はじめに
「教師なし学習」は膨大なラベル付けの作業(アノテーション)がいらずデータを準備しやすい。でも、学習が難しくて「教師あり学習」のように思ったような成果を出させるのがなかなか難しい。そこで両方の良いとこ取りをしようと注目されているのが「半教師あり学習」です。半教師あり学習は識別モデルと生成モデルで使われていますが、今回は識別モデルについて解説します。
半教師あり学習とは
Vol.9で教師あり学習(Supervised Learning)の「分類」と教師なし学習(Unsupervised Learning)の「クラスタリング」の比較を行いました(表1)。この対比は教師ありとなし全般に通ずるもので、教師ありは「学習が容易で精度が高いアウトプットを得られる」、教師なしは「学習データや学習の手間がかからない、予想外の結果が得られる」などのメリットがあります。
|
|
学習方法 |
目的変数 |
メリット |
|
分類 (Classification) |
教師あり |
あり |
学習が容易 分類精度が高い 目的に合った分類をやってくれる。 |
|
クラスタリング (Clustering) |
教師なし |
なし (分類数のみ指定) |
学習データが不要 ラベル付けが不要 学習の手間がいらない 予測外の結果が得られる |
表1:分類(教師あり)とクラスタリング(教師なし)の違い(再掲)
みなさんは、中高時代に部活やってましたか。普通の教師が顧問をやったりするので、きちんとした指導もなくやみくもにトレーニングしていることが多かったように思います。そして、大人になってもゴルフでおんなじ非効率的な学習を繰り返していたりします(^^;)。これ、本当はコーチがちょっとポイントをアドバイスしてくれるだけで、ぐーんとトレーニング効率が高まるんですよね。
半教師あり学習(Semi-Supervised Learning)は、この原理と同じです。少量の教師データ(ラベル付きデータ)を用いることで、大量のラベル無しデータを活かすことができ、より簡単に学習させることができるモデルなのです(図1)。人間だってちっちゃいころに、「これは猫さん」「これはワンワンよ」と何回か教えてもらっただけで、後は自分でたくさんの猫や犬を見て自己学習しています。2012年にGoogleが大量の猫の写真を教師なし学習して、猫を認識できる分類器を作ってセンセーショナルを起こしましたが、人間の覚え方を考えれば、半教師あり学習の方がずっと効率的に学習できそうだと分かりますね。
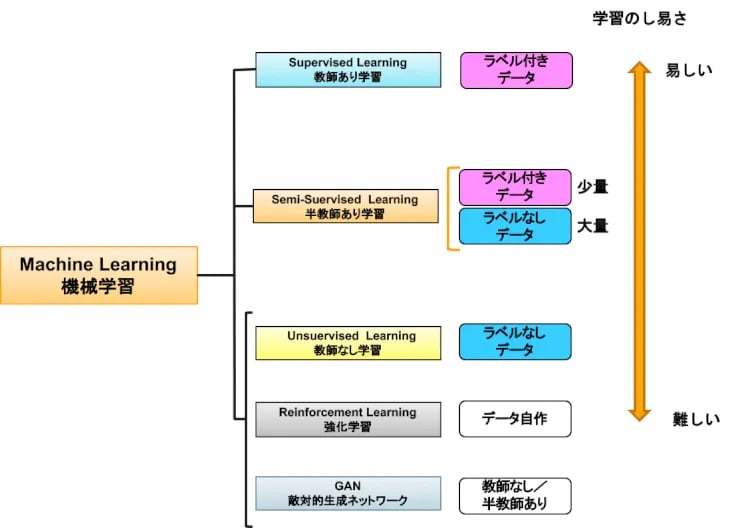
図1:教師の有無と学習の容易さ
半教師あり学習のモデル
図2に半教師学習のモデルを整理してみました。半教師あり学習には大きく分けで識別(Discriminative)モデルと生成(Generative)モデルがあります。GAN(Vol.19)の回でディス君とジェネ君の役割を学んだのでイメージはつきますね。そして、識別モデルは、ラベル付きデータでの分類器を使ってEM(Vol.15)を繰り返す分類器に基づくベースとデータの分布を基にラベルを付けてゆくデータに基づく手法の2種類に分かれます。以下、これらのモデルについて順番に説明していきましょう。
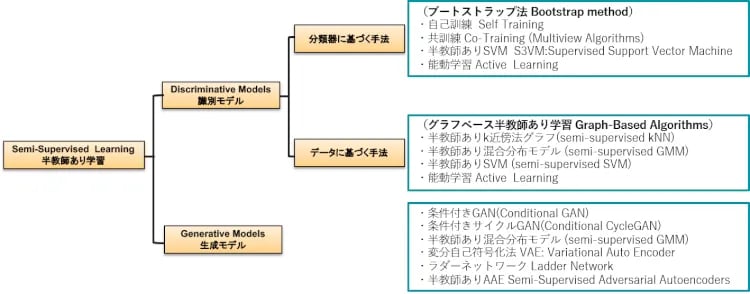
図2:半教師あり学習のモデル
分類器に基づく手法…ブートストラップ法(Bootstrapping)
分類器の予測結果にもとづく手法の総称がブートストラップ法です。ブートストラップとは、”自動・自給”という意味で、子供が自分で犬や猫を自己学習してゆくのと似たモデルです。ブートストラップ法には、分類器が1つの自己訓練(Self Training)と複数の分類器を使う共訓練(Co-TrainingまたはMultiview)があります。
ブートストラップ法は古くからあるルールベースの分類法で、出会った相手を次々に仲間にしてゆくロールプレイングゲーム(RPG)です。基本は、図3に示す2つの処理を繰り返す方法です。まず、ラベル付きデータとラベル無しデータが入り混じった状態から、ラベル付きデータだけで分類します①。その結果を基に、ラベル無しデータの(こいつはこのラベルのはずだという)信頼度の高いデータのみラベルを付けます②。そして、これらのデータも加えたラベル付きデータだけでもう1度分類します①。これを繰り返して次々に自分でラベルを付けてゆくのです。
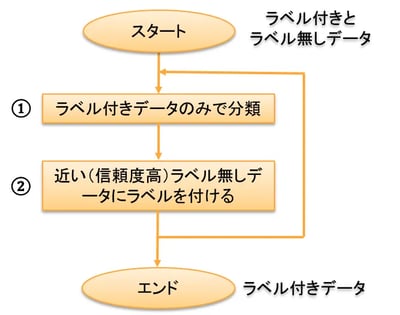
図3:ブートストラップ法
このときの分類に使うのは「教師あり学習」の分類器です。k近傍法やSVM(サポートベクターマシーン)、デシジョンフォーレスト、ロジスティック回帰など、さまざまある分類アルゴリズムのうち最も適していると思われるものを使います。例えば、分類器のアルゴリズムがSVM(Vol.13)のものが半教師ありSVM(Support vector machine)となります。
(1)自己訓練(Self Training)
半教師ありSVMを使って、Self Trainingの仕組みを説明します。題材はVol.13で使った営業と管理部の性格診断データです。営業向きか管理部向きかという職掌と性格との関係を調べようとして営業4人、管理部4人の合計8人の性格診断をしたところ図4のような分布となったとしましょう。これだとデータがまばら(data sparseness)なので両者をどう分類した方がいいかわからず、とりあえず行動スタイルが積極的か慎重かだけで分類しています。
