はじめに
ここ数回は機械学習のアルゴリズムを勉強してきたわけですが、今回からはいよいよディープラーニングのアルゴリズムに入ります。最初は、最も代表的なモデルである畳み込みニューラルネットワーク(Convolutional neural network)について説明しましょう。
畳み込みニューラルネットワーク
畳み込みニューラルネットワーク(CNN)は、画像認識などによく使われるニューラルネットワークの構造ですが、最近では自然言語処理(NLP)など他の用途にも使われ始めています。これを一言でいうと、殺人現場から犯人の痕跡や特徴を割り出して追及を続け、ついに犯人を見つけ出す敏腕刑事です。って説明しかけたところに、麻里ちゃんが向こうから歩いてきました。
「畳み込みって、スポーツや討論などで相手を圧倒するときに使う言葉だけど、なんでこんな名前なの?」
はい、出ました。ほとんどの人が意識せず使っているのに、なんでそんなことに疑問を持つのでしょうか(ま、そこが彼女のいいとこなんですけど…)。
英語がConvolutional Neural Networkでその直訳だから。という説明じゃあ…、納得してくれないでしょうね。実は、数学で畳み込み級数(telescopingseries)というものがあって、Wikiによると「各項からその近くの後続または先行する項と打ち消しあう部分をとりだして、次々に項が消えていくことで和が求まるような級数」です。telescopingは望遠鏡、つまり望遠鏡の筒を畳み込むような構造を表しているから畳み込み(Convolutional)という名前なのです(釣り竿でもいいですね)。
なので、
「その言葉の使い方自体が派生であって、望遠鏡の筒を畳み込むような構造のネットワークだからそういう名前なんだよ。」
と回答しておけば、なんとか無事に切り抜けそうです。
はい、またまた麻里ちゃんの登場により、話が妙なところからスタートしてしまいました。でも、この望遠鏡筒のイメージを持っていると、実はこの後の説明が頭に入りやすいのです。気を取り直して、Vol.6の転移学習の際に使ったVGG16の図をもとに、CNNの構造について説明しましょう。
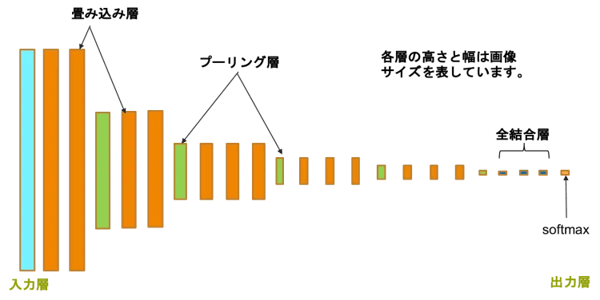
図1:VGG16のCNN構造(再掲)
〇入力層(Input Layer)
画像認識の場合、入力層は画像データになります。図1を見ると、いくつかの畳み込み層の後にプーリング層(Pooling layer)があって、それを何回か繰り返した後に全結合層で全結合した多層パーセプトロンが配置される構成になっています。ここではデフォルメした層で表していますが、各層はVol.5で説明したパーセプトロンモデルのノードから構成されています(図2)。
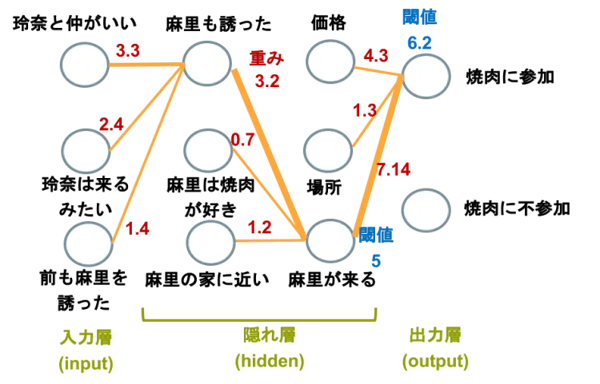
図2:ニューラルネットワークモデル(再掲)
畳み込み層(Convolutionallayer)
[RELATED_POSTS]畳み込み層は、元の画像からフィルタにより特徴点を凝縮する処理で、次のような特徴があります。
・畳み込み層は、元の画像にフィルタをかけて特徴マップを出力する(構成性)。
・特徴マップのサイズは元の画像より少し小さくなる(元画像とフィルタのサイズによってサイズが変わる)。
・画像全体をフィルタがスライドするので、特徴がどこにあっても抽出できる(移動不変性または位置不変性)。

・フィルタは自動作成され、学習により変わってゆく(誤差逆伝搬)。
・フィルタの数だけ特徴マップが出力される。
CNNの説明は、画像の文字がバツなのか判定するRohrer氏の解説がわかりやすいです。今回は、それをオマージュしてマルを見分ける流れで説明しましょう(図3)。マルかバツか、人間なら子供でも一目でわかりますね。でも、コンピュータは全体のイメージで判断できず、ピクセル単位で白(=-1)か黒(1)で画素を認識するしかできません。まるで「群盲象をなでる」なんです(あ、この言葉、知ってますか?)。
全く同じ大きさ、形の文字なら、ピクセルの全体配置をまるごと記録してそれと比較すればいいでしょう。でも、その方法だと文字が変形したり回転したり縮小するだけで違うものとみなされます。人間のように、こんな文字でも読める柔軟性を持った分類こそAIの十八番(おはこ)なのです。
図3では、元の画像(9×9ピクセル)を特徴=フィルタ(3×3ピクセル)ごとに比較しています。以前はこのようなフィルタを人が用意していたのですが、ディープラーニングでは学習により自動作成され、学習が進む中で変化します(青のフィルタなんかはマルの特徴をいい感じでとらえていますね)。元画像が、各フィルタの特徴に一致するかどうかを数値計算するのが畳み込み計算です。元の画像(9×9ピクセル)がどのような計算で右の特徴マップ(7×7ピクセル)の数値になるのか図4で説明しましょう。
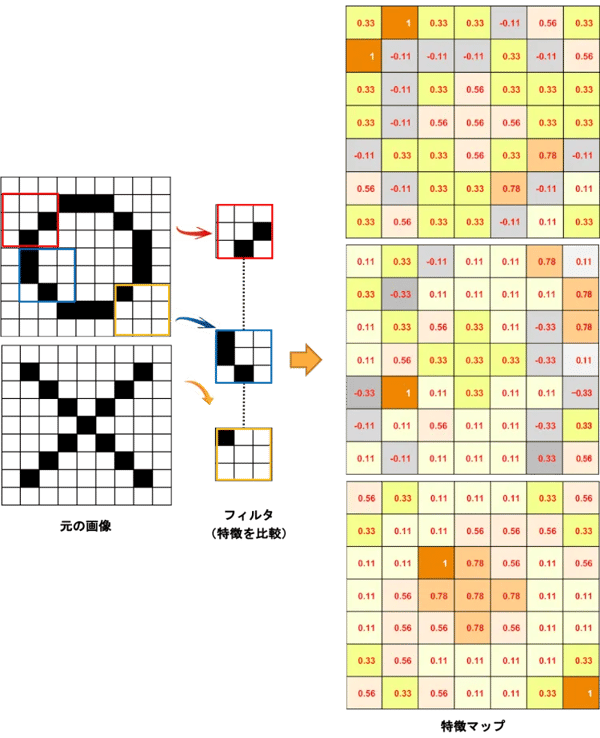
図3:畳み込み層のフィルタ処理
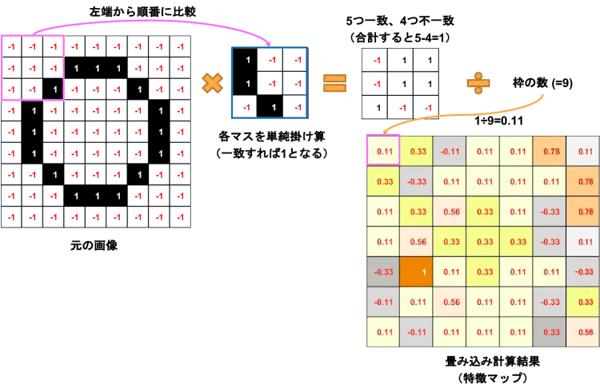
図4:畳み込み計算方法
・元の画像の左上から1ピクセルごと順番にフィルタ(特徴)と一致するかを比較する。
・黒が1、白が-1なので、数値が一致すれば黒は1×1、白は-1×-1でどちらも1になり、不一致なら-1になる。
・9マスの値の合計を9で割った数を一致度として特徴マップにセットする。
例えば、左上をフィルタと比較すると、一致5つ、不一致4つなので、9マス合計は5×1+4×-1=1となり、それを9で割って0.11となります。この数値が1に近いほど一致度が高く、-1に近づくほど不一致ということになります。左上から順番にやっていくと、9×9マスが7×7マスになるのがわかりますね。元の画像をフィルタ処理したものを特徴マップと言います。黒が1、白が-1としたOn/Offの数字ではなく、一致度を表す数値ということを混同しないように注意してください。
これらの畳み込み計算は単純計算なのですがそれなりに量があります(私は電卓片手にやったので肩が凝りました)。この例はモノクロなのでチャネルは1つですが、カラーだとRGBで表されるので3チャンネル(元の画像が3枚)となり、その分フィルタの数も3倍となり、出力(特徴マップ)も3倍になります。普通の写真を見分けることを想定すると、特徴フィルタの数や深層学習の層の深さから膨大な計算になることが容易に想像できます。
Vol.2のAIチップの説明で、汎用的な処理向き(if~else~が得意)のCPUと比べ、1個当たり数十~数千コアを持つGPUはシンプルな処理向き(for~loopが得意)と説明しましたが、まさにこのような像をなでるような計算がGPUの十八番なのです。
|
この計算処理を少し楽にしてくれるのがRectified Linear Unitsという活性化関数です。これはxが正のときはF(x)=ax、負のときはF(x)=0となる関数でランプ関数と呼ばれています。 畳み込み計算結果のマイナス数値は一致度が低いので、割り切って0とする処理を行います。活性化関数とは、入力信号の総和をどのように判定(活性化=発火)するか計算するもので、全結合層の最後にマルかバツかを判定するsoftmaxも活性化関数です。 |
プーリング層(Poolinglayer)
図1をもう一度ご覧ください。何回か畳み込み処理を繰り返した後にプーリング層があります。プーリング層は前の画像よりサイズがだいぶ小さくなっていますが、何をしているのでしょうか。
プーリング層では、特徴として重要な情報を残しながら元の画像を縮小します。4つのピクセルを1ピクセルに凝縮する図5の例で説明しましょう。畳み込み計算結果の左上から順番に4ピクセルずつ抽出して、4つのピクセルの最大値を代表として選び1ピクセルとして画像にセットします。左上から4マスずつ抽出するので特徴マップが奇数だと最後が少しダブるのですが、プーリングされた画像を見るときちんと元画像の特徴を持ちながら、4分の1に凝縮されている感じがうかがえます。このプーリングされた画像が、次の畳み込み層の入力画像になって、前の層とは別の新たなフィルタ群と比較されるわけです。
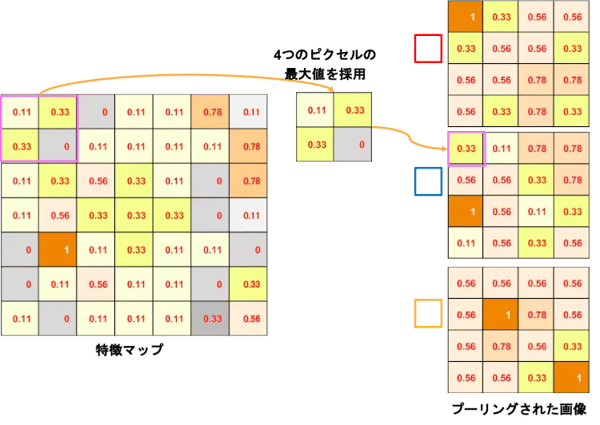
図5:プーリング層の凝縮処理
特徴を残しながら情報量を削減するってのは、次元の呪い(Vol.15)から逃れるための次元削減と同じですね。特徴点を抽出しては圧縮し、特徴点を抽出しては圧縮し、という処理を繰り返し、下流工程の計算処理を楽にするのがCNNというディープラーニングなのです。イメージとしては、濃縮を繰り返して純度を上げてゆく化学の実験でしょうか。
プーリングには、特徴の位置感度を低下することで、位置に対するロバスト性を高める効果もあります。プーリング処理することによって、画像が数ピクセル移動したり、回転したりしても、それらの違いを吸収してほぼ同じ値を出力してくれるようになります。
全結合層(Fully Connectedlayer)
Vol.5で勉強した多層パーセプトロンで結合を表すと図6のようになります。ノードからノードに全て結合するのが全結合で、全てでない手抜きが非全結合です。実は畳み込み層では、全結合を計算すると処理が膨大になってしまうので、非全結合で処理していたのです。
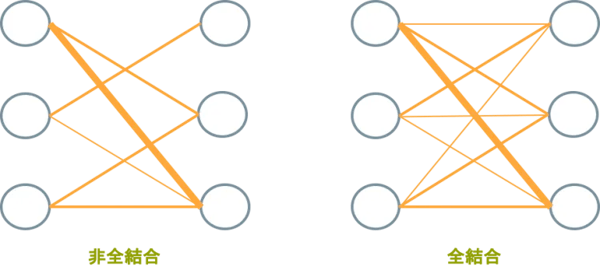
図6:非全結合と全結合
あ、麻里ちゃんがまた来た。嬉しいけど怖い…。
「これまでの畳み込み層の説明のどこでノードが登場していたのよ?」
はい、ごもっともです。確かに、一言もノードって言っていませんでした。それでは図5の一部を再掲し、ノードで表してみましょう。図7を見ればもうお分かりですね。隣り合う9マス(9ノード)ごとずらしながら3ノードに結合するという非全結合で処理していたわけです。プーリング層でも同じです。こちらの方は隣り合う4マス(4ノード)ごとに1ノードに結合していたわけです。
まだ、データ圧縮が十分行われていない段階で全結合計算をすると、計算ボリュームが膨大になるので、こんなふうに割り切った計算をしていたわけです。9×9の81ノードが7×7の49ノードに全結合している状態と比べてみると、大幅に計算が削減されていることがわかります。さらに、結合1本ずつに重みを付けると大変なので、複数の結合でウェイトを共有するという技術も使われています。
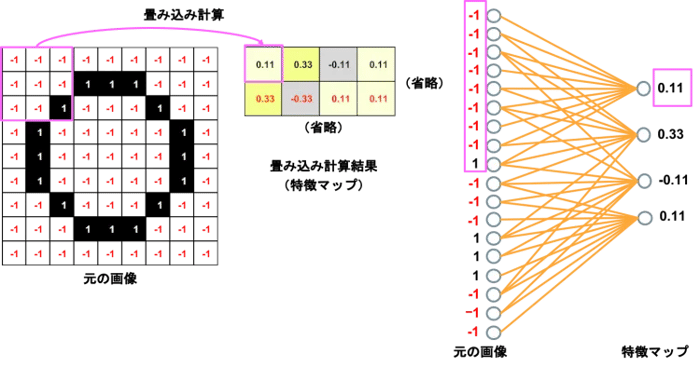
図7:畳み込み層の非全結合
今回はマルかバツかの2択なので出力層は2ノードです。説明の都合上、途中を飛ばして上記プーリングの3つの結果投票でマルかバツかが決まるとしましょう(図8)。投票と言っても、単純な多数決ではなく重みに差があります。例えば青の特徴はマルだけしかないのでマルに対する重みが大きく、赤と黄色の特徴はバツにもあるので重みが小さいとしましょう。青の子孫の意見が強く、赤と黄色の意見が弱いのは、図2の麻里ちゃんの焼き肉と同じ原理です。赤君と黄色君が、何回かバツと間違えてしまって、自分(フィルタの形)を変える努力もしたんだけれど、だんだん信頼(重み)を失っていったという悲しい物語に興味がある人は、Vol.5の誤差逆伝搬を読み返してください。
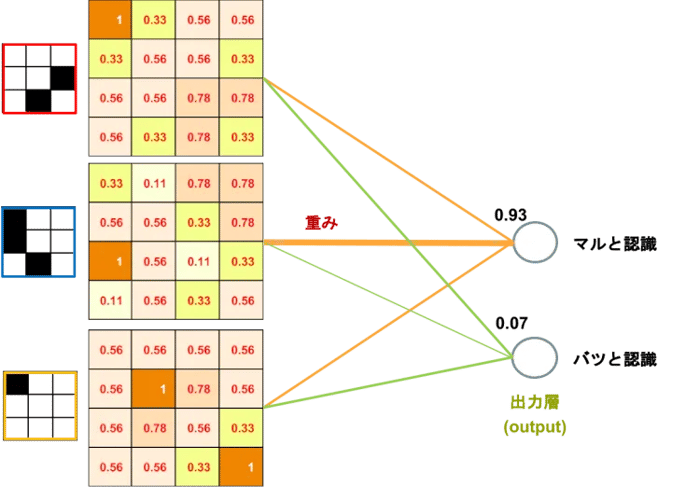
図8:全結合層による判定
出力層(Outputlayer)
図1の出力層にsoftmaxという説明があります。これも活性化関数と呼ばれるもので、裁判長のような役割を果たします。出された証拠をすべて吟味し、「うん、本件は0.93対0.07でマルだな」って感じに判決するための確率計算式だと思ってください。2択だとピンとこないかも知れませんが、例えば257種類の花の名前を当てるような場合には重宝します。
まとめ
冒頭で、CNNは敏腕刑事と説明しかけましたが、漠然とした状況の中から手掛かり(特徴)を見つけ、それを追及していってついに動かぬ証拠をつかむ執念が畳み込みたる由縁です。そして、フィルタは刑事の助っ人で、犯人の顔を割り出す似顔絵描きです。似顔絵描きは、その人の特徴をつかむ天才です。実際のまま描くのはなく、デフォルメするからこそ似ています。刑事と似顔絵描きのタッグで深く深く迫られ、さまざまな重みの状況証拠を突き付けられるので、ついに「はい、私が殺しました」と白状してしまうのです。
梅田弘之株式会社システムインテグレータ:Twitter@umedano












