はじめに
ディープラーニングには大量の学習データが必要と言われてきましたが、実社会ではそんなにデータをそろえることができないという現実があります。そこで、ここにきて広まってきたのが少ないデータで学習するテクニックです。今回はその代表的な方法について、麻里ちゃんにも理解できるように数式を使わないで説明します。
少ないデータで学習する方法
この1、2年で少ないデータで学習する技術が急速に進化してきました。データ量が少なければ、データを集める労力、クレンジングの手間、そして学習にかける時間や負荷も大幅に節約できますし、なによりもともとデータ量がそんなにないけれど人工知能を利用したいというニーズに応えることができます。
現時点で少ないデータで学習するための方法は次の3つです。品質の良いデータを使うことについてはVol.6で解説しましたので、今回は残りの2つについて説明します。
・品質の良いデータを使う
・水増し
・転移学習
水増し(Data Augmentation)
誰ですか「水増し」なんてイメージの悪い日本語訳を付けたのは。水増しのもともとの英語は"Data Augmentation"で直訳すると「データ拡張」です。その直訳を知ると、「水増し」は実に言い得て妙の名訳ですね。前回露呈した私のネーミングセンスとは月とスッポンと脱帽せざるを得ません。
水増しとは、元の学習データに変換を加えてデータ量を増やすテクニックで、特にCNN(畳み込みニューラルネットワーク)などを使った画像処理で効果を発揮します。変換には、次のようなものがあります。
・ノイズを増やす(ガウシアンノイズやインパルスノイズ)
・コントラストを調整
・明るさを調整(ガンマ変換)
・平滑化(平均化フィルタ)
・拡大縮小
・反転(左右/上下)
・回転
・シフト(水平/垂直)
・部分マスク(CutoutやRandom Erasing)
・トリミング(Random Crop)
・変形
・変色
・背景を差し替える(これはライブラリの機能ではなく別途作業)
KerasやTensorFlow、Cognitive toolkitなど最近のニューラルネットワーク・ライブラリにはこのような水増し機能が用意されています。学習に使う画像を用意する際の前処理として、ノイズを加える、輝度を下げる、明るさを減らす、平滑化、変形する、一部をマスクする、などきれいな画像を汚くしてロバスト性を高める水増しを行うこともできます。さらに、ライブラリによっては学習の際にリアルタイムで水増させることもできます。
|
ロバスト性とは、外乱や障害に強いという意味で、車に例えれば”悪路に強い”、人に例えれば”打たれ強い”ということです。画像認識においては、認識対象の画像がきれいに写っているものだけとは限らず、一部が隠れていたり、角度が悪かったり、かすれていたりします。本番データの画像品質が不安定な場合は、そんな画像でも認識できるロバスト性の高い分類器が必要となります。 |
水増しの注意点
水増しを試行錯誤してみると、正解率が良くなる場合もあれば、逆に悪くなってしまう場合もあります。悪化してしまわないために気を付けるポイントを3つあげましょう。
(1)過学習
過学習(Over fitting)とは、特定の訓練データばかりで学習し過ぎて、分類器がそのデータだけに強い(一般のデータには弱い)ガリ勉くんになってしまうことでしたね。水増しは、もともとは同じ画像に変形を加えただけなので、見かけ上データ量が増えたとしても、オリジナルの持つ特徴点はそう変わりがなく、そのデータの特徴点だけに強いガリ勉君を作りやすいのです。水増しが少量データで学習できる有効な方法だとしても、ある程度のデータ量は必要となります。
(2)品質が悪いデータ
水増しした結果、実際にはあり得ないデータや人間が見ても判断できないデータになってしまったら、それこそ「品質の悪いデータを分類器に食べさせる」ことになってしまいます。例えば手書き文字認識にMNISTという便利なデータセットがありますが、これに対して左右反転や上下反転などの水増しをすると、麻里ちゃんから「アホ、わかってないな!」って笑われてしまいます。水増しの基本はあくまでもロバスト性を高めることと認識して変形処理を行ってください。

(3)本番データを意識
クレンジングや水増しなどの前処理は、本番データを強く意識して行います。例えば、当社がホームページで公開している花の名前を教えてくれるAI「AISIA FlowerName」の場合、どのような本番データを意識するべきでしょうか。
まず、前提として、花には、同じ花でも色が違っていたり、形が違っていたりするものが多くあります。逆に違う花でも写真だけでは区別のつかないものも多く、花の認識はもともとかなり難易度の高いジャンルです。
さらにこのサイトでは、一般の人が自分の撮った写真をアップする仕組みなので、画像のサイズや写っている花の大きさ、画像の品質、遠景近景、アングル、写真の向きがバラバラということが考えられます。
「AISIA FlowerName」では、このような多様なデータが想定されるので、それに対応できる水増しを行い、十分にロバスト性の高い分類器を作らなければならないことになります。
一方、工場の最終工程に流れてくる製品の品質検査の場合は、カメラで定点撮影した動画のサイズや品質は安定しているため、ノイズ付加や輝度削減などの水増しでロバスト性を高める処理をする必要がありません。。かえって下手な変形をして実際に発生しないような学習データを作ってしまうと正解率が下がってしまいます。
このように水増しは本番データを意識して行う必要があります。例えば、輝度を変える水増しをする場合でも、闇雲に行うのではなく、本番データの各画素の輝度の分布でヒストグラム形状を分析しておいて、学習データを本番で存在するヒストグラム形状に近いように水増しするといった工夫が行われたりします。
転移学習(Transfer learning)
画像認識における少量データ学習法として、水増しに続いて脚光を集めて今や常識となっている方法が転移学習です。転移学習とは、ある領域(ドメイン)で学習したモデルを別の領域(ドメイン)に使って、普通に学習させるよりも少ないデータで追加学習させる手法です。もっとわかりやすく言えば、「あっちで学んだ学習済モデルを流用して、こっちの学習を少ないデータで済ます手法」です。
もし、海外でもいいので花の名前を覚えさせた学習済モデルがあれば、それに日本の花を追加で教えてあげれば、簡単に日本の花の名前も分かる分類器ができます。誠に都合がいいのですが、そんなうまい話はそうないでしょうね。転移学習は、このような類似のドメイン(花の名前)ではなく、別のドメイン(動物や乗り物など)のモデルを流用しても通用するというところがミソなのです。
具体例で説明しましょう。2014年のILSVRC(画像認識コンテスト)で優勝した有名な学習済モデルにVGG16があります。これは13層の畳み込み層と3層の全結合層から構成されている畳み込みニューラルネットワーク(CNN)です。Vol.6で解説したImageNetという大規模(現在、2.1万クラス、1400万枚)な画像データセットのうちから、コンテストのお題で出された1000のクラス(カテゴリ)を識別できるように訓練されています。
1000のカテゴリには、ライオンやシマウマ、オットセイのような動物、トラクター、クレーン車のような乗り物、火山、サンゴ礁のような自然、など実にさまざまなものがあり、犬ならばマパニーズスパニエルとかボーダーテリア、シベリアンハスキーとかすごくたくさんの犬種を見分けてくれます(よほど犬好きな人がカテゴリを決めたのでしょうね)。
なのに花に関しては非常に冷たい仕打ちで、バラ(rose)もなければユリ(lily)も睡蓮(lotus)もありません。なんと花(flower)というカテゴリーさえもないんですよ。それなのに、なぜかデージー(daisy)だけあるので、おかげで花の写真はなんでもdaisy(和名だとひな菊)と解答してしまいます(デージーに初恋の思い出でもあるのでしょうか)。
まあ、気を取り直してこのVGG16を使って花のデータを学習させてみましょう。すると、何もないところから花の識別を学習するより、ずっと少ないデータ量で認識できるようになるのです。
その秘訣は、分類器がすでに画像認識に関して勘所を掴んでいるからです。1000カテゴリ、100万枚以上の画像を認識する訓練を行ってきたベテランであり、その修行過程において13層の畳み込み層と3層の全結合層の構成で、画像認識に適した重み付けが最適にチューニングされているので、少ないデータでも効率的に学習できるようになっているのです。
人間に例えれば、和食の達人はイタリアンでもなんなく作れるようになるとか、将棋の強い人はチェスもすぐ上達するとかいう感じです。
転移学習の方法
転移学習のやり方はいろいろありますが、典型的な方法を図1をもとに説明しましょう。
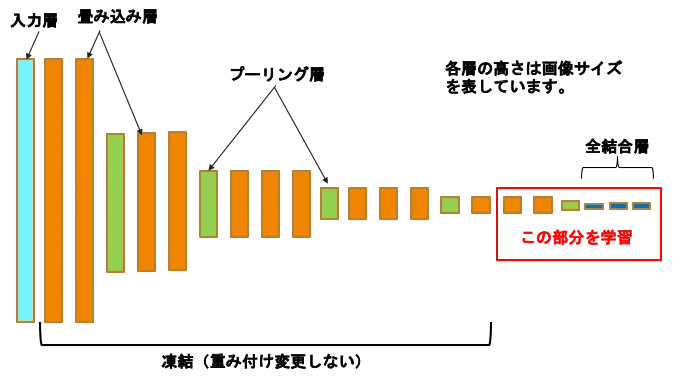
図1:VGG16を使った転移学習
転移学習の基本は、既存モデルが一生懸命学習した結果(重み付け)を頂いちゃうことです。つまり、 誤差逆伝搬(ディープラーニングの仕組みで学びましたね)を繰り返してチューニングされた各ノード間の重み付け(weight)を再利用するのです。
例えば、図1では16層目までを凍結(重み付けを変更しない)して、畳み込み層の最後の2層と全結合層で学習する方法を表しています。凍結(フリーズ)していない部分を再生成して、その部分だけで新たに花の画像を追加学習するわけです。デージーしか花の名前を覚えてなかった学習モデルですが、たぶん16層までの重み付けはいい塩梅だと想定してフリーズし、追加学習により花の名前を出力層から取り出せる分類器を作るわけです。
上記の「AISIA FlowerName」の場合は、VGG16よりも後で登場したResNet18という18層のモデルを使って転移学習で学習しています。1万8千枚の花の画像で1カテゴリー当たりたった50枚程度しかない学習データでしたが、それでも257カテゴリー分の花を認識してくれるようになりました。「この花な~んだ」のページに簡単な技術解説を公開しています。花の画像をアップすればAISIAちゃんが名前を教えてくれますので、どうか試してみてください。
転移学習で何層までフリーズするかは指定できますので、もっとフリーズ範囲を増やして、全結合層のみ変更して学習させる方法もあります。上記に比べると多少精度は落ちますが、学習時間を短くすることができます。
まとめ
今回は、少ないデータ量で機械学習を行う方法として、水増しと転移学習について解説しました。CNN(畳み込みニューラルネットワーク)などのアルゴリズムについては、ブログ後半でもう少し詳しく説明します。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano












