異常検知の全体の流れをイメージできたところで、いよいよ分類器の学習方法について解説しましょう。学習方法には表1のように「正常品のみ学習する方法」と「正常品と不良品を学習する方法」があるのですが、それによって適用するアルゴリズムも全く違うものになります。いろいろな現場で、「異常データが少ないので正常データだけでやれないか」と言われますので、まずは、正常データだけを学習する方法について解説しましょう。
| 学習方法 | モデル | 適用アルゴリズムの例 |
|---|---|---|
| 正常品のみ学習 | 生成モデル | VAE(オートエンコーダー) |
| 正常品と不良品を学習 | 識別モデル | CNN(畳み込みニューラルネットワーク) |
表1:2種類の学習方法と適用アルゴリズム

生成モデルと識別モデルは対のプロセス
まず、抑えておきたいのは生成と識別は対のプロセスということで、「洋服と型紙」「マリンバの移動」「ジオラマ製作」だということです。洋服をもとに型紙が作られ、型紙があれば洋服が作れるのと同じく、マリンバを分解して移動し、会場で組み立てて素敵な演奏を奏でるのと同じく、ジオラマの完成イメージをもとにパーツを作り、パーツを組み立ててジオラマを製作するのと同じなのです。
麻里ちゃんに「なんのこっちゃ」って怒られそうなので、もっとストレートに説明します。図1のようにコンデンサの画像の特徴点を認識して変数化できるのなら、その逆に潜在変数(n次元の特徴)から画像を生成することができるはず。これが生成モデルの基本的な考え方になります。

図1:生成モデルと識別モデルは対のプロセス

![抜粋版 人工知能基礎から機械学習まで「AIのキホン」(4,000人に配った!第三回AI業務自動化展[秋] 人気資料)](https://no-cache.hubspot.com/cta/default/2975556/7dd68aea-9b67-4b81-8e03-bd43fd7ae078.png)
潜在変数と観測変数
画像を生成する元ネタの潜在変数とはいったいなんでしょうか。これは、一言で言えば、その画像を生成するためのn次元の特徴からなるデータです。例をあげて説明しましょう。あなたが誰かに「この紙に大きく目立つ四角を描いて」と頼んだとしましょう。この一言でどんな四角が描かれるかは人によって違います。正四角形を描く人もいれば長方形を描く人もいるでしょうし、”天然”の入った麻里ちゃんだったら菱形を書くかも知れません。同じ人だとしても2回頼んだら異なる四角となるでしょう。
あなたがイメージした通りの四角を正確に書いてもらうにはどうしたらいいでしょうか。仕様を細かく伝えればできそうですね。四角という形状、縦と横の長さ、線の太さ、色、実線か破線か、などをきちんと指定すれば誰が書いても同じ四角になるでしょう。これら1つ1つが特徴であり、特徴の種類が次元です。縦の長さと横の長さで2次元で、形状(長方形)、線の太さ、色、実線という次元も加えれば全部で6次元。さらに透明度とか輝度とかも追加すれば、麻里ちゃんでも同じ画像を書いてもらえそうですね。
次に潜在変数の潜在という言葉について説明します。世の中には、直接測定できない抽象的な尺度が山のようにあります。例えば、「大きく」「目立つ」という表現は、主観的なのできちんと測ることができないのですが、このようなファクターを潜在変数と呼びます。一方、潜在変数の代わりに、測定できる値を使って潜在変数の値を特定するのを観測変数と呼びます。例えば、図2の潜在変数「大きく」は「縦の長さ」と「横の長さ」、「目立つ」は「線の太さ」「色」「実線」という測定可能な観測変数で置き換えているわけです。
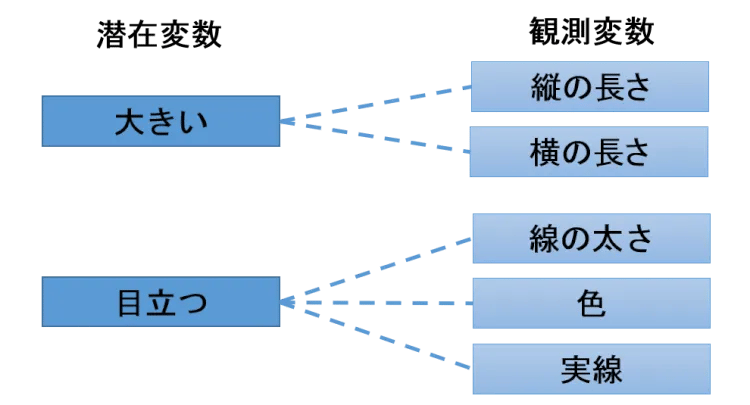
図2:潜在変数と観測変数
【麻里ちゃんのAI奮闘記】 次元の呪いと 次元削減

|
先輩:麻里ちゃん、なに読んでんの? えっ、「独り身の呪い」。なにそれ? 先輩:潜在変数だけでリンゴのイメージを生成できるには、どれくらい次元が必要だと思う? |
オートエンコーダー(VAE)を使った異常検知
生成モデルの代表的なものにオートエンコーダー(Auto Encoder)があります。これ、日本語だと自己符号化器というレトロな香りの名前です。第一印象でかたっ苦しいと感じた言葉ですが、よく見るとenという「~にする」という意味の接頭辞にcoder(符号化)にくっついているのを直訳しているだけでした。和訳はイマイチですが、これが”正常データだけ学習する”異常検知システムで役に立つのです。図3を使って仕組みを説明しましょう。
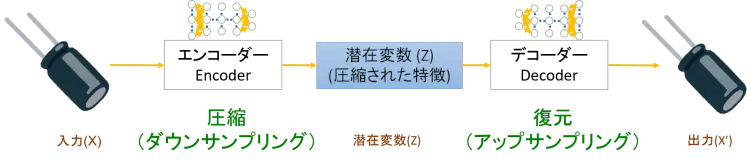
図3:オードエンコーダー(Auto Encoder)
(1)オートエンコーダーの目的
オートエンコーダーは、データを圧縮して潜在変数にするエンコーダー(Encoder)と、それをデータに復元するデコーダー(Decoder)が対になっています。この仕組みは、ファイルをZipファイルなどに圧縮(エンコード)して、それを再び解凍(デコード)するファイル圧縮ソフトをイメージしてもらえればわかりやすいと思います。
zipなどの圧縮は、ファイルサイズを小さくしてメール送信時の通信負荷を下げたり、格納するディスク容量を節約する目的で使われています。では、機械学習におけるオートエンコーダーはどのような目的のために存在しているのでしょうか。
もともとの目的はzipがファイル容量を小さくするのと同じで、次元削減(Dimensionalty Reduction)するためです。図3のエンコーダー(ダウンサンプリング)部分をご覧ください。入力データ(X)の情報が大き過ぎると人工知能が計算処理するのが難しくなるので、特徴を失わない範囲で次元削減をした潜在変数(Z)を得るためにオートエンコーダーが利用されました。人工知能が入力データを扱うのに、オリジナル(X)よりも、次元削減した潜在変数(Z)をもとに計算処理する方がずっと楽になるのです。
ところで、最近はあまりzipファイルの圧縮を使わなくなりましたね。それはWordやExcelなど最近のソフトがこうしたファイル圧縮の仕組みを標準で持つようになって、zipで圧縮してもサイズが変わらなくなったからです。実はそれと同じ理由で、この次元削減目的でのオートエンコーダー利用もめっきり減りました。CNN(畳み込みニューラルネットワーク)やRNN(リカレントニューラルネットワーク)など、最近の人工知能アルゴリズムの中に次元削減処理が含まれるようになっているので、事前処理としてオートエンコーダーを使うような機会がなくなってきたのです。捨てる神あれば拾う神あり、代わって注目されているのが正常データだけを学習する異常検知モデルへの適用です。
(2)オートエンコーダー(VAE)の学習
オートエンコーダーは、どういう仕組みで入力データから潜在変数を求めるのでしょうか。代表的なオートエンコーダーのVAE(Variational Autoencoder)をモデルにして簡単に説明しましょう。 VAEはDCGANと同じく潜在変数を取得するのに確率分布を使っています。図4の学習プロセスをご覧ください。エンコーダー君は入力(X)の特徴を圧縮してn次元のガウス分布の平均μと分散σを出力し、その2つをもとにして潜在変数(Z)をサンプリングで求めます。
デコーダー君は、潜在変数(Z)をもとに出力(X')を生成するわけですが、入力(X)と出力(X')との間に復元誤差(Reconstraction Error)が生じます。例えば入力(X)のデータを200枚用意して何回も学習させながら、この復元誤差(Reconstraction Error)を少なくするようにエンコーダーとデコーダーそれぞれの重みを調整します。いい感じに復元できるようになったとき、エンコーダー君は与えられた入力データから最適な潜在変数(凝縮された特徴)を認識できるようになっており、デコーダー君は潜在変数を与えられれば学習したやつとそっくりの画像を生成できるようになっているわけです。
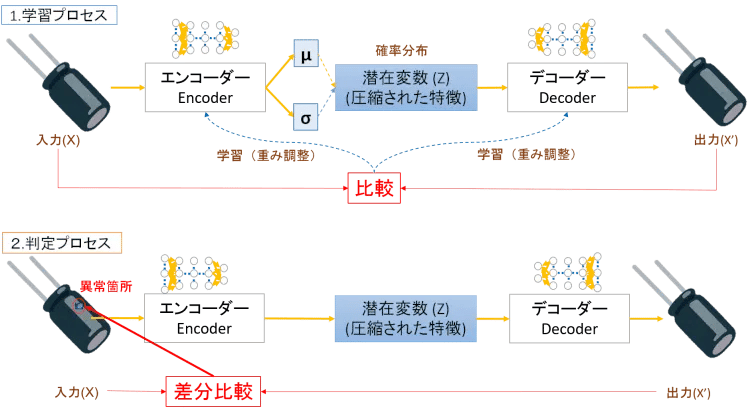
図4:VAEの学習と判定
(3)オートエンコーダー(VAE)による異常検知
さて、生成モデルとされるVAEを使って異常検知するってどういうことなのでしょうか。ポイントは、VAEは「習っていないやつは復元できない」って中坊のような正論を言うってことです。
図4の判定プロセスに登場するエンコーダー君とデコーダー君は、学習プロセスで200枚の正常品を学習した優等生です。コンベアに流れてくる製品が正常品だったら、エンコーダー君は適切に潜在変数(Z)に変換し、デコーダー君はそれを見事に復元できます。
そこに不良品が流れて来ましたらどうなるでしょうか。エンコーダー君とデコーダー君は優等生にありがちながり勉タイプなので、勉強した以外のことには弱いのです。なので、不良品(X)にあった傷などの異常については復元できず、デコーダーが生成した出力(X)は傷のない画像になってしまいます。
ところで、2つのファイルを比較するDiffと呼ばれるソフトを知っていますか。いろいろな種類があって、テキストの差分比較だけでなくPDFや画像の比較を行えるものも公開されています。こうしたDiffを使って入力(X)と出力(X')を比較したらどうなるでしょうか。
正常品の場合は入力(X)と出力(X')が同じなので差分無しの真っ黒になります。一方、不良品の場合は傷の部分だけが不一致となり図5のように差が抽出できます。この座標をもとにヒートマップ(赤丸)を付ければ、一目でどこにどんな異常が発見されたかわかるわけです。
VAEはAE(オートエンコーダー)の一つなのですが、通常のAEと比較して優れている点は、「未学習部分の特徴を再現しない」という点です。通常のAEはあくまで学習した次元の削減方法を学んでいるだけなので、未学習部分に対してどのように振る舞うか保証できません。つまり、図4の判定プロセスにおいてAEは異常も含めて復元する場合がありますが、VAEは「おら、習ってないのは復元しないよ」と言い張る中坊なので逆に異常検知に使い易いのです。 |

図5:Diffによる不一致抽出
[RELATED_POSTS]
まとめ
生成モデルを使った「正常品だけを学習する異常検知」の仕組み、理解できましたでしょうか。今回は生成モデルとしてVAEを使いましたが、畳み込みNNを使ったコンボリューショナルオートエンコーダー、GAN(敵対性生成ネットワーク)の一種のACGAN、VAEとGANを組み合わせたVAEGANなどなど、実にさまざまな生成モデルがあります。今、生成モデルは急速に進化中で、良さそうなものを試して比較しているうちに、また新たなものが出てくるって感じです。AIに麻里ちゃんそっくりさんを生成させて、あんなことこんなことをさせるような怪しいサービスも出てきそうでちょっと未来が怖くもあります。
梅田弘之 株式会社システムインテグレータ :Twitter @umedano















