はじめに
Vol.9で「学習方法」と「統計学」と「アルゴリズム」の三角関係のうち、「学習方法」と「統計学」の関係を紐解きました。今回は、もう一辺の「統計学」と「アルゴリズム」の関係について解説します。ディープラーニング(ニューラルネットワーク)ではない、従来からの機械学習についても、ここで理解しておきましょう。
統計学とアルゴリズム
Vol.9では、「教師あり学習」、「教師なし学習」、「強化学習」という3つの学習方法と「回帰」「分類」「クラスタリング」といった統計学の関係を図示しました。今回は、同じ図に「線形回帰」や「ロジスティック回帰」などのアルゴリズムを紐付けてみました(図1)。この中から、今回は「回帰」に使う代表的なアルゴリズムを解説します。
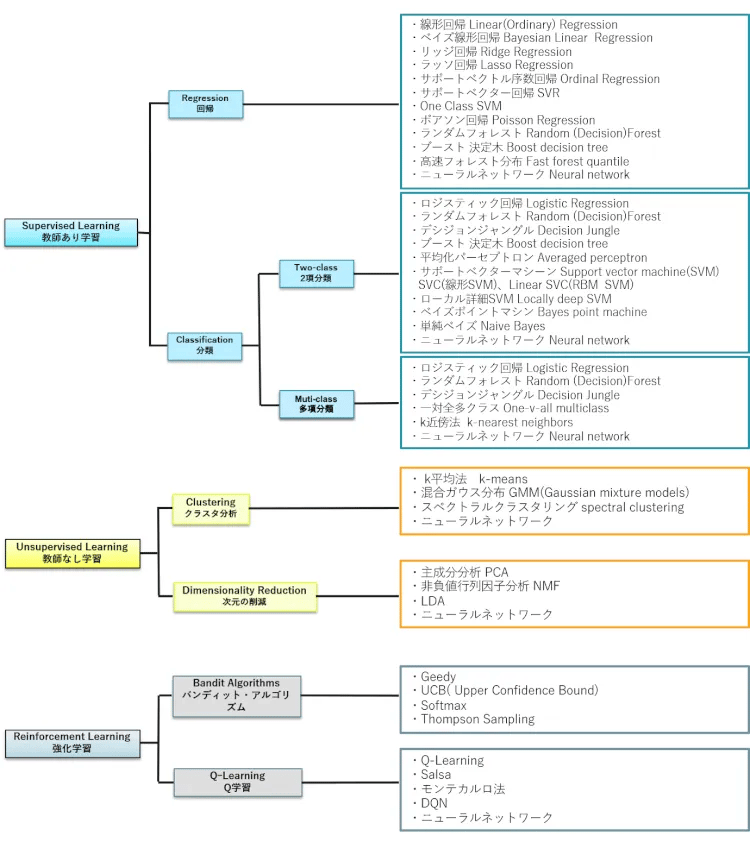
図1:機械学習のアルゴリズム
回帰(Regression)
回帰は、Vol.8の正則化(Regularization)のところでちらっと出てきましたね。そこでは回帰分析を「たくさんのデータをプロットしたときに、その関係性を表す線(関数)を見出すこと」と説明しました。例えば、図2Aのようなデータ分布があった場合に、X軸とY軸の関係を関数で表すことができれば、未知のデータ(x)に対する値(y)を予測することができます。
データ分布から関数を導き出すには、通常、最も近そうな関数(基底関数)を選んで、係数を調節して当てはめる方法が取られます。例えば、図2Aのデータ分布に3次関数で当てはめると図2Bのようになり、なんとなくよさそうですね。

図2A:データ分布

図2B:線形回帰(3次関数)
実際には、こんなにシンプルな関数で当てはまるケースばかりではないので、多項式基底やガウス基底など、より複雑な基底関数を使ってデータを線でなぞります。このとき、データのノイズ(測定誤差により、本来の関数から離れてしまうデータ)に惑わされると過学習となってしまいます。そのためのノイズ対策が、正則化で説明したリッジ回帰とラッソ回帰方法でしたね。今回は、もう1つのノイズ対策方法としてベイズ線形回帰を紹介します。
(1)ベイズ線形回帰
ベイズ線形回帰を理解するために、まず、ベイズ確率という概念を抑えておきましょう。
・ベイズ確率
Vol.10のメイド喫茶で麻里ちゃんとじゃんけんする例で説明しましょう。10回じゃんけんして、麻里ちゃんがパーを5回、グーを3回、チョキを2回出したとしましょう。次に麻里ちゃんがパーを出す確率はいくつでしょうか。
じゃんけんですので普通に考えればどの手を出すかは1/3ずつの確率です。でも、「あれ、ひょっとして麻里ちゃんはパーを出しやすい癖があるのでは?」と感じたなら、自分なりに思う確率は1/3よりも大きくなるでしょう。このように個人の主観が入った確率のことをベイズ確率と言います(ベイズさんの理論です)。
