Vol.19でGANを使った生成モデル(Generative Models)を学び、Vol.20で半教師あり学習の認識モデル(Discriminative Models)を勉強しました。今回は、GANと並んで知られている生成モデルのVAEを解説します。また、後半ではGANやVAEなどの生成モデルを半教師あり学習でコントロールする方法や、2つを組み合わせたVAEGANなどについても紹介します。
オートエンコーダー(Auto Encoder)
最初に、図1を使ってオートエンコーダー(自己符号化器)について説明しましょう。オートエンコーダーは、もともとは次元削減(Vol.15)の手法として注目されていました。畳み込みニューラルネットワーク(Vol.16)で、畳み込み層とプーリング層を繰り返すことにより、特徴を圧縮していたことを思い出してください。オートエンコーダーは、このような次元削減するのに有効な手法の1つです。
図1のエンコーダーとデコーダーは表裏一体の関係になっており、デコーダーはエンコーダーと逆の処理を行います。エンコーダーで圧縮した特徴をデコーダーで復元できれば、入力データ(X)の不要な次元を削減した潜在変数(Vol.19)を得ることができています。機械学習の方法としては、出力(X')が入力(X)と一致するように、両者を比較して復元誤差(Reconstraction Error)を求め、誤差逆伝搬(バックプロパゲーション)によりエンコーダーとデコーダーの2つのニューラルネットワークの重みを調節する感じです。
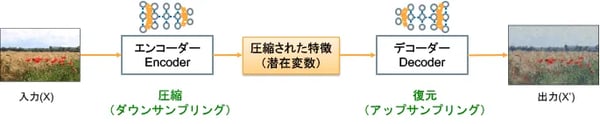
図1:オートエンコーダー(Auto Encoder)
ところで、なぜ、次元削減を行うんでしたっけ。はい、そうです。次の2つの問題を回避するためでしたね。
①勾配消失(Vanishing gradients)
勾配消失問題は、リカレントニューラルネットワーク(Vol.16)で簡単に説明しました。単純にエンコーダーの階層を深くしてゆくと計算対象データが膨大かつ複雑になり過ぎ、誤差逆伝搬(Vol.5)で変更する勾配(誤差をもとに各階層に逆伝搬する重み)が消失する問題です。
②過学習(Overfitting)
過学習(Vol.7)は、特定の訓練データばかりで学習し過ぎて、そのデータだけに強いガリ勉くんになってしまうことでしたね。Vol.8でこれを避けるために、正則化やドロップアウト、k分割交差検証などのデータを間引く手法があることをお伝えしました。また、Vol.16でプーリング層によって特徴の位置感度を低下することで、位置に対するロバスト性を高めると説明しました。これらに共通するのは、データを疎にする(次元削減)ことにより過学習を防いでいる点です。
オートエンコーダーの利用例
オートエンコーダーは事前学習(Pre Training)として次元の削減に使われていました。最近はCNN(畳み込みニューラルネットワーク)やRNN(リカレントニューラルネットワーク)のように、それぞれのアルゴリズムの中に次元削減処理が含まれているので事前学習として使われることはなくなったのですが、今でも次のような用途で使われています。
[RELATED_POSTS](1)学習データのノイズ除去
Vol.6で説明したように学習データに入っているノイズは分類器の認識率を下げてしまいます。オートエンコーダーは、このようなノイズを除去するデータクレンジングなどに使われています。図2では、ノイズなし画像で訓練したオートエンコーダーを使って、入力データ(X)に付いているノイズ(汚れだったり、光の影だったり)を取り除いています。
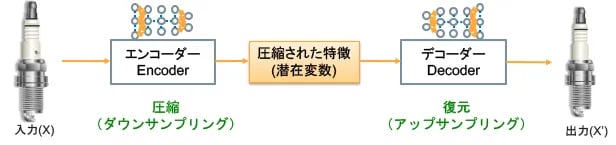
図2:オートエンコーダーによるノイズ除去
(2)異常検知の異常個所特定
図3は、この仕組みを応用した異常検知システムの例です。正常品のデータだけを学習したオートエンコーダーは、検査対象に傷やひびなどの異常があった場合でもそれらを除去した画像(X')を出力します。この出力(X')を元データ(X)と比較して差分を抽出することにより異常検知がなされ、どこに傷やひびがあったかを特定してマークを付けることができます。
