響が小さい。
- ハッシュの重複に偏りがあると探索データによって探索時間が大きく変わる。
さいごに
いかがでしたか?今回は探索アルゴリズムの基本である以下の方な手法について紹介しました。
- 線形探索
- 二分探索
- ハッシュチェイン法
「探索アルゴリズム」と言われると何となく身構えてしまいますが、内容がわかってしまえばそれほど難しくないと思えたのではないでしょうか。ぜひご自身でもソースコードを書いて試してみてください!