ベイズ確率には信頼度(確信度)があります。例えばパーを出す確率を40%くらいと思っているのは、頭の中では図3ののような確率分布で考えているわけです。そして、その思い描く確率は最初1/3だったものが10回やって2/5になり(茶線)、100回やって1/2になり(青線)、というようにじゃんけんをするうちに変化していきます。
また、信頼度も同時に変化してゆきます。この例では、じゃんけんをやる度にだんだん確信度が高まって分布曲線は図3青線のように尖った形になっていきます。このように探索(じゃんけん)するたびに確率と信頼度が変わることをベイズ更新と言います。
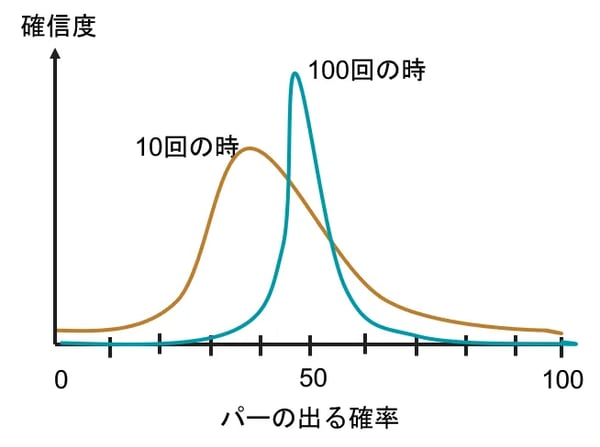 図3:ベイズ確率における確率と確信度の変化
図3:ベイズ確率における確率と確信度の変化
・ベイズ線形回帰
ベイズ線形回帰は、データ分布から関数を導き出す際に、このベイズ確率を使います。信頼度の高そうなデータと信頼度の低そうなデータ(ノイズっぽい)を同等に扱わず、重みを変えるのです。

あれ、なんだかVol.8で学んだ下記の正則化と同じようですね。そうです、ベイズ線形回帰もまた、アプローチは違えどノイズを過小評価して過学習を防ぐ正則化と同じ結果になるのです。
L1ノルム正則化(Lasso回帰):極端なデータの重みを0にする
L2ノルム正則化(Ridge回帰):極端なデータの重みを0に近づける
(2)サポートベクター回帰
似たような回帰アルゴリズムにサポートベクター回帰があります。ディープラーニングが脚光浴びる前によく使われた手法ですが、今でもよく使われていますので抑えておきましょう。サポートベクター回帰を理解するために、まず、サポートベクターマシーンを説明します。
・サポートベクターマシーン(Supportvectormachine)
サポートベクターマシーン(SVM)は、教師あり学習によるパターン認識モデルです。SVMは、マージン最大化という基準で分類を行います。図4を使って説明しましょう。
図4は、営業部門と管理部門の人たちの性格診断を行った際の分布です。X軸は行動スタイルで、右に行くほど積極的で、その逆は慎重な性格です。Y軸は対人性で、社交的か内向的かに分けています。教師あり学習なので営業をオレンジ、管理部門を青というように色分けすると、(説明の都合上)見事に職掌によって性格分布が偏っていることが見て取れました。
これを社員の適性診断に利用しようと、青いデータ群と赤いデータ群を線形識別(直線で区切る)で分類するとしましょう。縦のオレンジの川(行動スタイルだけ)で区切るより、天の川のように斜めに横切る方が川幅が広く取れますね。このように区切る際に、川の中心から川岸までの距離をマージンと言います。
[RELATED_POSTS]マージンの最大化というのは川幅を一番大きく取ることです。すなわち、SVMでこの分布をクラス分けする場合は、オレンジではなく、緑の川で分類することになります。なお、データの中で川の中心に最も近い位置(川岸)にいるものをサポートベクトルと言います。
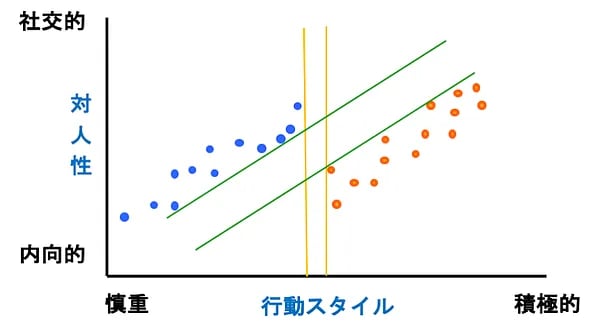
図4:サポートベクターマシーン(SVM)
・ソフトマージン
データには、ノイズ(この場合は個人差)がつきものです。例えば、図5の赤丸で囲んだドットのように他の集団とはちょっと違ったところにデータがあった場合、これらも忠実に考慮して線を引く(ハードマージンと言います)のは困難になります。
そこで、ある程度はノイズがあると考えて、誤差を許容して線を引く方法が使われており、これをソフトマージンと呼びます。なお、上記は線形識別(直線で区切る)の例でしたが、もちろん非線形識別(曲線で区切る)場合もあります。
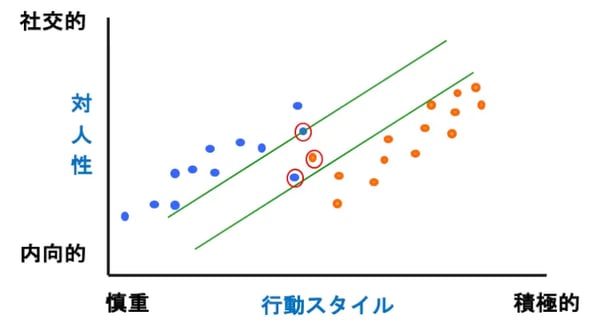
図5:ソフトマシーン
・サポートベクター回帰(Supportvectorregression)
以上がSVMを分類に使った場合の説明です。そして、SVMは回帰にも使うことができ、それがサポートベクター回帰(SVR)になります。これは、図6のように今度は川の内側にデータがあります。リッジ回帰やロッソ回帰と同じく、誤差(ノイズ)対策を行って過学習を防止するわけですが、SVRはマージンの考え方を取り入れて、誤差に不感帯(川の幅)を設けることでノイズの影響を受けにくくする方法を取っています。

図6:サポートベクター回帰(SVR)
(3)ランダムフォレスト
ランダムフォレストを理解するために、まず、決定木(デシジョンツリー)を説明します。
・決定木(DecisionTree)
決定木(けっていぎ)は、もともとはその言葉通り意思決定を支援する方法です。例えば、Vol.5のシチュエーション「焼き肉に誘われたときに行くかどうかの意思決定」を決定木で書くと図7Aのようになります。
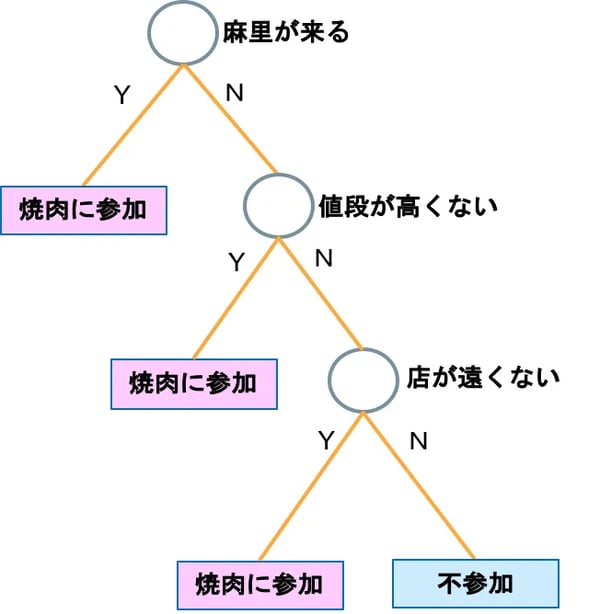
図7A:意思決定の決定木
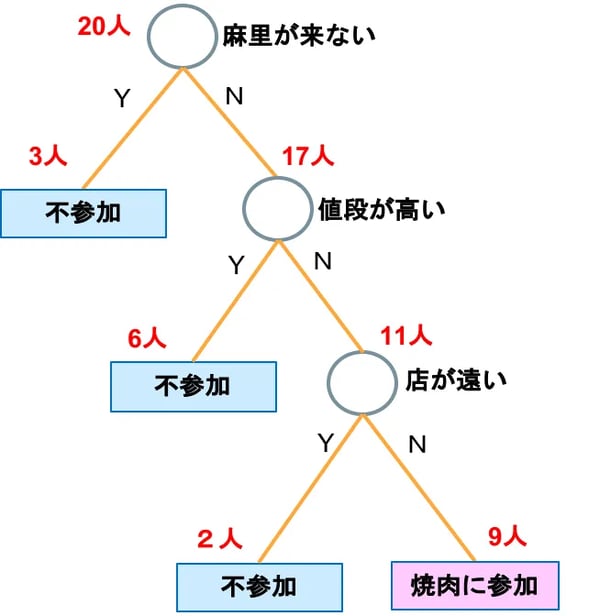
図7B:分析・分類の決定木