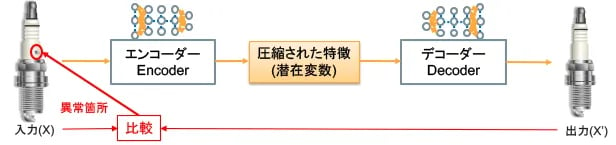
図3:オートエンコーダーによる異常個所特定
(3)圧縮した特徴をもとにしたクラスタリング

特徴を圧縮した潜在変数をz空間上にマッピングすると、特徴に応じた分布の塊ができます。つまりエンコーダーがうまく特徴を抽出できるならば、その圧縮した特徴ごとにクラスタリング(分類)することができるわけです。この使い方については下記の半教師あり学習のところでもう一度説明します。
VAE(Variational Autoencoder)
Vol.20で機械学習には識別(Discriminative)モデルと生成(Generative)モデルがあると述べました。DCGAN(Vol.19)のジェネ君が潜在変数から偽物を作ったのと同じように、オートエンコーダーの後半部分(デコーダー)を使えば生成モデルができます。VAE(Variational Autoencoder)はこのような生成モデルの1つで、DCGANと同じく潜在変数を取得するのに確率分布を使っています。
図4は、VAEの学習イメージです。入力(X)にできるだけ似せた出力(X')を生成するわけですが、復元誤差(Reconstraction Error)をもとに、エンコーダーとデコーダーそれぞれの重みを調整して、潜在変数(凝縮された特徴)を求めています。エンコーダーは入力(X)の特徴を圧縮してN次元のガウス分布の平均μと分散σを出力し、その2つをもとにして潜在変数 Zをサンプリングで求めます。
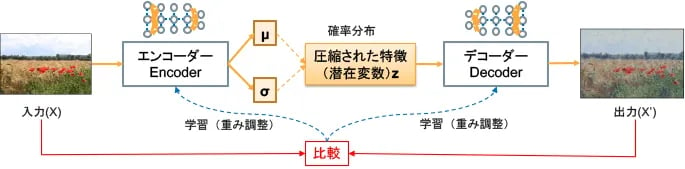
図4:VAEの学習
詳しい説明は図4では省いていますが、実はサンプリングのままだと誤差逆伝搬で学習することができませんのでReparametrization Trickという技を使ってサンプリングを近似計算に変えています。また、Regularization Parameter(正則化パラメータ)により、潜在変数が散らばらないように工夫もしています。記号や用語が出てきてうわっとなった人はVol.11で出てきた確率分布=正規分布=ガウス分布を思い出してください。データの平均値がμ、平均値から散らばる度合いが分散で、その平方根が標準偏差σです。
なお、図3も図4も入力(X)と出力(X')を比較しているので紛らわしいのですが、この2つは処理のタイミングが違います。図4は学習時のモデルなのですが、図3は学習済の分類器を使って異常判定している本番時のモデルです。
あ、最近、浅草の観光案内所でバイトしている麻里ちゃんがやってきました。なんだか、今日はいつになくまじめな面持ちです。
「生成モデルと識別モデルが逆だってことはなんとなくわかったんだけど、でも、やっぱりピンとこないわ」
(う~ん、麻里ちゃんにわかるように説明するとしたら…。じゃあ、こんな説明でどうかな。)
麻里ちゃんがバイト先で外国人のしゃべっている言語が何語なのか見分けるとしようか。そのとき、生成モデルと識別モデルは次のような違いになるんだよ。
生成モデル:各言語について勉強して、その知識を使って見分ける
識別モデル:各言語について勉強はせず、ただ単語や文法の違いで見分ける
ふふ、我ながらナイスな例えだ。どう?いい説明でしょうって思ったところに麻里ちゃんが一言。
「なに、それ? なんだかますますわからなくなっちゃったわ」
半教師ありVAE
オートエンコーダーは、教師なし学習のクラスタリング(分類)にも応用できます。図5を例にして説明しましょう。図3では正常品のみを学習させましたが、図5では正常品と異常品の両方を学習データに使います(ただし、ラベルを付けない教師なし学習)。学習処理において、正常品と異常品の画像10000枚を入り混じえて訓練したとしましょう。学習してゆくうちにエンコーダで圧縮された特徴は、潜在変数Z空間において正常品と異常品とで分布が異なってきます(図6)。
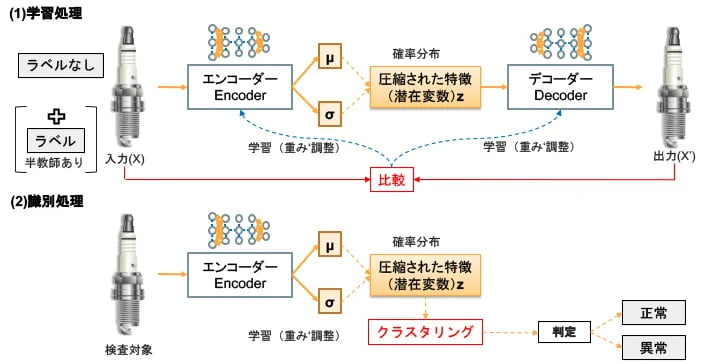
図5:VEAクラスタリングによる異常検知
トレーニングしたエンコーダーを識別処理で使います。未知の品を検査したときにエンコーダーが抽出したた特徴がどこに分布しているかを判定して、正常か異常かを識別するのです。
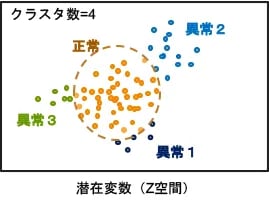
図6:VAEによるクラスタリング
VAEは教師なし学習でも使えるモデルですが、半教師あり学習にすることで精度向上を図ることもできます。図5の学習処理において、入力の画像10000枚のうち100枚にラベル(正常品、異常品)を付けて学習させたとしましょう。グラフベースアルゴリズム(Vol.20)などを用いて、正常品の特徴と異常品の特徴の分布確率を高め、判定精度を向上させることができます。
Conditional GAN(条件付きGAN)
Vol.19でGAN(Generative Adversarial Networks)という生成モデルを紹介しました。ここで登場したDCGANは教師なしの自己学習でしたが、これを半教師あり学習にして、学習をコントロールするConditional GANについても解説しておきましょう。
図7は、ジェネ君(生成器)とディス君(識別器)の学習時にラベル(モネかゴッホか)を付けてあげる半教師あり学習です。ジェネ君の学習の際には「これはモネの絵の潜在変数ですよ」と教えてあげ、ディス君の学習の際には「モネの絵について識別しているんですよ」と教えてあげるわけです。
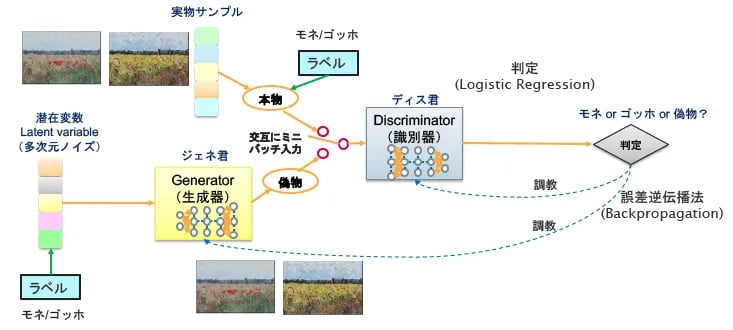
図7:Conditional GAN
通常のGANでは、ディス君は本物か偽物かを見分けるだけですが、Conditional (条件付き)モデルでは、モネの絵かゴッホの絵か偽物かの3つの判定になります。このような半教師あり学習でトレーニングすることにより、ジェネ君に対して「モネの絵を生成して」とか「ゴッホの絵を生成して」というようにリクエストすることができます。
VAEGAN
一般にVAEはGANに比べて生成する画像の鮮明さが劣ります。一方、GANはmode collapse(モード崩壊)という問題を抱えています。モードとは最頻値のことで、ファッションのモード(流行)も同じ語源です。数学の授業でも出てきましたね。mode collapseは、ジェネ君が訓練データの最頻値に分布を寄せてしまい、同じようなデータばかり生成してしまう現象です。GANはこのような問題を抱えていて学習が難しいのです。
この両者の弱点を補うために、VAEの後ろにGANをくっつけたモデルが考えられました。それがVAEGANです(図8)。
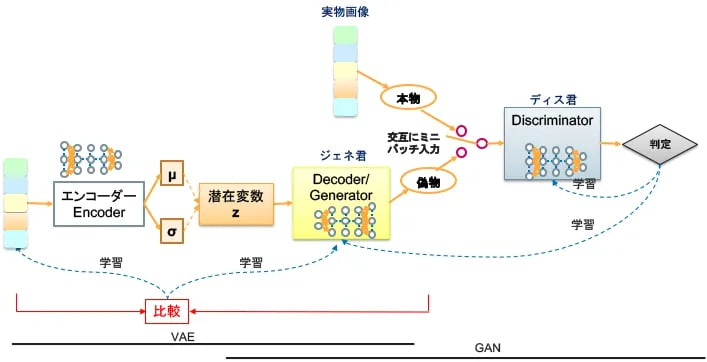
図8:VAEGAN
VAEGANでは、VAEとGANそれぞれが独立して学習します。
・エンコーダー君は、入力画像とジェネ君(=デコーダー君)が生成した復元画像の差を誤差逆伝搬して学習(VAE)
・ディス君(識別器)は、実物画像と偽物画像(復元画像)を見分ける判定結果を誤差逆伝搬して学習(GAN)
・ジェネ君(デコーダー)は、上記2つの誤差逆伝搬で学習(VAE+GAN)
まとめ
麻里ちゃんへの説明はイマイチでしたが、生成モデルと識別モデルの違いわかりましたでしょうか。一般にオートエンコーダーは識別モデルでVAEやGANは生成モデルとされますが、オートエンコーダーの生成機能を使って異常検知したり、VAEをクラスタリングに使ってみたり、VAEとGANを組み合わせてみたりとバリエーションが豊富です。さらに、教師なしだけでなく、Conditionalモデルにして教師あり/半教師ありなどを組み合わせて精度を高めたりと今なおすごいスピードで進化し続けています。
さて、ここでちょっと寂しいお知らせです。実は、このブログは今回で終了です。また、機会があれば、付け足すか、別のブログを書き始めるかしたいと思います。長い間のご愛読ありがとうございました。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano











