画像認識AIシリーズ【中級者編】のVol. 3です。前回は画像認識の中でも最もポピュラーな画像分類について解説しました。ここまでで、AI(ディープラーニング)による画像認識がどのように行われているか理解できたと思います。しかし、何かモヤモヤ感がありませんか。
「AIで画像を認識する仕組みはわかったけど、認識精度は100%じゃないんだ?」、「実際のAI製造現場で認識精度を上げるためにどんなことをやっているの?」といった疑問が浮かぶかもしれません。
そこで今回は、実際に画像認識AIを製造現場で使用するときの認識精度をUPさせるテクニックについて解説します。テクニックの解説前にそもそも認識精度が上がらない原因は何かについてお話しします。

画像認識AI「認識精度が上がらない」製造現場あるある
1.画像が少量しか手に入らない
これから画像認識AIをビジネスに活用したいと考えている企業で、「手元に十分な量の画像がある、早速画像認識に利用しよう」となるケースは稀です。なぜなら、検討段階で画像が1枚もなかったり、あったとしてもサンプル程度でAIでの認識には使えないケースがほとんどだからです。そういった場合には、1から学習用の画像を大量に用意するのはコストもかかり、あまり現実的ではありません。
また画像分類では、画像の種類によって入手できる枚数が偏ってしまうことがよくあります。例えば、異常検知の場合、異常品画像が必要であるにもかかわらず異常の発生頻度が高くないため異常品画像の入手は難しく、手元にある正常品画像との量に大きな差が生じてしまうことがよくあります。
こちらの記事で「学習用画像の枚数は多ければ多いほど良い」と述べた通り、限られた枚数の画像で学習する場合は期待通りに精度が出せないことがあり得ます。

2.AIを稼働させるハードウェアの性能が限られている
AIに高度な処理を行わせようとすると、大量の画像処理やデータ計算を行う必要があり、それだけ高性能なコンピューターが必要となります。より高機能で高性能なモデルを作ろうとすると、大量で多様なデータを使って学習させた結果、大規模なモデルができあがることになります。
モデルの規模とは、画像の特徴に対しどれだけ複雑、仔細な情報(犬猫分類の例ならば耳や尻尾の形など。実際はコンピューターで処理可能な、もっと複雑な情報)で処理できるかによって決まるものです。例として、100個の情報で画像を判断するのと1万個の情報で判断するのでは、考える量が異なるためモデルの規模、ひいては計算量が変わります。
したがって、大規模な学習モデルを使うには本番環境で使用するデバイスのスペックが十分でないと、せっかくいい性能のAIができたにもかかわらずハイパフォーマンスを発揮できない場合があります。例えば、”画像認識AIモデルをスマートフォンで動かす”、”移動型ロボットに搭載する”などの場合は、 AIモデルを稼働させるデバイスが小型であり、スペックに制約があります。ただし、画像認識AIを実用稼働させるのに十分な高性能をハードウェアだけで実現しようとすると、非常に高額な投資が必要となってしまいます。

このように、画像認識AIを利用しようと検討している製造現場では、少量の画像しか手に入らず、ハードウェアの性能も限られているという課題があります。そこで、実際に利用する場合には、こういった不十分な条件を解消し認識精度を上げる工夫を行う必要があります。次の章では、AI認識精度を上げるためのちょっと魔法のようなテクニックを3つ紹介します。