機械学習においては、決定木は意思決定というよりも、データを分類するための方法として用いられます。例えば、図7Bは焼き肉パーティに20人誘ったとき、条件によって何人参加するかを分析している決定木です。私にしてみれば、麻里ちゃんが来るかどうかがすべてだと思うのですが、同じ想いのライバルは3人しかおらず、価格重視の人が多いということがわかります。
このような決定木は、マーケティングなどにもよく使われます。例えば、イベントの集客で過去のデータを決定木で分析することにより、タレントを呼ぶかどうか、チケットの価格をどうするか、ロケーションをどこにするか、などの要素でどれくらい集客できるか予想が付けられるという感じです。
それはともかく、決定木って変な名前ですよね。こんな直訳したのは誰なんでしょう。おまけに重箱読みだし…。デシジョンツリーのままでいいでしょうにね。
|
SVMのように分類に使うアルゴリズムは、回帰にも使える場合があります。大谷選手のような二刀流ですね。そして、決定木にも分類木と回帰木があります(図8)。まあ、大層な違いというわけでなく、データマイニングで分類するのが分類木、過去のデータを分析して予測に使うのが回帰木です。その定義からすれば、先ほどのイベントの集客予測の例は、回帰木ということになります。 |
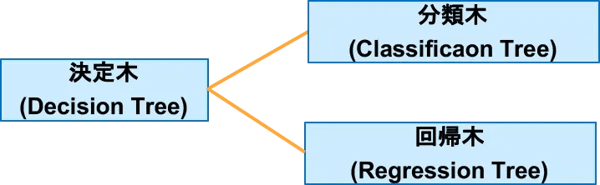
図8:分類木と回帰木
・ランダムフォレスト(randomforest)
ようやくランダムフォレストの説明に入れます。ランダムフォレストは、Vol.8で学んだアンサンブル学習です。アンサンブル学習とは、個々に学習した複数の学習器を融合させて汎化能力を高める機械学習の技術でしたね。ランダムフォレストは、次の3つのステップによりアウトプットを得ます(図9)。
①データからランダムサンプリング(バギングと言います)でn組のデータを作る。
②それぞれの決定木を作成する。
③それぞれの決定木の結果を統合する
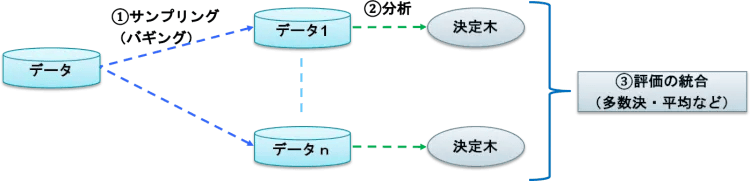
図9:ランダムフォレスト
まさにアンサンブル学習ですね。1つのデータ1つの決定木で分析するよりも、ランダムにサンプリングしたデータに対する決定木の結果を統合する方が、より精度の高い結果が得られるわけです。なお、評価の統合は、分類問題では多数決、回帰問題では平均値などが採用されます。
まとめ
今回は、「回帰」に使うアルゴリズムのうち、ベイズ線形回帰、サポートベクター回帰、ランダムフォレストという3つを説明しました。これまでに線形回帰、リッジ回帰、ラッソ回帰も簡単に紹介していますので、これで6つ覚えたことになります。
梅田弘之 株式会社システムインテグレータ :Twitter@umedano