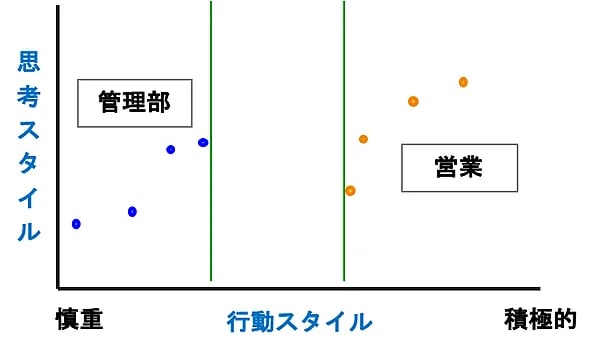
図4:教師ありデータのみ

ここに他社の性格診断の結果も加えてみました(図5)。こちらはラベルが付いていないので、誰が営業で誰が管理部なのかわかりませんが、data sparsenessが解消されて人間なら一目でどこで区切ればよさそうか見えてきます。AIは、一目で見分けるってのが苦手なので、ここでSelf Trainingにより図3の②の処理を行います。
図6はラベルなしデータのうち、信頼度が高いデータ(赤丸の8つ)に青とオレンジのラベルを付けてSVMで分類したものです。ラベル付きデータが倍の8個ずつになったので、今度は斜めの線で区切るのがいいと分かるわけです。これを繰り返して、自分で次々とラベルなしをラベルありにひっくり返していくのがブートストラップ法のSelf Trainingなのです。
赤丸のデータの選び方には、信頼度が閾値以上のデータを選ぶ、信頼度の高い順にk個選ぶ、信頼度の重みを勘案して区切る場所を決める、などいくつか方法があります。行動スタイルだけでなく思考スタイルも加味して斜めの境界線で区切ることにより、積極的と慎重の中間の人たちは、感覚的な人が営業、論理的な人が管理部という関係が見えてきます。あ、あくまでも説明のための架空の設定ですので、この性格分析は信じないでくださいね。
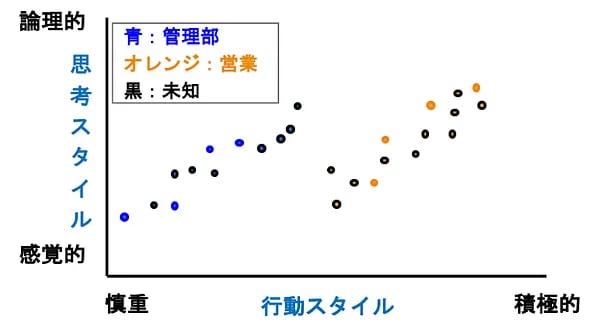
図5:教師ありデータと教師なしデータ
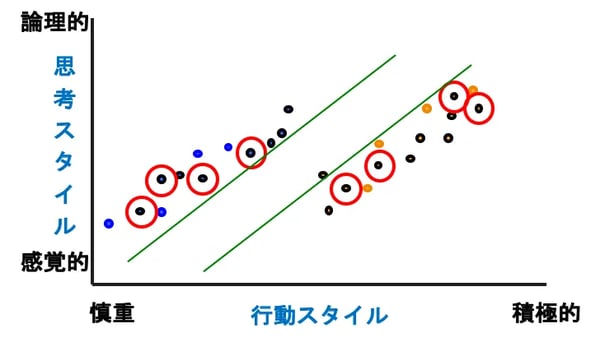
図6:高信頼度のデータにラベル付け
(2)共訓練(Co-Training)
Self Trainingの弱点は、信頼度に基づいて「エイ・ヤー」と気合でラベルを順に付けてゆく方法なので、最初に間違えると間違いが増幅される点です。ブートストラップ法である限り、真の分布に基づく最適な分類器を作るのは無理なのですが、この弱点を少しでも解消しようと考え出されたのがCo-Trainingです。
Co-Trainingの基本アルゴリズムはSelf Trainingと同じですが、今度は図7のように分類器を2つ使います。分類器1と分類器2でラベル付きデータLをそれぞれ分類します。ラベル無しデータUからランダムにデータプールU´を作り、このデータをそれぞれの分類器で分類して信頼度に応じてポジティブ(赤丸)をp個、ネガティブをn個選び、その結果をラベル付きデータLに反映します。これをk回繰り返してラベル付けを行ってゆくのですが、2つの分類器がポジティブだけでなくネガティブな意見も言い合うアンサンブル学習(Vol.8)なので、分類器が1つの時よりも独断と偏見が防げるわけです。