AI認識精度を上げるための3つのテクニック
手元の画像を増やす “データの水増し”
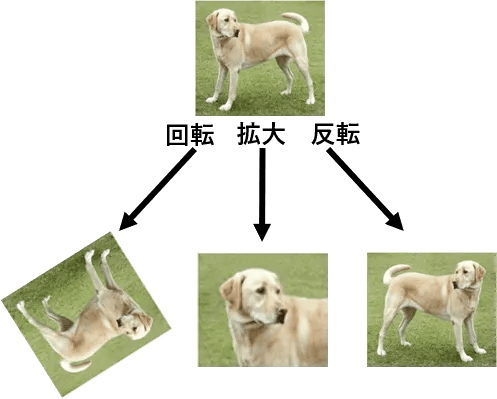
前章では、AIの認識精度が上がらない1つ目の原因として、少量の画像データしか手に入らないことを述べました。しかし、これを解決するのはある意味簡単です。手に入った少量の画像からさらに画像を作り出せば良いのです。画像を作り出すとはどのような意味か以下の図で説明します。

![抜粋版 人工知能基礎から機械学習まで「AIのキホン」(4,000人に配った!第三回AI業務自動化展[秋] 人気資料)](https://no-cache.hubspot.com/cta/default/2975556/7dd68aea-9b67-4b81-8e03-bd43fd7ae078.png)
図のように手元の画像に回転、拡縮、変形、反転、平行移動などの加工をすることで、特徴を残したまま異なった構図の画像を作り出せます。これを専門的には“データの水増し“と言い、比較的簡単に手元の画像データを何倍にも増やすことができます。
他分野の学習結果を転用 “転移学習”
データの水増しは手元の画像データが少ない場合に精度を上げる有効な手法ですが、同じ画像データを流用しているため似たような構図の画像が増えるだけで、その効果には限界があります。AIの学習によって汎用的かつ安定した性能を得るにはやはり元の画像データ数を増やすしかありません。「それが出来たら苦労しないよ」と聞こえてきそうですが、安心してください!元の画像データを増やすよりも簡単な方法があります。それがここで紹介する“転移学習”です。
転移学習とは、ある領域で学習した内容を別の領域に役立たせ、効率的に学習させる方法です。つまり、犬と猫の画像認識から分類しようとしているときに、全く関係のない自動車の画像データを使って学習した結果を借りて、今行おうとしている犬と猫の分類に転用することです。
世の中には大量の画像データが存在し一般に公開されているのもの多くあります。それらを使って学習したモデルの知識を利用できれば、AIの認識精度を高めることができます。実際に、公開されている大量の画像データを使って学習した“学習済みモデル”自体も公開されていることがあります。こういったモデルを自ら作るのは大変な手間と時間がかかりますが、転移学習を使えば短時間で自分の期待する学習モデルを作成できるかもしれません。
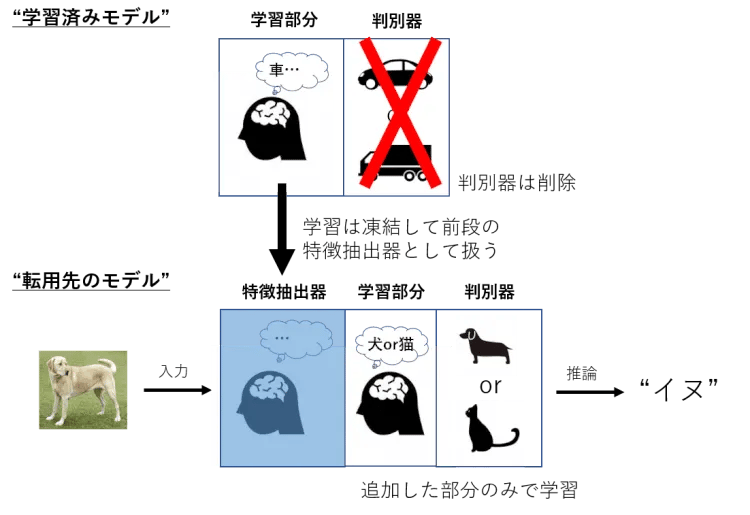
下の図を見てください。大量の自動車の画像を学習したモデルがあり、これを犬と猫の分類に用いる例です。通常画像分類のモデルは、画像から特徴を抽出する部分(学習部分)と、その特徴から種類を分類する部分(判別器)で構成されているイメージです。
転移学習の最大の特徴は、学習の済んだモデル(下図の学習済みモデル)の判別器の部分を削除し、学習状態を凍結して単なる特徴抽出器として用いることです。学習状態を凍結すると、車の画像を大量に学習することで得た様々な情報をそのまま保存(犬と猫の画像で改めて学習はしない≒凍結)し、別の画像においても多くの特徴を抽出する特徴抽出器として扱うことができるのです。
学習済みモデルは、大量の画像で学習が進んだ状態なので、汎用的な知識が身に付き、画像中の顕著な特徴を見つけられるようになっています。この知識に現在のタスクに適した学習部分と判別器を取りつけることで、簡単に高性能なモデルを組み立てることができます。
大規模なモデルを圧縮 “蒸留”
AI認識精度が上がらない2つ目の原因として、AIを稼働させるハードウェア性能が限られていることを述べました。なぜなら、性能の高い大規模なAIモデルを実装するには、大量の処理スペックが必要だからです。「こればっかりは、性能やコストの妥協点を見つけるしかないのでは?」と思われるでしょうが、その前に有効な対策があります。ここで紹介するのは、高性能な大規模AIモデルを、性能そのままに小さく圧縮してしまおうという技術のひとつ、“蒸留”です。
「AIモデルの圧縮ってそもそも何?そんなことができるなら初めから言ってよ」と思われるかもしれません。確かに圧縮は可能ですが、普段皆さんがコンピューター上で大きなファイルを小さく圧縮するようなイメージとは違い、蒸留によるAIモデルの圧縮はそう簡単ではありません。
蒸留を理解するには、教師モデル(圧縮前)と生徒モデル(圧縮後)の関係を理解する必要があります。教師モデルとは、圧縮したい高性能な大規模AIモデルです。一方生徒モデルとは、教師モデルから知識を継承した教師モデルよりもサイズの小さなモデルのことです。知識を継承するとはどういうことか、以下の図を使って説明します。
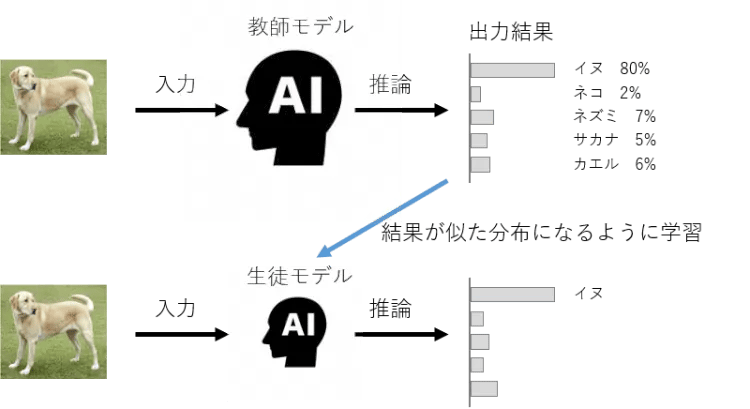
これは教師モデルの出力の例です。今回は動物5種類の分類を例にしました。1枚の画像が入力された時に、教師モデルは5種類の動物のうちどの確率が一番高いかで判断結果を返します。犬の画像が入力されていますので、犬の確率が高く、そのほかは数%前後で分布しています。そして、知識を継承するとは、この教師モデルの出力分布を軽量な生徒モデルで再現するように調整しながら学習を行うことです。
ざっくりとしたイメージで言えば、いろんな知識を持っている教師モデルから、生徒モデルは必要な知識だけ教わって真似るように学習することで、問題を解くことができるようになるのです。このようにして、大規模な教師モデルから、知識を継承された軽量な生徒モデルへと圧縮することが可能になります。
その精度は本当に正しい?判断根拠の可視化
精度が高くても、認識は間違っている “落とし穴”
画像認識AIモデルができたら、テスト用画像による精度検証を行います。結果で出た数値を見ると、期待していた精度が出たので完成としたいところです。しかし、喜ぶのはまだ早いです。なぜなら、画像認識の場合は数値だけを見て性能を判断することは非常に危険な行為だからです。
仮にあるAIモデルが90%という確率で犬と猫の分類を行った場合、非常に高い精度での分類が行えたことになります。このように精度が高いとは言え、AIの認識(ここがこうだから犬という判断)が正しかったかどうか、実は人間にはわかりません。ある意味、4択の試験問題で運良く勘で当たってしまったような場合もあるからです。
AIは画像全体から得られる特徴を利用して分類を行っているに過ぎず、画像の中の犬と猫だけを認識して分類しているわけではないからです。例えば、家の中にいる猫の画像データを多く学習し、外を走り回る犬の画像データを学習している場合、たまたま草原にいる犬の画像で「犬」と判断したかもしれません。要するに、家の中にいる猫と外にいる犬という誤った学習がされているケースもあり得るのです。
ディープラーニングは判断の根拠を示すことが苦手
AIの出力からは、なぜ犬と判定したのか、猫と判定したのか、その根拠はわかりません。犬らしい特徴(垂れた耳と尻尾)を捉えたのか、犬らしくない特徴(曲がった背中)があったのか、それとも全く関係のない特徴(餌を食べる容器)が根拠なのかはっきりしません。判断の根拠を示すことは人間にとって当たり前のことですがAIには非常に苦手なことなのです。
AIに求められるのは犬と猫をより間違いなく判別することであり、その過程は人間にとってブラックボックスとなっています。この問題はAI技術出現当初から長く議論されており、その解明のために日本語では“説明可能なAI”という言葉で研究が進められています。
判断根拠を可視化する手段 “ヒートマップ”
「AIが判断根拠を示せないなら、正しい評価はできないね」と思われたでしょうか。おっしゃる通り説明可能なAIはすぐには解決できない大きな課題です。しかし、ブラックボックスであるAIを少しでも紐解くために、画像中で判断に用いたとされる特徴部分をヒートマップによって可視化する手法があります。
以下はヒートマップ手法の論文から抜粋した画像です。上段は、犬と猫が両方写っている画像からAIが猫の特徴として捉えている部分に色を付けています。下段は犬について同様に色を付けています。このように、AIが画像のどの部分を特徴と認識して分類しているのか、人間の目で見てわかりやすく可視化してくれます。
 画像元:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
画像元:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
ただし、可視化したとしても、AIが「この部分を特徴として認識したよ」と言っているだけで、「耳が垂れていて目と鼻の位置が・・」などという判断根拠を示してくれるわけではありません。そうなると可視化されたとしても、その判断が絶対に正しいとは言い切れません。しかし、「このAIは犬と猫の特徴をちゃんと捉えていそうだな」と推測することは可能です。他にも、こういった判断根拠を示すような研究は日々進められています。
認識精度を上げる新しいアプローチ
最新研究論文から新しいアプローチを探る
画像認識AIの研究者たちは、日々最高の認識精度を追求し競い合っています。一般的な技術領域では研究段階から実用化に至るまでに数年以上かかるケースが多いですが、AIの場合はそうとも限りません。AIの研究者たちは論文の発表とともにその実装プログラムを公開し、世界中のAI開発者たちがすぐにそれをビジネスに持ち込みます。研究と実用化のサイクルが非常に速いため、AI開発者たちは常に最新の研究をキャッチアップすることが求められます。
例えば、転移学習の元となる学習済みAIモデルは頻繁に性能がアップデートされ、またその種類も増えています。他にも、蒸留以外のモデル圧縮手法やハードウェアの進化によっても認識精度の向上が期待できます。
こういった研究動向から新しいアプローチを探求し常にキャッチアップすることで、いち早くビジネスに取り込むことが出来るのです。















