プログラムを実行したときに、思った以上に処理が遅いと感じたことはないでしょうか?
「プログラムは正しく実行できているのに、思うほど処理速度が早くない。どうして?」プログラミング学習を始めたばかりだと、このような疑問に直面することがしばしばあります。データを効率よく処理するためには、適切なアルゴリズムとそれに合わせたデータ構造をきちんと使う必要があります。
本記事では、データ構造の基礎について解説していきます。継続してデータ構造への理解を深めることが、プログラミング上達の助けになることでしょう。

データ構造とは

プログラミングにおいて、データ構造とは「データを効果的に扱うために、一定の決まりで体系立てて格納する形式」のことです。プログラムの処理の流れ(アルゴリズム)に大きく影響するため、アルゴリズムに適したデータ構造を使用する必要があります。
ここでは、データ構造はどのようなものがあり、どのような特徴があるのか、そしてどのアルゴリズムに適しているかを解説していきます。

配列
配列とは
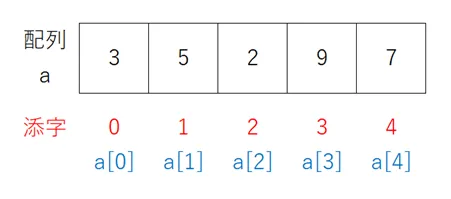
配列とは、同じデータ型の塊です。よく「複数の箱をひとつにまとめたもの」とも言われます。配列には添字があり、特定の箱を指定することができます。
図でいうと、配列名「a」の中に、数値型の複数のデータをいれることができます。それぞれの箱を指定する場合、例えば最初の箱についてはa[0]と指定することで、その箱の中の値を取り出すことができます。
配列は通常繰り返し(for文、while文)と組み合わせて使われることが多いです。これは、繰り返し回数を添字に指定すれば「配列の最初から一つずつ値をとって処理をする」ことができるからです。
配列には添字があるため、ランダムでのデータ取得をすることが容易です。また、配列の後ろにデータを追加することも高速にできます。逆に、配列の中間部分にデータを追加する場合は、以降の添字をすべて付け替える必要があるため、処理に時間がかかります。
配列のメリット、デメリット
- メリット:添字による任意のアクセスが可能、配列末尾のデータ追加が高速
- デメリット:配列の中間部へのデータ追加は遅い。
構造体の配列
構造体とは
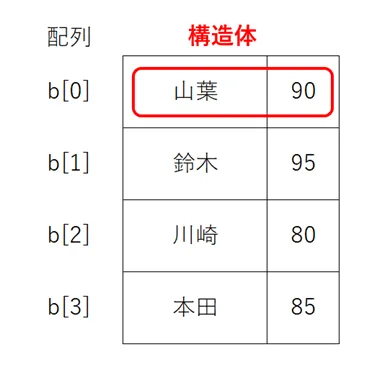
配列は、同じデータ型の塊であるため、異なるデータ型を組み合わせて格納することはできません。たとえば、テスト受験者の氏名と点数の組み合わせをそれぞれ文字型、数値型で格納しようとすると、1つの配列で登録することはできません。
その場合は、構造体を使用することで、異なるデータ型を格納することができます。「1つのデータ型しか持てない」という配列のデメリットをなくせる代わりに、より大きいデータを持つことになるため、単純な配列以上にメモリを消費するというデメリットがあります。
構造体の配列のメリット、デメリット
- メリット:異なるデータ型を1つの塊としてデータを格納できる
- デメリット:配列と組み合わせた場合、データ量が大きくなり、大量にメモリを消費する
ツリー構造(木構造)
引用:Wikipedia
ツリー構造とは
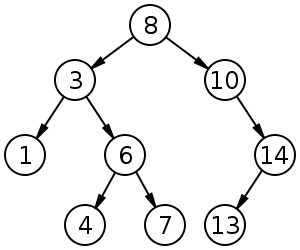
ツリー構造(木構造)は、その名の通り木(tree)のような形状をしたデータ構造です。階層を持つデータの集まりとなっており、大きなデータから目的のデータを見つけたい場合におすすめです。
ツリー構造はデータの持ち方によって、さまざまなパターンがあります。ここではツリー構造(木構造)のひとつ、二分探索木を紹介します。
二分探索木とは
二分探索木は、「左の子の値<親の値<右の子の値」というデータの持ち方が特徴の二分木です。大量のデータから目的の値を探す場合、各階層の親の値と比較して2つある分岐のうちのどちらの木を探索していくかを選択するたびに、探索対象を全体の半分に絞り込んでいくことができるので効率的です。
二分探索木を使ってデータを探索するには、まず準備段階で、データがソート(並び替え)されていなければなりません。また、処理の途中でデータが変化する場合、適宜ソートしなおす必要もあります。
二分探索木のメリット、デメリット
- メリット:大量のデータを効率よく扱いたい場合に有利
- デメリット:事前にデータをソートしておく必要がある
キュー
キューとは
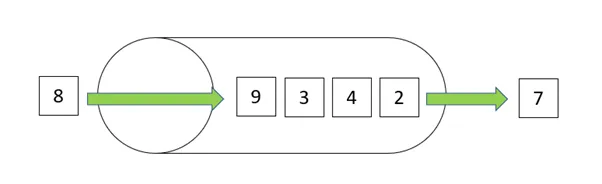
キューは、データ構造というよりデータの扱い方の1つです。先入れ先出し(First In First Out:FIFO)のリスト構造でデータを保持します。一般的にキューにデータを入れることをエンキュー、取り出すことをデキューと呼ばれます。
たとえばお店のレジの行列をイメージしてください。並んだ人から順に出ていきます。キューはまさしくこのイメージです。キーを入力したら入力した順番に表示される、プリンタで印刷するとき順番に出力される、など多くの処理でキューは使われています。
スタック
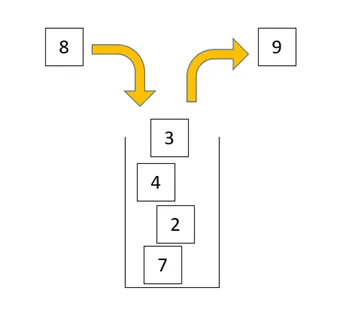
スタックとは
スタックはキューと反対の考え方です。後入れ先出し(Last In First Out:LIFO)の構造でデータを保持します。一般的にスタックにデータを入れることをプッシュ、取り出すことをポップと呼ばれます。
スタックは、図のように物が積み上げられた状態をイメージしてください。入れるときは上に積まれ、取り出すときも上からです。
Webブラウザの「戻る」ボタンやテキストエディタの「やり直し」といった、履歴をさかのぼる処理では、スタックが使われます。
ヒープ
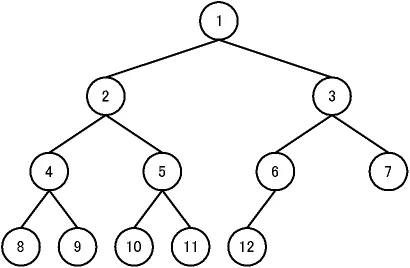
引用:Wikipedia
ヒープとは
ヒープは二分探索木と同じくツリー構造であり、「子は親より常に大きいか等しい(または常に小さいか等しい)」というルールがあります。子が複数ある場合、子どうしの大小関係に制約はありません。なお、図のように子が2個以下の場合は「二分ヒープ」と呼ばれます。
ヒープは根に最大値または最小値がくる構成であるため、最大値や最小値を取得するのに適しています。この構造を利用したソートアルゴリズムが「ヒープソート」です。
まとめ
いかがでしょうか。プログラムを作成する際には、それぞれの目的に合ったデータ構造を使用することで、処理の高速化を実現できます。たとえば、「最大値または最小値を取得するなら二分探索木よりもヒープを使用したほうが高速に処理できる」などです。
今回ご紹介したデータ構造は一部ですが、他にもデータ構造はたくさんあります。それらのデータ構造を使って効率よいアルゴリズムを選択すれば、プログラムはより高速に処理することができます。プログラミングの勉強を始めたばかりの方は「データ構造とアルゴリズム」も一緒に勉強するとよいでしょう。