Co-Trainingはデータの2つの素性が独立して、それぞれが有効に分類できるときに適しています。素性とは分類するための特徴のことで、例えば図4における行動スタイルと思考スタイルなども素性です。ただし、この2つは独立していない可能性がありますし、思考スタイルだけではうまく分類できないのでCo-Trainingに適用するのは不向きな素性と言えます。よく引き合いに出される素性はCo-Trainingの提唱者Blum氏が例にあげたもので、Webページを分類するのに、書かれている文章を素性とする分類器(View1)とハイパーリンクの文字を素性とする分類器(View2)です。
なお、Co-Trainingは2つの分類器ですが、複数の分類器を使ってラベル無しデータを予測する方法を総称してMultiview Algorithmsと言います。この場合、意見が割れるところは多数決で決定するなどの方法が取られます。
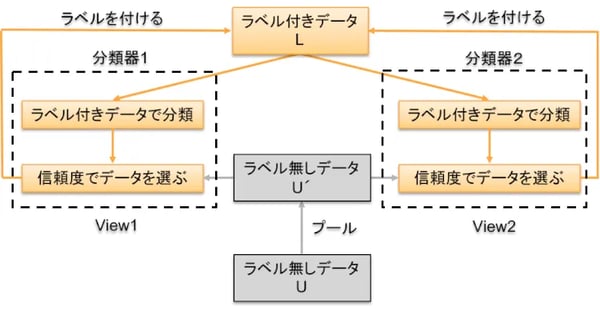
図7:Co-Training
|
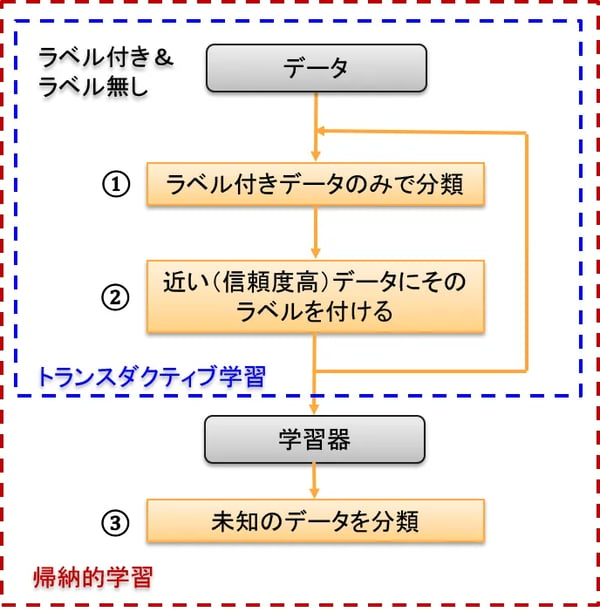
図3のようにラベル付きデータで学習して、ラベルなしデータにラベルを付けてゆく処理をトランスダクティブ学習と呼びます。トランスダクティブ学習はラベルなしデータがラベル付けされれば終了ですが、完成した分類器をつかって未知のデータを分類するところまで行うことを帰納的学習と言います。まあ、言葉の定義だけですが、これらの言葉はよく出てくるので覚えておいてください。
図8:トランスダクティブ学習と帰納的学習 |
(3)Active Learning(能動学習)
アクティブラーニングは、運用しながら追加学習する方法でしたね(Vol.4)。半教師あり学習に、このアクティブラーニングを取り入れる方法もありますので紹介します。図9の分類器の処理はSelf Trainingで、信頼度の高いデータにせっせとラベルを付けてラベル付きデータとしています。一方、信頼度がそこまで高くなかったデータに対して人間がアノテーションを行い分類器を助けています。図7のCo-Trainingにおける分類器の1つを人間に置き換えて、分類器同士で判断するよりもさらに精度を高めているわけです。
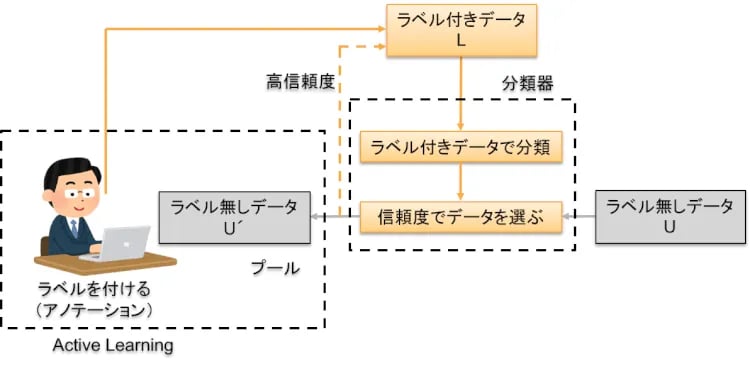 図9:Active Learning
図9:Active Learning
データに基づく手法…グラフベースアルゴリズム
ブートストラップ法は、分類器のアルゴリズムで分類する方法です。一方、グラフベースアルゴリズムは、ラベルありラベルなしに関わらずデータ分布をもとにグループ分けする分類法です。データとデータの近さ(類似度)をもとに、”近いものは同じラベルだろう”と考えて、ラベルありデータからラベルなしデータにラベルを伝播します。データが近いものを図るアルゴリズムにはいろいろありますが、ここではk近傍法と混合ガウスモデルを紹介します。
(1)半教師ありk近傍法グラフ(semi-supervised k-Nearest Neighbor)
k近傍法は、あるラベルなしデータがどちらのグループに属するかをそのデータの同心円を描いて、多数決で多い方に色を染める類は友を呼ぶ手法でしたね(Vol.14)。このラベルなしラベルありを逆にして、あるラベルありデータをもとに同心円を描いて、その中に入るデータを同じラベルに染める方法が半教師ありk近傍法グラフです。
図10を使って説明しましょう。ラベルありデータ(青とオレンジ)を中心にラベルなしデータがk個(ここではk=2)含まれる円を描き、その範囲に含まれたデータを同じ色に染めます。これを繰り返して次々とラベルを付けてゆくわけです。
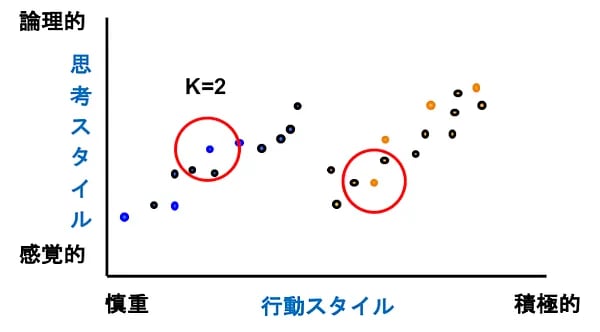
図10:半教師ありk近傍法グラフ
(2)半教師あり混合ガウスモデル(semi-supervised Gaussian mixture models)
k近傍法は、近い順番にk個選ぶという単純な方法なので、分布によってはかなり遠いデータも選んでしまう場合があります。そこで、もう少していねいに、近さを確率計算で求めようとしたものが混合ガウスモデルです。混合ガウスという言葉は、クラスタリングの回(Vol.15)で出てきました。ガウスとは正規分布(=確率分布)のことで、混合とは複数の要素(次元)を重ね合わせることでしたね。つまり、複数の要素ごとに近さを確率で求めて、それを重ね合わせて近さを求め、閾値以上の確率のものを”近い”と判定してラベル伝搬するわけです。
[RELATED_POSTS]
まとめ
半教師あり学習の識別モデルのイメージがつかめましたでしょうか。ラベルありデータだけだとうまく分類できない場合に、ラベルなしデータによりdata sparsenessを補うこと、ラベルありデータに”近い”データにラベルを付けてゆく手法であること、分類器により”近さ”を測るブートストラップ法とデータ分布により”近さ”を測るグラフベースアルゴリズムがあること、などを勉強しました。次回は引き続き半教師あり学習をテーマに、今度はデータ生成モデルを説明します。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano











